اتمی و همزمانی در سی پلاس پلاس
Concurrency یک اصطلاح برنامه نویسی است که در صورت کدنویسی به زبان C++ باید با آن آشنا باشید. به خصوص اگر می خواهید از منابع محاسباتی موجود خود بهره بیشتری ببرید، بسیار مهم است.
اما همزمانی با مشکلات خاصی همراه است. برخی از آنها را می توان با استفاده از mutexes حل کرد، اگرچه mutexeها مجموعه ای از چالش های خاص خود را دارند.
این جایی است که اتم وارد می شود. با این حال، اتم نیاز به درک مدل حافظه یک کامپیوتر دارد که درک کامل آن موضوعی چالش برانگیز است.
این چیزی است که در این مقاله به آن خواهیم پرداخت. امیدواریم درک خوبی از نحوه کار مرتب سازی حافظه و نحوه استفاده از اتمی در ارتباط با مرتب سازی حافظه برای ایجاد یک صف بدون قفل در ++C به دست آورید.
پیش نیازها
برای استفاده حداکثری از این راهنما، باید چند برنامه اساسی همزمان را نوشته باشید. تجربه برنامه نویسی با C++ کمک می کند.
توجه: اگر می خواهید واقعاً کد را کامپایل کنید و آن را اجرا کنید، مطمئن شوید که این کار را با پرچم TSan فعال برای کامپایلر CLang انجام دهید. TSan یک روش قابل اعتماد برای تشخیص نژادهای داده در کد شما است، به جای تلاش برای اجرای مکرر کد در یک حلقه به امید وقوع مسابقه داده.
شروع شدن
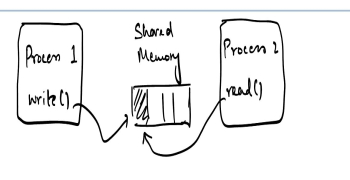
تصور کنید کدی همزمان دارید که روی برخی از داده های مشترک در حافظه کار می کند. شما دو رشته یا فرآیند دارید، یکی نوشتن و دیگری خواندن در برخی از وضعیت های مشترک.
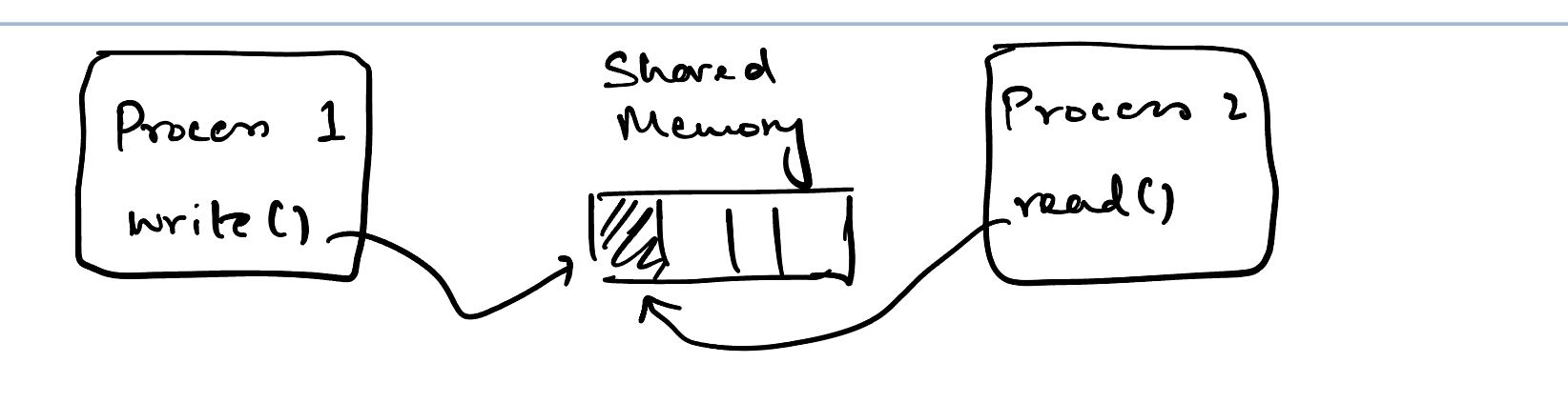
راه "ایمن" برای مقابله با این mutexes است. اما mutexes تمایل به اضافه کردن سربار دارند. اتمی ها روشی کارآمدتر اما بسیار پیچیده تر برای مقابله با عملیات همزمان هستند.
