نحوه اجرای پرس و جوهای مشابه SQL روی فایل ها
سلام به همه! من یک مهندس نرم افزار هستم که به برنامه نویسی سطح پایین، کامپایلرها و توسعه ابزار علاقه مند هستم.
در پایان سال 2023، اولین مقاله خود را در freeCodeCamp درباره نحوه ایجاد زبانی شبیه به SQL برای اجرای پرس و جو در مخازن محلی Git منتشر کردم. اگر زمینه بیشتری می خواهید، آن را بخوانید.
در آغاز سال 2024، پروژه با آپشن های بیشتر و مشارکتکنندگان شگفتانگیز بزرگتر و بزرگتر شد، و من شروع به فکر کردن کردم: چه میشود اگر بتوانم پرسوجوهایی شبیه به SQL را نه تنها در فایلهای .git بلکه روی هر نوع داده محلی و راه دور اجرا کنم؟
در این مقاله، من شما را به سفر به روز رسانی طراحی پروژه GitQL می برم تا به عنوان یک SDK نیز استفاده شود. همچنین توضیح خواهم داد که چگونه از آن برای پیاده سازی پروژه FileQL استفاده کردم، که ابزاری برای اجرای پرس و جوی SQL مانند روی فایل های محلی است.
اولین مورد استفاده برای این ایده
اولین ایده من این بود که بتوانم از همان ویژگی های GitQL برای ساخت FileQL استفاده کنم، که ابزاری است که به شما امکان می دهد پرس و جوها را در یک سیستم فایل محلی اجرا کنید.
پس از آن، همه می توانند از پروژه GitQL به عنوان یک SDK برای ساخت XQL خود استفاده کنند. به عنوان مثال، LogQL، WeatherQL، CodeQL، AudioQL، BookQL و غیره.
چگونه شروع کردم به فکر کردن درباره GitQL SDK
سوال اول این بود: چه چیزی می تواند بین GitQL و FileQL متفاوت باشد؟ این بخش بسته به فرمت داده ها و نحوه خواندن آنها می تواند پویا باشد.
پاسخ دو جزء بود. بیایید در بخش های بعدی به آنها بپردازیم.
اولین جزء، طرحواره داده است
در هر پرس و جوی SQL مانند، باید تحلیل هایی را انجام دهیم تا مطمئن شویم همه چیز معتبر است. برای مثال، در کوئری مانند SELECT UPPER(name), commit_count + 1 FROM branches ، باید تحلیل های زیر را انجام دهیم:
تحلیل کنید که جدولی با شاخه های نام وجود دارد.
name فیلد دارای نوع متن است پس می تواند بدون هیچ مشکلی به تابع UPPER منتقل شود.
فیلد commit_count نوع عدد صحیح را دارد تا بتوانیم آن را با عملگر پلاس و یک عدد صحیح دیگر استفاده کنیم.
اگر از نام جدول، نام فیلدها و انواع آن آگاه باشیم، می توان این تحلیل ها را اجرا کرد. این اطلاعات در پروژه GitQL ثابت بود، اما اکنون، وقتی میخواهم آن را به یک SDK تبدیل کنم، باید آن را پویا کنم تا هر کاربر SDK بتواند بسته به دادههای خود آن را تغییر دهد.
پس ، من تمام اطلاعات مورد نیاز را در کامپوننتی به نام DataSchema کپسوله کردم و هنگامی که کاربر آن را به SDK ارسال کرد، همه تحلیل ها به درستی کار خواهند کرد.
جزء دوم Data Provider است
هنگامی که مؤلفه DataSchema را برای سهولت در انجام تحلیل داده ها تعریف کردیم، باید به سؤال بعدی برویم: چگونه می توانیم داده ها را در اختیار موتور GitQL قرار دهیم؟
در GitQL، ما توابع ثابتی برای ارائه داده ها از فایل های .git داریم، اما در SDK، ما فقط با فایل های .git کار نمی کنیم و باید از کار با هر نوع داده ای پشتیبانی کنیم.
پس ، ایده این است که یک رابط بین موتور GitQL و کاربر SDK تعریف کنیم تا هر نوع داده ای را در قالب مورد نیاز برای موتور ارائه دهد. این کامپوننت DataProvider نام دارد و در قسمت بعدی جزئیات پیاده سازی را توضیح خواهم داد.
طراحی و پیاده سازی GitQL SDK
هدف این است که به کاربر SDK اجازه دهیم تعریف خود را از Data Schema و Provider منتقل کند و آنها را به راحتی با سایر اجزای GitQL مانند Tokenizer، Parser، Checker، Functions و Engine یکپارچه کند.
نحوه طراحی Data Schema
طرح داده باید شامل دو نوع اطلاعات باشد. اولاً باید جداول و نام فیلدهای صحیح را تعریف کند و ثانیاً انواع داده ها را برای آن فیلدها مشخص کند.
