GGML به Hugging Face میپیوندد: این برای بهینهسازی مدل محلی چه معنایی دارد؟


زیرساخت عامل محلی به تازگی یک درِ واحد دریافت کرده است. گئورگی گرگانوف، خالق کتابخانه تانسور ggml و نیروی محرکه llama.cpp، به همراه تیم GGML.ai خود به Hugging Face پیوسته است. این اقدام، پرکاربردترین موتور استنتاج محلی را مستقیماً در بزرگترین مرکز مدل در اکوسیستم هوش مصنوعی متنباز قرار میدهد. برای توسعهدهندگانی که کشف مدل در Hugging Face را با استقرار محلی از طریق llama.cpp به عنوان دو مرحله اساساً جداگانه به هم متصل میکردند، این ادغام آن شکاف را به یک خط لوله واحد از جستجو تا استنتاج تبدیل میکند.
فهرست مطالب
چه اتفاقی افتاد: توضیح ادغام GGML-Hugging Face
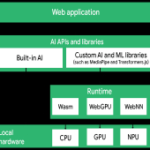
کلم دلانگو، مدیرعامل Hugging Face، از خرید GGML.ai خبر داد و گئورگی گرگانوف و تیمش را زیر چتر Hugging Face آورد. ارزش دارد که به طور مفصل به دامنهی آنچه GGML.ai در بر میگیرد، اشاره کنیم: این پروژه شامل کتابخانهی تانسور C مربوط به ggml (پشتیبان محاسبات سطح پایین)، llama.cpp (زمان اجرای استنتاج که توسط میلیونها توسعهدهنده برای اجرای مدلهای زبانی بزرگ روی سختافزارهای مصرفی استفاده میشود)، whisper.cpp (معادل تبدیل گفتار به متن) و فرمت مدل GGUF که به استاندارد بالفعل برای مدلهای محلی کوانتیزه تبدیل شده است، میشود.
نکته مهم این است که همه چیز متنباز باقی میماند. مخازن llama.cpp و ggml تحت مجوزهای موجود MIT خود به فعالیت خود ادامه میدهند. آنچه تغییر میکند، سازمانی است: تیم اکنون منابع Hugging Face را در اختیار دارد و Hugging Face نفوذ مستقیمی بر نقشه راه مهمترین پشته استنتاج محلی در اکوسیستم پیدا میکند. گرگانوف اظهار داشته است که ماموریت همچنان پابرجاست: کارآمد و در دسترس قرار دادن استنتاج هوش مصنوعی بر روی سختافزارهای رایج.
همه چیز متنباز باقی میماند. مخازن llama.cpp و ggml تحت مجوزهای MIT موجود خود به کار خود ادامه میدهند.
چرا این موضوع برای زیرساخت مدل محلی اهمیت دارد؟
مشکل چندپارگی قبل از ادغام
هر کسی که یک LLM محلی را مستقر کرده باشد، میداند که گردش کار از هم گسیخته است. توسعهدهندگان مدلهایی را در Hugging Face Hub کشف میکنند. اما رسیدن از یک ایست بازرسی safetensors به یک سرور استنتاج محلی در حال اجرا شامل زنجیرهای از مراحل غیرمرتبط است: یافتن یک کوانتیزاسیون GGUF آپلود شده توسط جامعه (اغلب از کوانتایزرهای مستقل و پرکار جامعه مانند TheBloke یا bartowski)، تأیید مطابقت آن با نسخه معماری مورد انتظار شما، دانلود آن از طریق یک مکانیسم جداگانه و در نهایت بارگذاری آن در llama.cpp.