اتمی در سی پلاس پلاس چیست؟
این بخش بسیار ساده است. اتمی ها به سادگی عملیات یا دستورالعمل هایی هستند که به هیچ وجه نمی توانند توسط کامپایلر یا CPU تقسیم شوند یا دوباره مرتب شوند.
ساده ترین مثال ممکن از یک اتم در C++ یک پرچم اتمی است. به نظر می رسد این است:
#include <atomic> std::atomic<bool> flag(false); int main() { flag.store(true); assert(flag.load() == true); } ما یک بولی اتمی تعریف می کنیم، آن را مقداردهی اولیه می کنیم و سپس store روی آن فراخوانی می کنیم. این روش مقدار را روی پرچم تنظیم می کند. سپس می توانید پرچم را از حافظه load و مقدار آن را اعلام کنید.
عملیات با اتمی
عملیاتی که می توانید با اتمی انجام دهید ساده هستند:
می توانید مقداری مقدار را با متد store() در آنها ذخیره کنید. این یک عملیات نوشتن است.
می توانید مقداری از آنها را با متد load() بارگذاری کنید. این یک عملیات خواندن است.
میتوانید با استفاده از متد compare_exchange_weak() یا compare_exchange_strong() یک Compare-and-Set (CAS) با آنها انجام دهید. این یک عملیات خواندن-تغییر-نوشتن (RMW) است.
نکته مهمی که باید به خاطر داشته باشید این است که هر یک از اینها را نمی توان به دستورالعمل های جداگانه تقسیم کرد.
توجه: روش های بیشتری وجود دارد، اما این تنها چیزی است که در حال حاضر به آن نیاز داریم.
اتمی های مختلفی در C++ موجود است و می توانید از آنها در ترکیب با ترتیب حافظه استفاده کنید.
سفارش حافظه
این بخش بسیار پیچیده تر است و موضوع اصلی است. برخی از مراجع عالی برای کمک به شما در درک عمیق تر ترتیب حافظه وجود دارد که در پایین پیوند داده ام.
چرا ترتیب حافظه مهم است
کامپایلر و CPU قادرند دستورات برنامه شما را دوباره مرتب کنند، اغلب مستقل از یکدیگر. یعنی کامپایلر شما می تواند دستورات را دوباره سفارش دهد و CPU شما می تواند دوباره دستورات را سفارش دهد. برای جزئیات بیشتر این پست را ببینید.
اما این تنها در صورتی مجاز است که کامپایلر به طور قطع نتواند رابطه ای بین دو مجموعه دستورالعمل برقرار کند.
به عنوان مثال، کد زیر را می توان دوباره مرتب کرد زیرا هیچ رابطه ای بین تخصیص به x و انتساب به y وجود ندارد. یعنی کامپایلر یا CPU ممکن است ابتدا y و سپس x را اختصاص دهد. اما، این معنای معنایی برنامه شما را تغییر نمی دهد.
int x = 10; int y = 5;از سوی دیگر، مثال کد زیر را نمی توان دوباره مرتب کرد زیرا کامپایلر نمی تواند عدم وجود رابطه بین x و y را ایجاد کند. دیدن اینجا بسیار آسان است زیرا y به مقدار x بستگی دارد.
int x = 10; int y = x + 1;این مشکل بزرگی به نظر نمی رسد - تا زمانی که کد چند رشته ای وجود داشته باشد. بیایید ببینیم منظور من با یک مثال چیست.
شهود برای سفارش
#include <cassert> #include <thread> int data = 0; void producer() { data = 100; // Write data } void consumer() { assert(data == 100); } int main() { std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); return 0; }مثال چند رشته ای بالا با TSan کامپایل نمی شود زیرا زمانی که رشته 1 سعی می کند مقدار داده را تنظیم کند و رشته 2 سعی می کند مقدار داده را بخواند یک مسابقه داده واضح وجود دارد. پاسخ آسان در اینجا یک mutex برای محافظت از نوشتن و خواندن داده ها است، اما راهی برای انجام این کار با بولین اتمی وجود دارد.