به عنوان مثال، در مورد FileQL، نام جدول و فیلد صحیح عبارتند از:
pub static ref TABLES_FIELDS_NAMES: HashMap<&'static str, Vec<&'static str>> = { let mut map = HashMap::new(); map.insert( "files", vec!["path", "parent", "extension", "is_dir", "is_file", "size"], ); map }; در اینجا فقط یک جدول به نام files تعریف می کنیم که دارای شش فیلد path ، parent ، extension ، is_dir ، is_file و size .
در نقشه دیگر، نوع داده صحیح را برای هر فیلد تعریف می کنیم. مثلا:
pub static ref TABLES_FIELDS_TYPES: HashMap<&'static str, DataType> = { let mut map = HashMap::new(); map.insert("path", DataType::Text); map.insert("parent", DataType::Text); map.insert("extension", DataType::Text); map.insert("is_dir", DataType::Boolean); map.insert("is_file", DataType::Boolean); map.insert("size", DataType::Integer); map }; سپس، یک نمونه از Schema ایجاد می کنیم و با استفاده از دو نقشه آن را می سازیم. باید آنها را به فهرست نمونه Data Schema ارسال کند:
let schema = Schema { tables_fields_names: TABLES_FIELDS_NAMES.to_owned(), tables_fields_types: TABLES_FIELDS_TYPES.to_owned(), };نحوه طراحی ارائه دهنده داده
هدف مولفه Data Provider بارگذاری داده ها و نگاشت آنها در ساختار شی موتور GitQL است، پس می توانیم آن را به عنوان یک رابط با یک تابع تعریف کنیم:
pub trait DataProvider { fn provide( &self, env: &mut Environment, table: &str, fields_names: &[String], titles: &[String], fields_values: &[Box<dyn Expression>], ) -> GitQLObject; }کاربر SDK می تواند این رابط را برای نوع داده های خود پیاده سازی کند و آن را با داده های مختلف کار کند.
همچنین، می توانید کنترل کنید که به چه تعداد رشته نیاز دارید و چه پارامترهای اضافی را می خواهید. برای مثال، در FileQL آن را با نام FileDataProvider پیادهسازی کردم و مسیر اصلی را برای جستجو به عنوان پارامتر پاس کردم.
شما همچنین می توانید آن را به هر شکلی اجرا کنید. به عنوان مثال، APIDataprovider ، و داده ها را از سرور بارگیری کنید و آنها را در GitQLObject نقشه برداری کنید. شما همچنین می توانید به عنوان LogDataProvider و غیره پیاده سازی کنید. ایده اصلی یکسان است - فقط داده ها را در اختیار موتور قرار دهید.
نحوه استفاده از اجزای SDK با هم
پس از گفت ن جعبههای GitQL SDK به پروژه و پیکربندی Data Schema و Provider برای دادههای شما، میتوانیم از GitQL SDK استفاده کنیم:
let mut env = Environment::new(schema); let query = ...; let mut reporter = DiagnosticReporter::default(); let tokenizer_result = tokenizer::tokenize(query.to_owned()); let tokens = tokenizer_result.ok().unwrap(); if tokens.is_empty() { return; } let parser_result = parser::parse_gql(tokens, &mut env); if parser_result.is_err() { let diagnostic = parser_result.err().unwrap(); reporter.report_diagnostic(&query, *diagnostic); return; } let query_node = parser_result.ok().unwrap(); let provider: Box<dyn DataProvider> = Box::new(FileDataProvider::new(base_path.to_owned())); let evaluation_result = engine::evaluate(&mut env, &provider, query_node);کد بالا پرس و جو را به عنوان یک رشته می گیرد و آن را پردازش می کند تا نتیجه ارزیابی را از موتور دریافت کند:
یک نمونه Environment با استفاده از DataSchema برای ردیابی انواع ایجاد کنید.
یک نمونه از DiagnosticEngine ایجاد کنید تا از آن برای گزارش خطا استفاده کنید.
کوئری را به توکنایزر ارسال کنید تا رشته را به فهرست ی از نشانه ها تبدیل کند.
فهرست نشانه ها را به تجزیه کننده ارسال کنید تا آن را به TreeDataStructure تبدیل کند.
یک نمونه از DataProvider خود ایجاد کنید و آن را با درخت به موتور ارسال کنید.
موتور نتیجه ارزیابی را که یک خطا یا داده است برمی گرداند.
این کامپوننت ها به غیر از Data Schema و Provider اصلا جدید نیستند و می توانید از خواندن جزئیات طراحی و پیاده سازی در مقاله اول لذت ببرید.
