درک جاسازی کلمات: بلوک های ساختمان NLP و GPT

جاسازی کلمات به عنوان پایه و اساس بسیاری از کاربردها، از طبقه بندی متن ساده گرفته تا سیستم های پیچیده ترجمه ماشینی، عمل می کند. اما تعبیه کلمه دقیقاً چیست و چگونه کار می کند؟ بیایید دریابیم.
جاسازی کلمات چیست؟
جاسازی کلمات به عنوان DNA دیجیتال برای کلمات در دنیای پردازش زبان طبیعی (NLP) عمل می کند. در اصل، جاسازی کلمات، کلمات را به بردارهای عددی تبدیل می کند (یک اصطلاح شیک برای آرایه های اعداد). این بردارها را می توان توسط الگوریتم های یادگیری ماشین پردازش کرد.
این بردارها را به عنوان اثر انگشت عددی برای هر کلمه در نظر بگیرید. به عنوان مثال، کلمه "سیب" ممکن است با یک بردار عددی مانند [۰.۲، -۰.۴، ۰.۷] نشان داده شود.
مزیت اصلی جاسازی کلمات، توانایی آنها در تسخیر جوهر معنایی کلمات است. به عبارت سادهتر، آنها به ماشینها کمک میکنند معنا و تفاوتهای ظریف پشت هر کلمه را درک کنند.
برای مثال، اگر «سیب» در این فضای عددی نزدیک به «میوه» باشد اما از «ماشین» دور باشد، دستگاه میفهمد که سیب بیشتر به میوهها مرتبط است تا وسایل نقلیه.
فراتر از معنای فردی، تعبیه کلمات همچنین روابط بین کلمات را رمزگذاری می کند. کلماتی که اغلب با هم در یک زمینه ظاهر می شوند، بردارهای مشابه یا نزدیکتر خواهند داشت.
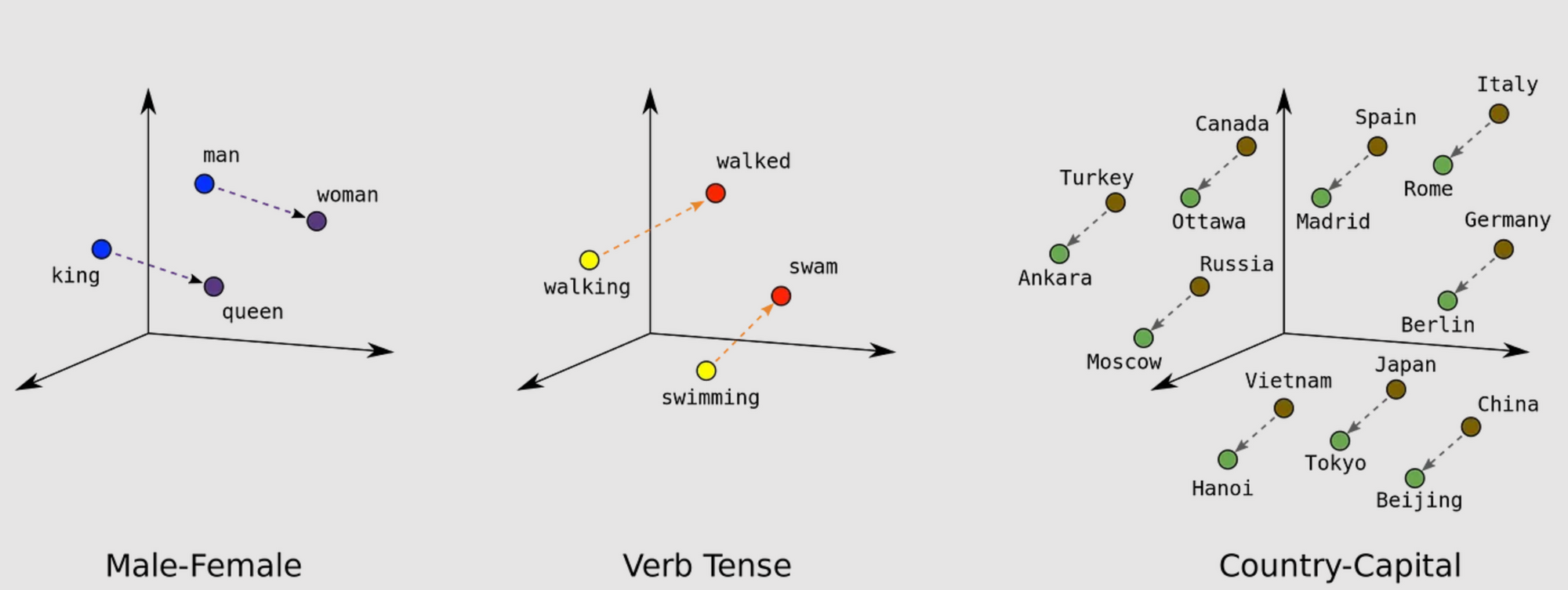
برای مثال، در فضای عددی، بردارهایی که «پادشاه» و «ملکه» را نشان میدهند ممکن است به هم نزدیکتر از بردارهای «شاه» و «سیب» باشند. این به این دلیل است که الگوریتم از متون متعدد آموخته است که «شاه» و «ملکه» اغلب در موقعیتهای مشابهی مانند بحثهای مربوط به سلطنت ظاهر میشوند، در حالی که «شاه» و «سیب» اینطور نیستند.