بر روی Boolean اتمی حلقه می زنیم تا زمانی که متوجه شویم که مقدار مورد نظر ما تنظیم شده است و سپس مقدار data را تحلیل می کنیم.
#include <atomic> #include <cassert> #include <thread> int data = 0; std::atomic<bool> ready(false); void producer() { data = 100; ready.store(true); // Set flag } void consumer() { while (!ready.load()) ; assert(data == 100); } int main() { std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); return 0; }وقتی این را با TSan کامپایل می کنید، از هیچ شرایط مسابقه ای شکایت نمی کند. توجه: من قصد دارم به این موضوع اشاره کنم که چرا TSan در اینجا کمی بیشتر شکایت نمی کند.
حالا با اضافه کردن یک ضمانت سفارش حافظه به آن، آن را خراب می کنم. فقط ready.store(true); با ready.store(true, std::memory_order_relaxed); و while (!ready.load()) با while (!ready.load(std::memory_order_relaxed)) جایگزین کنید.
TSan شکایت خواهد کرد که یک مسابقه داده وجود دارد. اما چرا شاکی است؟
موضوع اینجاست که ما دیگر نظمی در بین عملیات دو رشته نداریم. کامپایلر یا CPU آزاد است که دستورات را در دو رشته مرتب کند. اگر به تجسم انتزاعی قبلی خود برگردیم، اکنون به این شکل است:
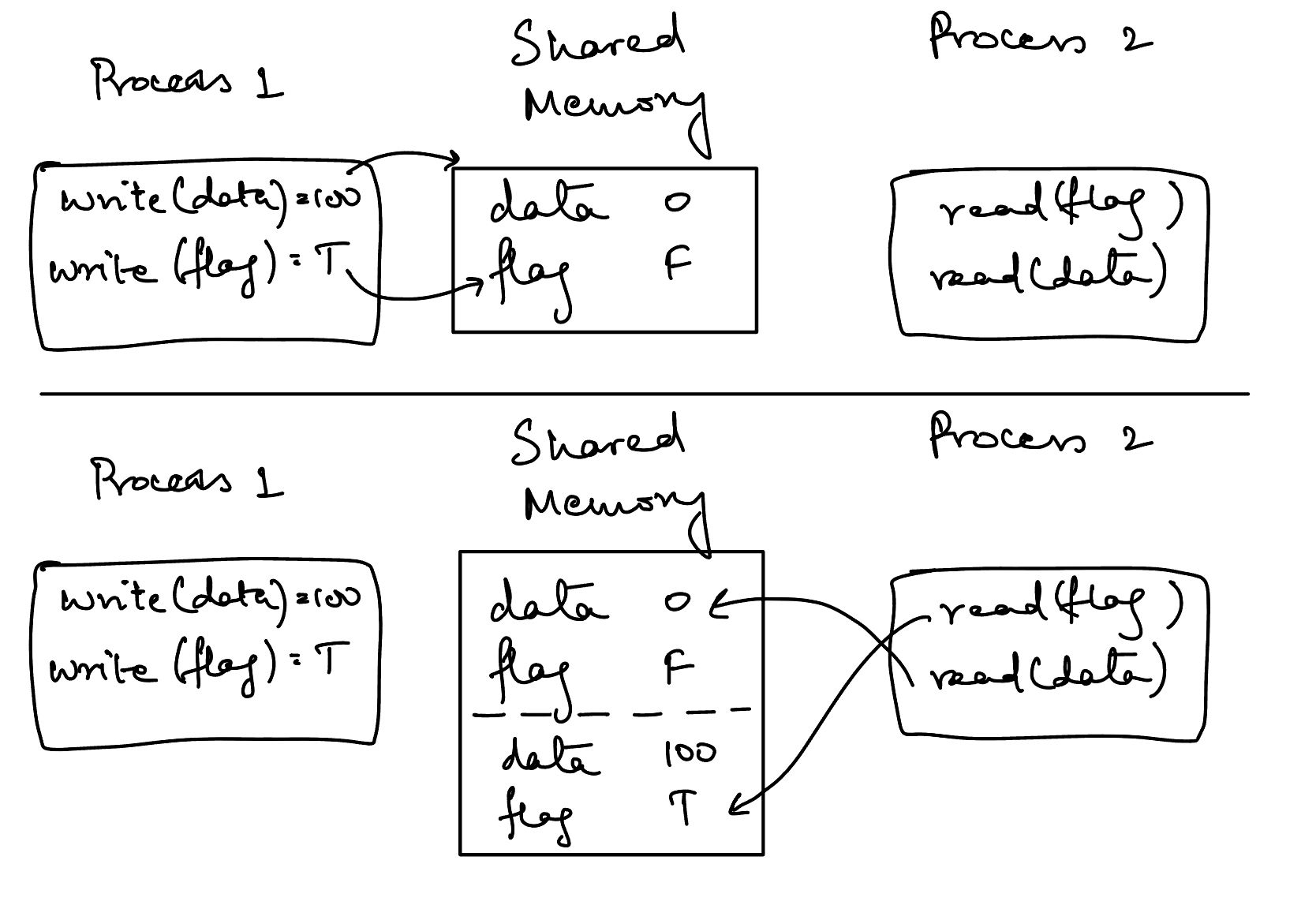
تجسم بالا به ما نشان می دهد که دو فرآیند ما (رشته) هیچ راهی برای توافق بر سر وضعیت فعلی یا ترتیب تغییر آن حالت ندارند.
هنگامی که فرآیند 2 مشخص کرد که پرچم روی true تنظیم شده است، پس سعی می کند مقدار data را بخواند. اما، موضوع 2 معتقد است که ارزش data هنوز تغییر نکرده است، حتی اگر معتقد است مقدار flag روی true تنظیم شده است.
این گیج کننده است زیرا مدل کلاسیک درهم آمیختن عملیات همزمان در اینجا کاربرد ندارد. در مدل کلاسیک عملیات همزمان، همیشه نظمی وجود دارد که می توان برقرار کرد. به عنوان مثال، می توان بيان کرد که این یکی از سناریوهای احتمالی عملیات است:
Thread 1 Memory Thread 2 --------- ------- --------- | | | | write(data, 100) | | | -----------------------> | | | | load(ready) == true | | | <---------------------- | | | | | store(ready, true) | | | -----------------------> | | | | | | | read(data) | | | <---------------------- | | | |اما، نمودار بالا فرض میکند که هر دو رشته بر روی نظم جهانی اتفاق افتادهاند، که دیگر اصلاً درست نیست! این هنوز برای من گیج کننده است که سرم را به اطراف بپیچم.
در حالت memory_order_relaxed ، دو رشته هیچ راهی برای توافق بر سر ترتیب عملیات روی متغیرهای مشترک ندارند. از نقطه نظر thread 1، عملیات اجرا شده به شرح زیر بود:
write(data, 100) store(ready, true)با این حال، از نقطه نظر thread 2، ترتیب عملیاتی که thread 1 اجرا می کرد عبارت بود از:
store(ready, true) write(data, 100)بدون توافق بر سر ترتیب انجام عملیات بر روی متغیرهای مشترک ، ایجاد تغییرات در آن متغیرها در سراسر رشته ها امن نیست.
خوب، بیایید کد را با جایگزین کردن std::memory_order_relax با std::memory_order_seq_cst اصلاح کنیم.
پس ، ready.store(true, std::memory_order_relaxed); ready.store(true, std::memory_order_seq_cst); و while (!ready.load(std::memory_order_relaxed)) تبدیل به while (!ready.load(std::memory_order_seq_cst)) می شود.
اگر این را دوباره با TSan اجرا کنید، دیگر مسابقه داده ای وجود ندارد. اما چرا آن را درست کرد؟
سد حافظه
پس ، ما قبلاً دیدیم که مشکل ما این است که دو رشته قادر به توافق بر یک دیدگاه واحد از رویدادها نیستند و میخواستیم از آن جلوگیری کنیم. پس ، ما یک مانع را با استفاده از سازگاری متوالی معرفی کردیم.