نقاط درد پیچیدهتر میشوند. مدلهای کوانتیزه شده توسط جامعه گاهی اوقات چند روز یا چند هفته از نسخههای بالادستی عقب میمانند. عدم تطابق نسخه بین ابزارهای کوانتیزه کردن و زمان اجرای llama.cpp باعث خرابیهای خاموش یا افت کیفیت میشود. توسعهدهندگانی که بر اساس مدلهای سفارشی و دقیق کار میکنند، با مسیری حتی دشوارتر روبرو میشوند، زیرا هیچ کوانتیزه کننده جامعهای، نقاط بررسی خصوصی آنها را مدیریت نمیکند. نتیجه، یک خط لوله شکننده است که توسط دانش قبیلهای و موضوعات مربوط به GitHub به هم متصل شده است.
یک خط لوله به جای چهار مرحله
با حضور تیم GGML در Hugging Face، مسیر پیش رو، کوانتیزاسیونهای GGUF شخص ثالث است که مستقیماً در Hugging Face Hub میزبانی میشوند. نگهدارندگان مشخصات قالب، آنها را تولید میکنند. این به معنای آزمایش فایلهای مدل کوانتیزه شده بر روی همان CI است که llama.cpp را میسازد، با فراداده و منشأ مناسب.
اگر Hugging Face فرادادههای تشخیص سختافزار را در مخازن GGUF افشا کند، وضوح مدل کتابخانه transformers میتواند مستقیماً به backendهای استنتاج ggml هدایت شود. برای توسعهدهندگانی که زیرساخت عامل محلی را میسازند، تصویر ساده میشود: کشف مدل، کوانتیزاسیون و استقرار، یک خط لوله، یک سیستم احراز هویت و یک مجموعه ابزار را به اشتراک میگذارند. گردشهای کاری استقرار لبه و روی دستگاه مستقیماً سود میبرند، زیرا اصطکاک تبدیل و اعتبارسنجی مدلها به یک فرمان واحد کاهش مییابد.
کشف مدل، کوانتیزاسیون و استقرار آن، یک خط لوله، یک سیستم احراز هویت و یک مجموعه ابزار را به اشتراک میگذارند.
راهنمای عملی: بهینهسازی مدلهای محلی در اکوسیستم جدید
راهاندازی محیط شما
این ابزار به یک فایل llama.cpp که به یک برچسب انتشار خاص پین شده باشد (برای مشاهده آخرین برچسب پایدار به صفحه انتشارها مراجعه کنید)، کتابخانه پایتون huggingface_hub و پایتون ۳.۱۰ یا جدیدتر نیاز دارد.
python -m venv .venv source .venv/bin/activate
pip install --upgrade huggingface_hub
huggingface-cli login
git clone --branch b3670 --depth 1 https://github.com/ggerganov/llama.cpp.git cd llama.cpp
NPROC = $( nproc 2 > /dev/null || sysctl -n hw.logicalcpu 2 > /dev/null || echo 4 )
if command -v nvcc &> /dev/null ; then cmake -B build -DCMAKE_BUILD_TYPE = Release -DGGML_CUDA = ON else echo "[INFO] nvcc not found — building CPU-only" cmake -B build -DCMAKE_BUILD_TYPE = Release fi
cmake --build build -j " ${NPROC} "
./build/bin/llama-cli --version
cd ..دریافت مستقیم مدلهای GGUF از Hugging Face Hub
کتابخانه پایتون huggingface_hub امکان دانلود برنامهریزیشده فایلهای GGUF خاص را فراهم میکند. هنگام مرور مخازن مدل، به دنبال مخازنی باشید که توسط سازنده مدل یا توسط خود Hugging Face نگهداری میشوند. کوانتیزاسیونهای رسمی GGUF به طور فزایندهای به عنوان مصنوعات شخص ثالث به جای بارگذاری مجدد توسط جامعه ظاهر میشوند.