این تقریباً تمام چیزی است که برای انجام پروژه نیاز دارید، اما میتوانید سفارشیسازی بیشتر و اجزای اضافی مانند آرگومانهای CLI را اضافه کنید. نتیجه نهایی به این صورت خواهد بود:
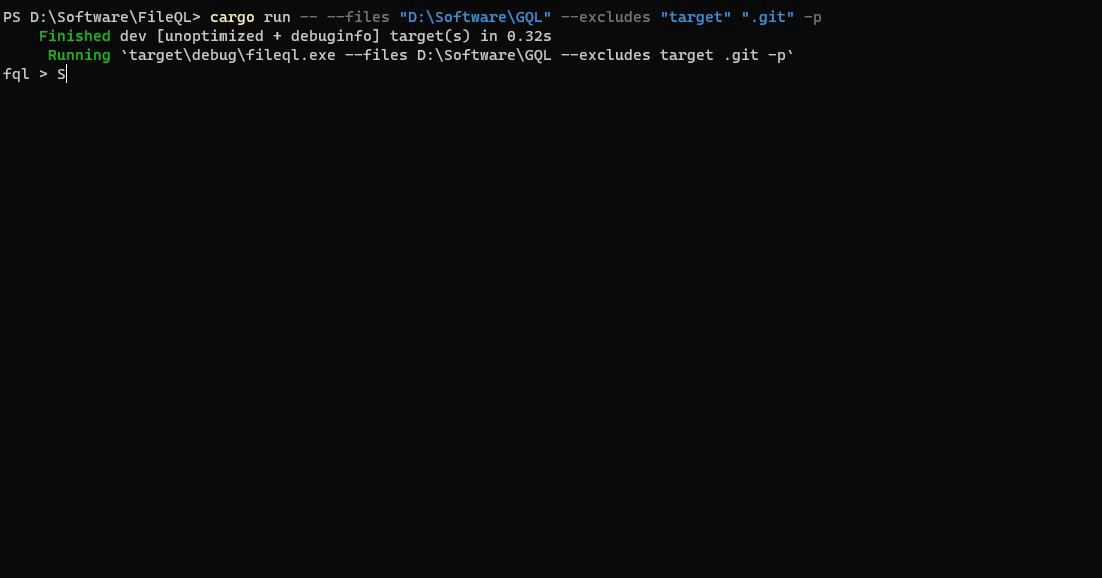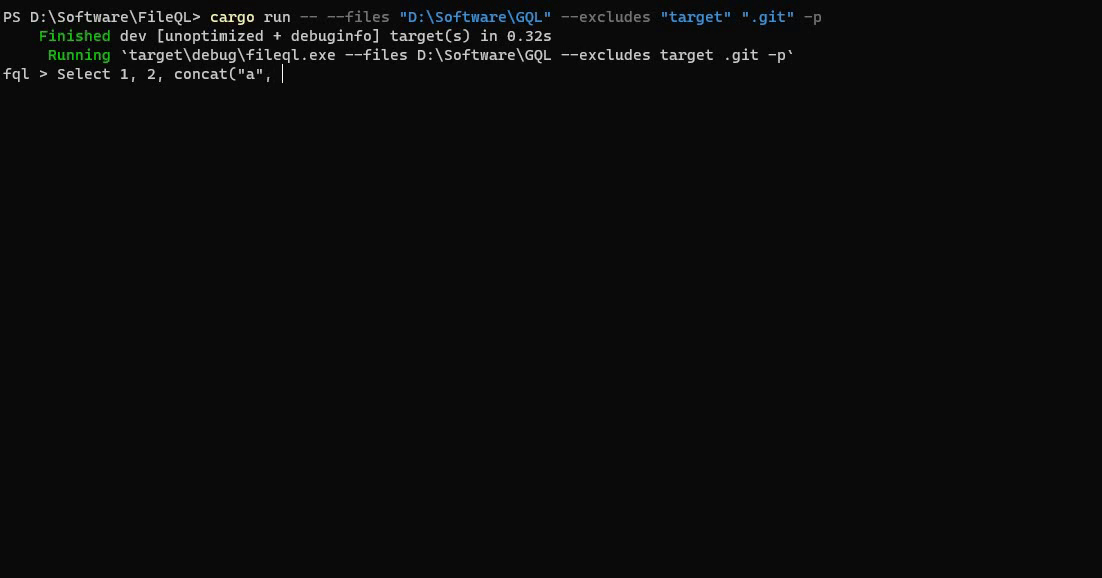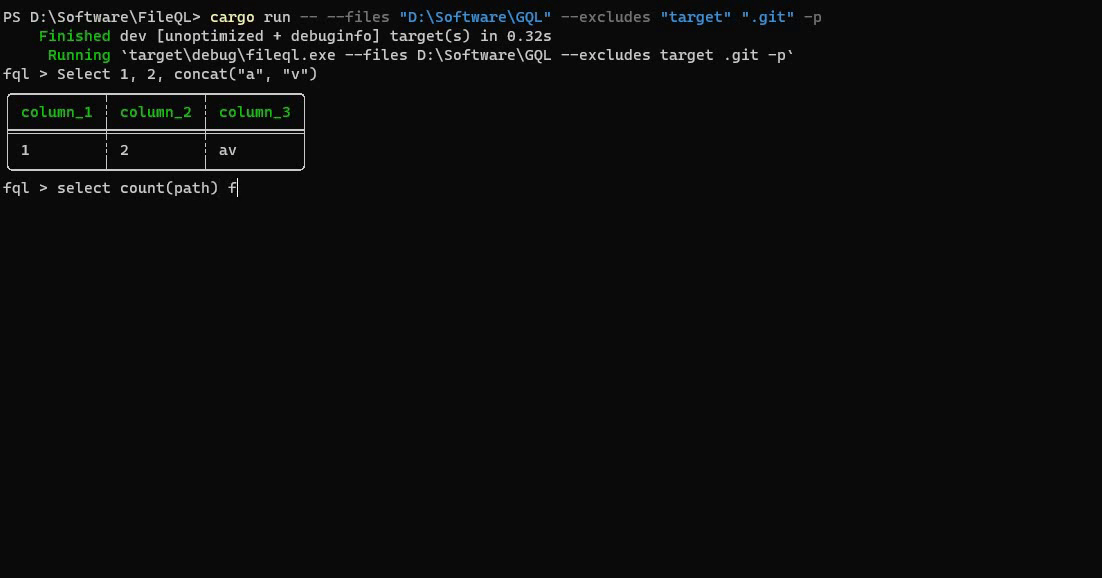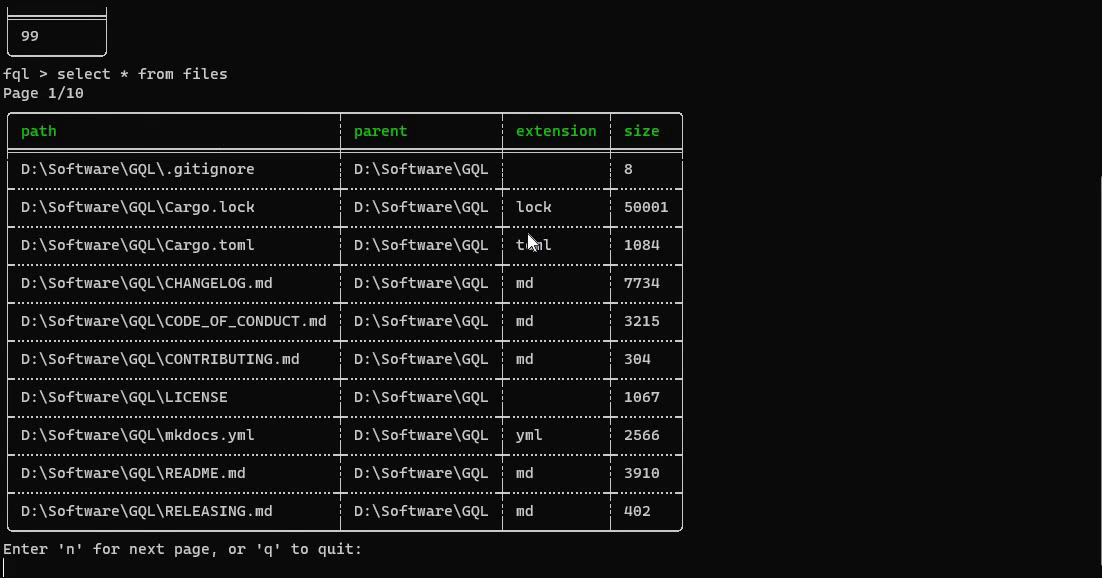
می توانید کد منبع کامل را با تمام سفارشی سازی ها در مخزن FileQL بیابید.
نتیجه
می توانید پروژه FileQL را به عنوان یک نمونه کامل که فقط در سه فایل ایجاد شده است تحلیل کنید.
اگر پروژه را دوست داشتید، می توانید به آن یک ستاره ⭐ در GitQL و FileQL بدهید
شما می توانید برای نحوه دانلود و استفاده از پروژه در سیستم عامل های مختلف وب سایت را تحلیل کنید.
این پروژه هنوز انجام نشده است - این فقط شروع است. همه می توانند به این پروژه بپیوندند و به پروژه کمک کنند و ایده هایی را پیشنهاد کنند یا اشکالات را گزارش کنند.
با تشکر برای خواندن!
برچسبها
|
|





ارسال نظر