چرا به جاسازی کلمه نیاز داریم؟
مدلهای زبان سنتی، کلمات را بهعنوان موجودات مجزا و منزوی در نظر میگرفتند.
به عنوان مثال، کلمه "سگ" ممکن است به عنوان یک شناسه منحصر به فرد، مثلا ۱، در حالی که کلمه "گربه" به عنوان ۲ نشان داده شود. .
تعبیه کلمات این مشکل را با قرار دادن کلمات با معانی یا زمینه های مشابه نزدیک به یکدیگر در یک فضای چند بعدی حل می کند.
الگوریتمهای ایجاد تعبیهها
Word2Vec
محققان در گوگل Word2Vec را توسعه دادند که از شبکه های عصبی برای ایجاد جاسازی کلمات استفاده می کند. مدل یک مجموعه متن بزرگ را پردازش می کند و بردارهای کلمه با کیفیت بالا را خروجی می دهد.
این تعبیهها را با تحلیل زمینهای که کلمات در آن ظاهر میشوند تعیین میکند، بر اساس این ایده که کلمات یافت شده در زمینههای مشابه احتمالاً دارای معنای معنایی هستند.
GloVe (بردارهای جهانی برای نمایش کلمه)
محققان دانشگاه استنفورد GloVe را توسعه دادند که یک جدول بزرگ برای نظارت بر فراوانی کلمات در یک مجموعه داده متنی ایجاد می کند. سپس مدل از روشهای ریاضی برای سادهسازی این جدول استفاده میکند و بردارهای عددی را برای کلمات جداگانه تولید میکند.
این بردارها هم معنا و هم روابط بین کلمات را محصور می کنند و زمینه را برای کارهای مختلف یادگیری ماشینی مرتبط با زبان فراهم می کنند.
FastText
آزمایشگاه تحقیقاتی هوش مصنوعی فیسبوک FastText را ایجاد کرد که با مشاهده کلمات به عنوان مجموعهای از رشتههای کاراکتر کوچکتر یا کاراکترهای n-گرم، مدل Word2Vec را بهبود میبخشد.
این روش مدل را قادر میسازد تا پیچیدگیهای زبانهایی را که ساختار واژهای پیچیدهای دارند و کلماتی را که در دادههای آموزشی اصلی وجود ندارند، بهطور مؤثرتر ثبت کند. در نتیجه، FastText یک مدل زبان سازگارتر و جامعتر ارائه میکند که برای مجموعهای متنوع از وظایف یادگیری ماشینی مفید است.