انتخاب سطح کوانتیزاسیون به محدودیتهای سختافزاری بستگی دارد. Q4_K_M تقریباً 0.1 تا 0.3 PPL از پیچیدگی را با حدود 40٪ رم کمتر نسبت به Q8_0 معامله میکند، و آن را به انتخاب پیشفرض برای اکثر پردازندههای گرافیکی مصرفی و دستگاههای اپل سیلیکون تبدیل میکند. Q5_K_M با تقریباً 15 تا 20٪ حافظه بیشتر نسبت به Q4_K_M، افزایش کیفیت متوسطی را ارائه میدهد. Q8_0 در حدود 0.1 PPL از F16 باقی میماند اما به رم قابل توجهی بیشتری نیاز دارد.
import os import sys from huggingface_hub import hf_hub_download , list_repo_files from huggingface_hub . utils import RepositoryNotFoundError , EntryNotFoundError
model_repo = "bartowski/Meta-Llama-3.1-8B-Instruct-GGUF" gguf_filename = "Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf"
_default_dir = os . path . join ( os . path . expanduser ( "~" ) , "models" , "llama-3.1-8b" ) local_dir = os . environ . get ( "MODEL_DIR" , _default_dir )
try :
all_files = list ( list_repo_files ( model_repo ) ) except RepositoryNotFoundError : sys . exit ( f"[ERROR] Repository not found: { model_repo } " )
gguf_files = [ f for f in all_files if f . endswith ( ".gguf" ) ] print ( "Available quantizations:" ) for f in gguf_files : print ( f" { f } " )
if gguf_filename not in gguf_files : sys . exit ( f"[ERROR] ' { gguf_filename } ' not found in { model_repo } . " f"Available: { gguf_files } " )
try : downloaded_path = hf_hub_download ( repo_id = model_repo , filename = gguf_filename , local_dir = local_dir , ) except EntryNotFoundError : sys . exit ( f"[ERROR] File not found on hub: { gguf_filename } " ) except Exception as e : sys . exit ( f"[ERROR] Download failed: { e } " )
file_size_gb = os . path . getsize ( downloaded_path ) / ( 1024 ** 3 ) print ( f"Model downloaded to: { downloaded_path } ( { file_size_gb : .2f } GB)" )کوانتیزه کردن مدلهای خودتان به GGUF
مدلهای سفارشی تنظیمشده یا معماریهای تازه منتشرشده اغلب فاقد فایلهای GGUF از پیش ساختهشده هستند. فرآیند تبدیل از دو مرحله عبور میکند: تبدیل چکپوینت Hugging Face safetensors به فرمت GGUF، سپس اعمال کوانتیزاسیون.
توجه: meta-llama/Llama-3.1-8B-Instruct یک مدل دروازهدار است. قبل از دانلود، باید توافقنامه مجوز متا را در صفحه Hugging Face مدل بپذیرید، در غیر این صورت دستور با خطای ۴۰۱/۴۰۳ اجرا نخواهد شد.
CONVERT_SCRIPT = "llama.cpp/convert_hf_to_gguf.py" if [ ! -f " ${CONVERT_SCRIPT} " ] ; then echo "[ERROR] Conversion script not found: ${CONVERT_SCRIPT} " echo "Available Python scripts: $( ls llama.cpp/*.py 2 > /dev/null ) " exit 1 fi
huggingface-cli download meta-llama/Llama-3.1-8B-Instruct \ --local-dir ./llama-3.1-8b-hf
python " ${CONVERT_SCRIPT} " ./llama-3.1-8b-hf \ --outfile llama-3.1-8b-instruct-f16.gguf \ --outtype f16
./llama.cpp/build/bin/llama-quantize \ llama-3.1-8b-instruct-f16.gguf \ llama-3.1-8b-instruct-Q4_K_M.gguf \ Q4_K_M
echo "[INFO] Output: llama-3.1-8b-instruct-Q4_K_M.gguf" ls -lh llama-3.1-8b-instruct-Q4_K_M.ggufاجرای استنتاج به صورت محلی با llama.cpp
فایل باینری llama-server یک نقطه پایانی /v1/chat/completions سازگار با OpenAI را در معرض نمایش قرار میدهد که برای اکثر موارد استفاده از چت و تکمیل مناسب است. شما همیشه باید llama-server را با یک کلید API راهاندازی کنید. مثال زیر یک کلید تصادفی برای جلسه تولید میکند. این کلید را برای استفاده در تماسهای کلاینت ذخیره کنید.