Thread 1 Memory Thread 2 --------- ------- --------- | | | | write(data, 100) | | | -----------------------> | | | | | | ================Memory Barrier=================== | | store(ready, true) | | | -----------------------> | | | | load(ready) == true | | | <---------------------- | | ================Memory Barrier=================== | | | | | | read(data) | | | <---------------------- | | | |مانع حافظه در اینجا می گوید که هیچ چیزی قبل از عملیات ذخیره و هیچ چیز بعد از عملیات بارگذاری قابل سفارش مجدد نیست. یعنی رشته 2 اکنون تضمینی دارد که کامپایلر یا CPU پس از نوشتن روی پرچم در رشته 1، نوشتن روی داده را قرار ندهد. به طور مشابه، عملیات خواندن در رشته 2 را نمی توان دوباره در بالای مانع حافظه مرتب کرد.
ناحیه داخل مانع حافظه شبیه به بخش مهمی است که یک نخ برای ورود به آن به یک mutex نیاز دارد. ما اکنون راهی برای همگام سازی دو رشته بر اساس ترتیب رویدادها در سراسر آنها داریم.
دیگر اخبار
بازیکنان Payday 3 هنوز سه روز پس از راهاندازی نمیتوانند در زمانهای اوج آنلاین آنلاین شوند
این ما را به مدل کلاسیک خود در همآمیزی همزمان بازمیگرداند زیرا اکنون ترتیبی از رویدادها داریم که هر دو رشته بر آن توافق دارند.
انواع سفارش حافظه
3 نوع اصلی ترتیب حافظه وجود دارد:
مدل حافظه آرام (std::memory_order_relaxed)
مدل حافظه Release-acquire (std::memory_order_release و std::memory_order_acquire)
ترتیب حافظه ثابت (std::memory_order_seq_cst)
ما قبلاً 1 و 3 را در مثال های بالا پوشش دادیم. مدل حافظه دوم به معنای واقعی کلمه از نظر سازگاری بین دو مدل دیگر قرار دارد.
#include <atomic> #include <cassert> #include <iostream> #include <thread> int data = 0; std::atomic<bool> ready(false); void producer() { data = 100; ready.store(true, std::memory_order_release); // Set flag } void consumer() { while (!ready.load(std::memory_order_acquire)) ; assert(data == 100); } int main() { std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); return 0; } مثال بالا همان مثال قبلی است، پیش بینی می شود std::memory_order_release برای ready.store() و memory_order_acquire برای read.load() استفاده شود. شهود در اینجا برای سفارش شبیه به مثال مانع حافظه قبلی است.
به جز، این بار مانع حافظه بر روی جفت عملیات ready.store() و ready.load() تشکیل می شود و تنها زمانی کار می کند که روی همان متغیر اتمی در سراسر رشته ها استفاده شود.
با فرض اینکه شما یک متغیر x دارید که در 2 رشته تغییر می کند، می توانید x.store(std::memory_order_release) در رشته 1 و x.load(std::memory_order_acquire) در موضوع 2 انجام دهید و یک نقطه همگام سازی در بین این دو خواهید داشت. موضوعات روی این متغیر
تفاوت بین مدل متوالی سازگار و مدل انتشار-اکتساب در این است که اولی یک نظم جهانی از عملیات را در همه رشته ها اعمال می کند، در حالی که دومی یک نظم را فقط در بین جفت عملیات انتشار و بدست آوردن اعمال می کند.
اکنون، میتوانیم دوباره تحلیل کنیم که چرا TSan در ابتدا از رقابت دادهها شکایت نکرد، در حالی که ترتیب حافظه مشخص نشده بود. دلیلش این است که C++ به طور پیشفرض یک std::memory_order_seq_cst زمانی که ترتیب حافظه مشخص نشده است در نظر میگیرد. از آنجایی که این قوی ترین حالت حافظه است، امکان رقابت داده وجود ندارد.