جاسازی کلمه و GPT
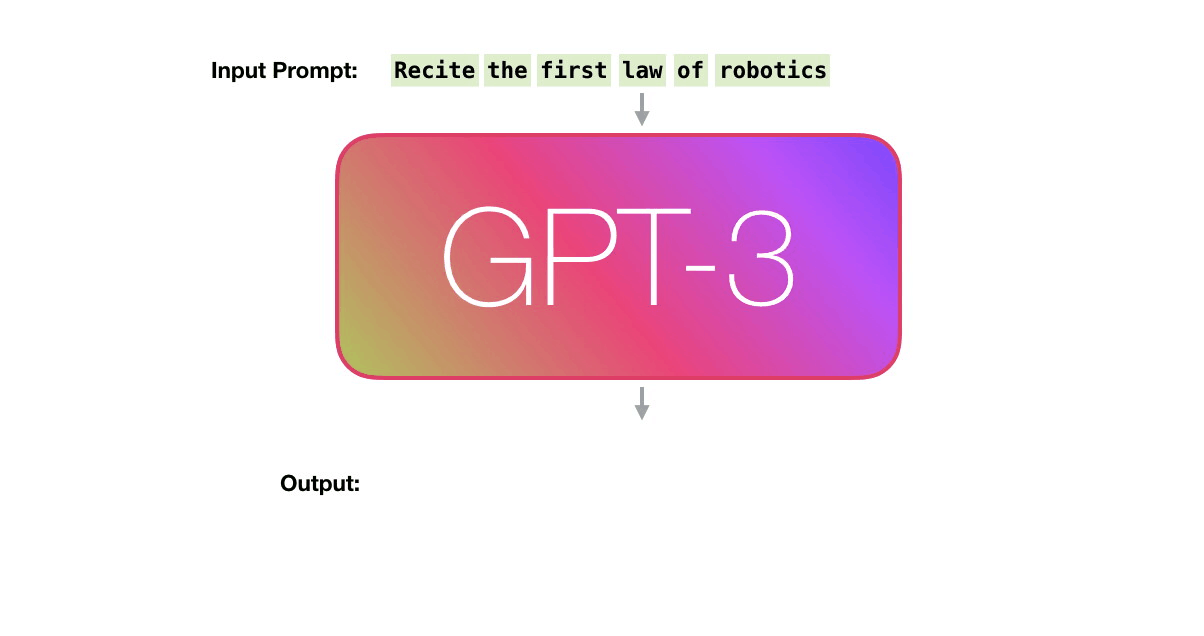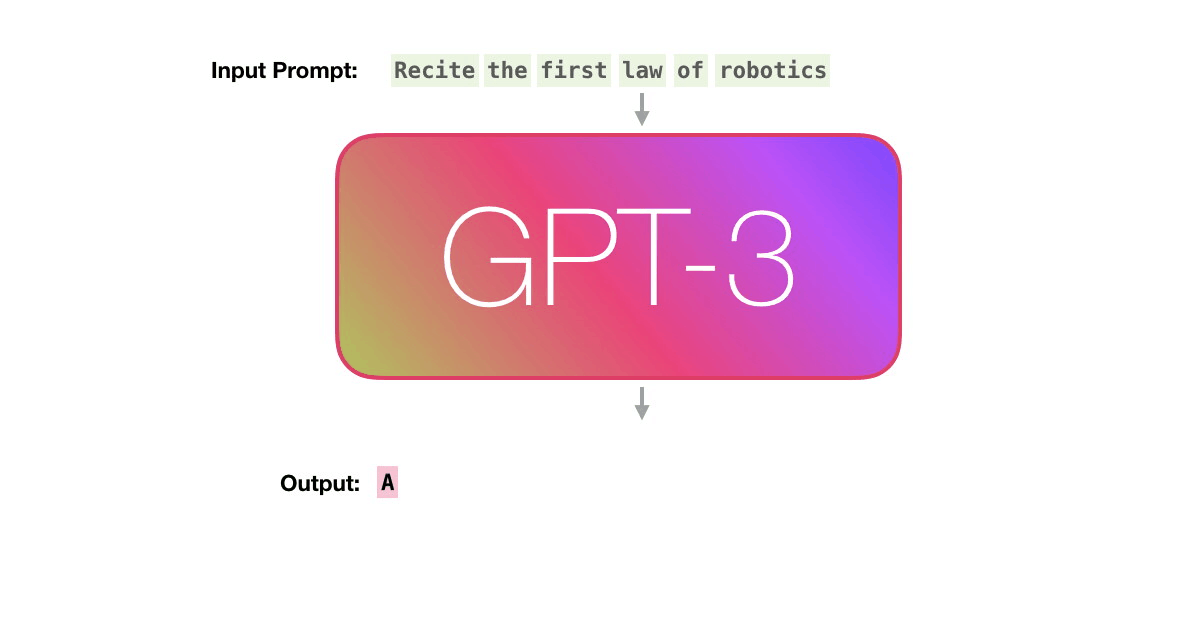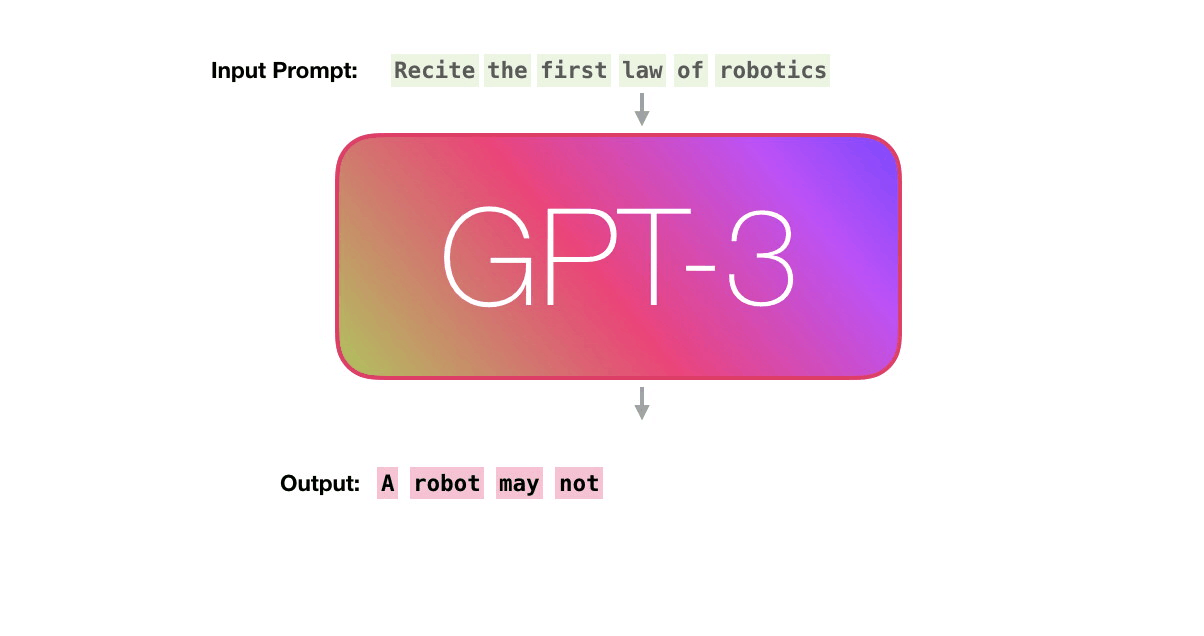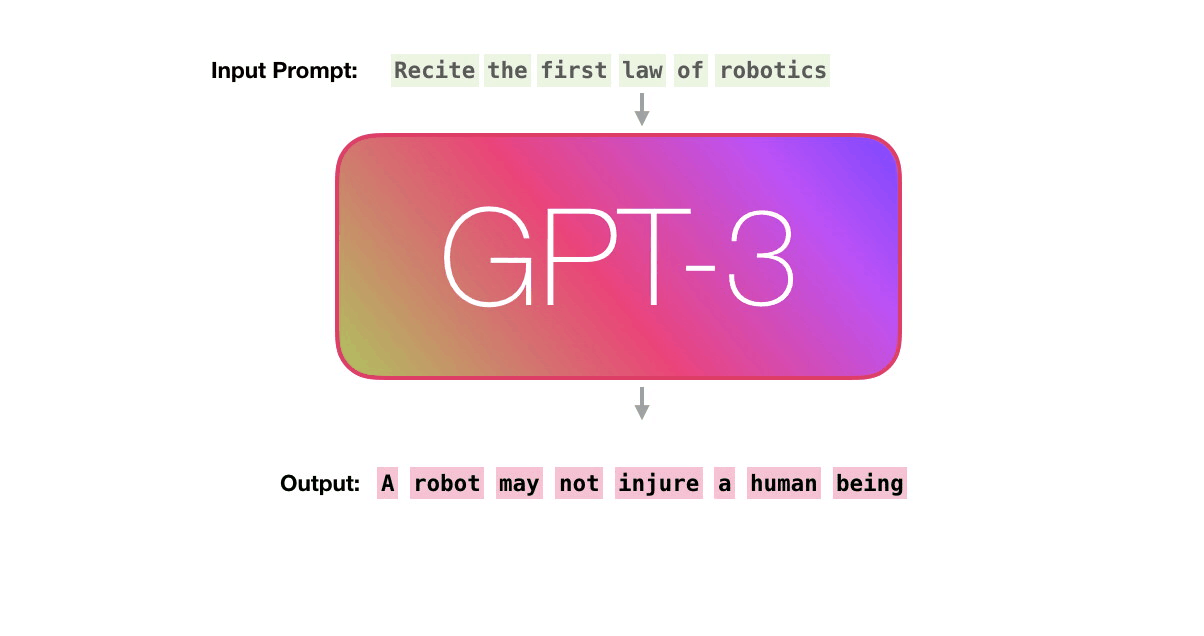
جاسازی های کلمه یک جزء اساسی در مدل های GPT مانند GPT-2، GPT-3 و GPT-4 است. با این حال، معماری و رویکرد در مقایسه با مدلهای سادهتر که صرفاً بر تعبیه کلمات متکی هستند، کمی پیشرفتهتر است.
در مدلهای سنتی که از جاسازیهای کلمه مانند Word2Vec یا GloVe استفاده میکنند، هر کلمه در یک فضای از پیش تعریف شده به یک بردار ثابت تبدیل میشود. سپس این بردارها به عنوان ورودی سایر الگوریتمهای یادگیری ماشین برای کارهایی مانند طبقهبندی، خوشهبندی یا حتی در مدلهای ترتیب به دنباله برای ترجمه ماشینی استفاده میشوند.