API_KEY = $( openssl rand -hex 16 ) echo "API Key: ${API_KEY} "
ulimit -l unlimited 2 > /dev/null || echo "[WARN] ulimit -l failed; --mlock may not work without CAP_IPC_LOCK"
./llama.cpp/build/bin/llama-server \ -m ~/models/llama-3.1-8b/Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \ -ngl 99 \ -c 8192 \ --mlock \ --api-key " ${API_KEY} " \ --host 127.0 .0.1 \ --port 8080
curl --fail --show-error http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer ${API_KEY} " \ -d '{"model": "llama-3.1-8b", "messages": [{"role": "user", "content": "Explain quantization in three sentences."}], "temperature": 0.7}' پرچم -ngl 99 تمام لایههای مدل را به GPU منتقل میکند. مقدار 99 از تعداد لایههای اکثر مدلها بیشتر است و به عنوان "همه چیز را منتقل میکند" عمل میکند؛ VRAM موجود، تعداد واقعی منتقل شده را محدود میکند. در سیستمهایی با VRAM محدود، این تعداد را کاهش دهید تا فقط به اندازه لایههای مناسب، منتقل شود و لایههای باقی مانده به CPU بازگردانده شوند. از nvidia-smi برای نظارت بر استفاده از VRAM و یافتن حداکثر لایههایی که بدون خطاهای کمبود حافظه جا میشوند، استفاده کنید. پرچم --mlock مدل را در RAM پین میکند و از تعویض جلوگیری میکند، که سرعت تولید توکن را در دستگاههای دارای محدودیت حافظه تثبیت میکند. در لینوکس، --mlock به ulimit -l unlimited در جلسه پوسته شما یا قابلیت CAP_IPC_LOCK روی فایل باینری نیاز دارد. بدون این موارد، سرور ممکن است بیسروصدا و بدون هیچ خطایی به حافظه پین نشده بازگردد.
ملاحظات عملکرد و معیارسنجی
نگاهی اجمالی به بدهبستانهای کوانتیزاسیون
مقایسه زیر، تخمینهای تقریبی مبتنی بر معیارهای جامعه را نشان میدهد. این ارقام ممکن است بسته به نسخه llama.cpp، نسخههای درایور، طول prompt، اندازه دسته و اندازه پنجره context شما (ارقام RAM زیر یک context با توکن ۴۰۹۶ را فرض میکنند) به طور قابل توجهی متفاوت باشند. برای اندازهگیریهای دقیق، llama-bench (موجود در build llama.cpp) را در برابر سختافزار و مدل خاص خود اجرا کنید.