ملاحظات سخت افزاری
مدل های مختلف حافظه دارای جریمه های عملکرد متفاوت در سخت افزارهای مختلف هستند.
به عنوان مثال، مجموعه دستورالعمل معماری x86 چیزی به نام سفارش کل فروشگاه (TSO) را پیاده سازی می کند. ماهیت آن این است که این مدل به تمام موضوعات خواندن و نوشتن به یک حافظه مشترک شبیه است. شما می توانید بیشتر در مورد آن در اینجا بخوانید .
این بدان معناست که پردازندههای x86 میتوانند ثبات متوالی را برای جریمه محاسباتی نسبتاً پایین فراهم کنند.
در طرف دیگر خانواده پردازنده های ARM دارای معماری مجموعه دستورالعمل ضعیفی هستند. این به این دلیل است که هر رشته یا فرآیند در حافظه خود می خواند و می نویسد. دوباره، پیوند بالا زمینه را فراهم می کند.
این بدان معناست که پردازندههای ARM ثبات متوالی را برای جریمه محاسباتی بسیار بالاتر ارائه میکنند.
چگونه یک صف همزمان بسازیم
من قصد دارم از عملیاتی که تاکنون در مورد آن صحبت کردیم برای ساختن عملیات اساسی یک صف همزمان بدون قفل استفاده کنم. این به هیچ وجه حتی یک پیاده سازی کامل نیست، فقط تلاش من برای ایجاد دوباره چیزی اساسی با استفاده از اتمی است.
من می خواهم صف را با استفاده از یک فهرست پیوندی نشان دهم و هر گره را در داخل یک اتمی قرار دهم.
class lock_free_queue { private: struct node { std::shared_ptr<T> data; std::atomic<node*> next; node() : next(nullptr) {} // initialise the node }; std::atomic<node*> head; std::atomic<node*> tail; }اکنون، برای عملیات صف، این چیزی است که به نظر می رسد:
void enqueue(T value) { std::shared_ptr<T> new_data = std::make_shared<T>(value); node* new_node = new node(); new_node->data = new_data; // do an infinite loop to change the tail while (true) { node* current_tail = this->tail.load(std::memory_order_acquire); node* tail_next = current_tail->next; // everything is correct so far, attempt the swap if (current_tail->next.compare_exchange_strong( tail_next, new_node, std::memory_order_release)) { this->tail = new_node; break; } } } تمرکز اصلی بر روی عملیات load و compare_exchange_strong است. load با یک acquire کار می کند و CAS با release کار می کند به طوری که خواندن و نوشتن در دم همگام می شود.
به طور مشابه برای عملیات Dequeue:
std::shared_ptr<T> dequeue() { std::shared_ptr<T> return_value = nullptr; // do an infinite loop to change the head while (true) { node* current_head = this->head.load(std::memory_order_acquire); node* next_node = current_head->next; if (this->head.compare_exchange_strong(current_head, next_node, std::memory_order_release)) { return_value.swap(next_node->data); delete current_head; break; } } return return_value; }توجه: این صف مشکل ABA را حل نمی کند. آوردن نشانگرهای خطر خارج از محدوده این آموزش است، پس من آن را کنار می گذارم - اما اگر کنجکاو هستید می توانید آنها را تحلیل کنید.
نتیجه
پس شما آن را دارید - اتمی در C++. استدلال در مورد آنها دشوار است اما مزایای عملکردی عظیمی به شما می دهند. اگر میخواهید پیادهسازی درجه تولید ساختارهای داده بدون قفل را ببینید، میتوانید اطلاعات بیشتر را در اینجا بخوانید.
به طور معمول، ساختارهای داده همزمان مبتنی بر قفل را میبینید که تولید میشوند، اما تحقیقات فزایندهای در مورد اجرای بدون قفل و بدون انتظار الگوریتمهای همزمان برای بهبود کارایی محاسباتی وجود دارد.
اگر می خواهید این آموزش و سایر آموزش ها را بخوانید، می توانید از وب سایت من در اینجا دیدن کنید.
برچسبها
|
|




ارسال نظر