در مقابل، مدلهای GPT از گونهای به نام «جاسازیهای ترانسفورماتور» استفاده میکنند که نه تنها کلمات جداگانه را درج میکند، بلکه زمینهای را که یک کلمه در آن ظاهر میشود نیز در نظر میگیرد.
این برای درک معنای کلماتی که می توانند بر اساس کلمات اطراف خود تغییر کنند ضروری است. به عنوان مثال، کلمه "بانک" بسته به زمینه می تواند به معنای یک موسسه مالی یا کنار رودخانه باشد.
معماری GPT دنباله ای از کلمات (یا به طور دقیق تر، نشانه ها) را به عنوان ورودی می گیرد و آنها را از طریق چندین لایه از بلوک های ترانسفورماتور پردازش می کند. این بلوکها دنباله جدیدی از بردارها را تولید میکنند که نه تنها تک تک کلمات، بلکه روابط آنها را با سایر کلمات در دنباله ورودی نیز نشان میدهند.
بیشتر بخوانید
سپس این دنباله برای کارهای NLP، از تکمیل متن تا ترجمه و خلاصه سازی استفاده می شود.
پس ، در حالی که مدلهای GPT از جاسازیها استفاده میکنند، بسیار پویاتر و آگاهتر از جاسازیهای کلمه سنتی هستند. جاسازیها در مدلهای GPT بخشی از یک سیستم بزرگتر و پیچیدهتر هستند که برای درک و تولید متنهای انسانمانند بر اساس ورودیهایی که دریافت میکند، طراحی شدهاند.
نتیجه
تعبیههای کلمه روشی مؤثر و کارآمد محاسباتی برای نمایش کلمات بهعنوان بردار ارائه میکند و پیچیدگیهای زبان را به شکلی که ماشینها میتوانند درک کنند، نشان میدهد. آنها در قلب بسیاری از برنامه های NLP قرار دارند و دقت و پیچیدگی مدل های زبان را بهبود می بخشند.
همانطور که فن آوری به تکامل خود ادامه می دهد، روش های تولید و استفاده از جاسازی های کلمه نیز ادامه می یابد و نویدبخش قابلیت های پردازش زبان قوی تر و ظریف تر در سال های آینده است.
اگر این مقاله برای شما جالب بود، به خبرنامه من بپیوندید و من هر جمعه یک ایمیل با محتوای خود برای شما ارسال می کنم.
برچسبها
|
|



ارسال نظر