| کوانتیزاسیون | اندازه فایل (مدل 8B) | رم مورد نیاز | تأثیر سرگشتگی | توکن/ها (M2 Pro) | توکن/ها (RTX 4090) | توکن/ها (فقط پردازنده، ۱۶ هستهای) |
|---|---|---|---|---|---|---|
| Q4_K_M | حدود ۴.۹ گیگابایت | حدود ۷ گیگابایت | افزایش سرگشتگی (Perplexity) در حدود ۰.۱ تا ۰.۳ امتیاز در هر بازی (PPL) در مقابل F16 | ~35-45 تن در ثانیه | ۹۰-۱۲۰ تن بر ثانیه | ~۸-۱۲ تن بر ثانیه |
| Q5_K_M | حدود ۵.۷ گیگابایت | حدود ۸ گیگابایت | با حدود ۰.۰۵ امتیاز در هر نفر از F16 در WikiText-2 | ~30-38 تن در ثانیه | ~80-105 تن بر ثانیه | ~6-10 تن در ثانیه |
| سوال ۸_۰ | حدود ۸.۵ گیگابایت | حدود ۱۱ گیگابایت | افزایش کمتر از 0.1 درصدی PPL در مقایسه با F16 | ۲۲-۲۸ تن بر ثانیه | ~۶۵-۸۵ تن بر ثانیه | ۴-۷ تن بر ثانیه |
برای چت تعاملی و فراخوانی ابزار عامل، Q4_K_M به نقطه مطلوب میرسد: به اندازه کافی سریع برای پاسخهای بلادرنگ، به اندازه کافی کوچک برای قرار گرفتن در کنار سایر فرآیندها. حجم کار جاسازی دستهای و برنامههایی که به حداکثر وفاداری نیاز دارند، Q8_0 را تضمین میکنند، با فرض اینکه فضای حافظه وجود دارد. Q5_K_M بین آنها قرار میگیرد: وقتی متوجه رگرسیونهای کیفی در Q4_K_M میشوید اما نمیتوانید پرش RAM به Q8_0 را تحمل کنید، آن را انتخاب کنید.
چه باید دید: ادغامهای آینده
مهمترین ادغامی که باید به آن توجه داشت، APIهای سبک AutoModel در کتابخانه transformers است که فایلهای GGUF را برای استنتاج محلی شناسایی و بارگذاری میکنند. هنوز هیچ مشکل RFC عمومی یا ردیابی وجود ندارد، بنابراین با این موضوع به عنوان یک مشکل جهتدار و نه قریبالوقوع برخورد کنید. اگر این مشکل منتشر شود، توسعهدهندگان دیگر نیازی به جابجایی بین API پایتون transformers و سرور C++ llama.cpp بسته به هدف استقرار نخواهند داشت.
اسمولاجنتهای خودِ LangChain و Hugging Face از طریق نقاط پایانی سازگار با OpenAI از بکاندهای llama.cpp پشتیبانی میکنند. اگر Hugging Face فرادادههای با قابلیت سختافزاری را در کنار مخازن GGUF در معرض نمایش قرار دهد، این چارچوبها میتوانند به طور خودکار سطح کوانتیزاسیون مناسب را بر اساس VRAM شناسایی شده انتخاب کرده و محاسبه کنند. برای تغییرات طرحواره فراداده، به عنوان اولین سیگنال مشخص، به گزارش تغییرات huggingface_hub مراجعه کنید.
نکات کلیدی برای توسعهدهندگان
خرید GGML یک نقطه اصطکاک عمده در استقرار محلی LLM را از بین میبرد: عدم ارتباط بین محل قرارگیری مدلها و محل اجرای آنها. GGUF را به عنوان قالب استقرار محلی خود استانداردسازی کنید و به جای تکیه بر کوانتیزاسیونهای مجدد شخص ثالث، مستقیماً از Hugging Face Hub استفاده کنید.
GGUF را به عنوان قالب استقرار محلی خود استانداردسازی کنید و به جای تکیه بر کوانتیزاسیونهای مجدد شخص ثالث، مستقیماً از Hugging Face Hub دریافت کنید.
بیشتر بخوانید
یادداشتهای انتشار llama.cpp و huggingface_hub را در ماههای آینده دنبال کنید. منتظر بارگذاری transformers بومی GGUF در یک یا دو چرخه انتشار بعدی به عنوان اولین نقطه عطف ادغام باشید. از همین امروز شروع کنید: huggingface-cli download روی یک مخزن رسمی GGUF اجرا کنید، آن را به llama-server منتقل کنید و تأیید کنید که پشته عامل موجود شما هنوز کار میکند. همین یک آزمایش به شما میگوید که زنجیره ابزار شما قبل از اینکه تغییرات ادغام رخ دهد، کجا دچار مشکل میشود.
برچسبها
|
|




ارسال نظر