معرفی کامپیوتر سرگشتگی: یک سیستم عامل هوش مصنوعی «امنتر» ساخته شده بر پایه OpenClaw


آخرین تأیید: فوریه ۲۰۲۶. ویژگیهای محصول، نامهای سطوح اشتراک و جزئیات رقبا، وضعیت بازار را تا این تاریخ منعکس میکنند و به سرعت در معرض تغییر هستند. قبل از تکیه بر جزئیات خاص، جزئیات فعلی را در perplexity.ai تأیید کنید.
کامپیوتر پرفلکسیتی چیست؟
کامپیوتر پرپلکسیتی (Perplexity Computer) یک عامل هوش مصنوعی چند مدلی است که یک اعلان به زبان طبیعی را میپذیرد و به طور مستقل برنامهریزی میکند، وب را مرور میکند، فایلها را دستکاری میکند و APIها را برای ارائه مصنوعات نهایی فراخوانی میکند. این کامپیوتر که بر اساس چارچوب تنظیم داخلی پرپلکسیتی ساخته شده است، هر زیروظیفه را به یک LLM مرزی تخصصی هدایت میکند و عملیات ابزار را بدون دخالت دستی بین مراحل، به گردشهای کاری سرتاسری زنجیر میکند.
کامپیوتر Perplexity یک درخواست به زبان طبیعی را میپذیرد و کار تمامشده را برمیگرداند: تحقیقات کامپایلشده، صفحات گسترده فرمتشده، رزروهای انجامشده، دادههای استخراجشده از APIها و ارجاع متقابل در منابع مختلف. این کامپیوتر که بر اساس چارچوب تنظیم داخلی Perplexity ساخته شده است، مرور، عملیات فایل و فراخوانیهای API را بدون دخالت دستی در گردشهای کاری واحد زنجیره میکند.
برای توسعهدهندگان و کاربران حرفهای که در حال ارزیابی مسیر هوش مصنوعی عاملمحور هستند، درک اینکه عامل واقعاً در پشت صحنه چه کاری انجام میدهد، لایه تنظیم آن چگونه وظایف را در مدلهای پیشرو هدایت میکند و موانع کجا قرار دارند، بیش از تبلیغات بازاریابی اهمیت دارد.
فهرست مطالب
کامپیوتر پرفلکسیتی چیست؟
از موتور جستجو تا عامل خودمختار
پرپلکسیتی (Perplexity) کار خود را به عنوان یک موتور جستجو با رابط کاربری محاورهای آغاز کرد، موتوری که نتایج وب را به جای بازگرداندن فهرستی رتبهبندیشده از URLها، به پاسخهای مستقیم تبدیل میکرد. سپس پاسخهای مبتنی بر استناد و استدلالهای تکمیلی را در صدر زیرساخت بازیابی خود قرار داد. کامپیوتر پرپلکسیتی (Perplexity Computer) مرحله بعدی این مسیر است و اساساً دستهبندی متفاوتی از محصولات را در بر میگیرد.
به جای پاسخ دادن به سوالات، عامل وظایف را اجرا میکند. کاربر یک هدف سطح بالا را به زبان طبیعی ارائه میدهد، چیزی شبیه به «تحقیق در مورد سطوح قیمتگذاری این پنج محصول SaaS رقیب و ایجاد یک صفحه گسترده مقایسهای»، و سیستم به طور مستقل یک خروجی نهایی را برنامهریزی، اجرا و مونتاژ میکند. عامل یک گزارش، یک مجموعه داده، یک سند یا تأیید یک اقدام تکمیلشده را برمیگرداند، نه یک پیام چت. تمایز بین چتبات و عامل یک دوگانگی سخت نیست؛ چتباتهای استفادهکننده از ابزار به طور فزایندهای گردشهای کاری چند مرحلهای را تجزیه و اجرا میکنند. اما کامپیوتر پرپلکسیتی در انتهای این طیف قرار دارد: یک هدف را به زیروظایف تجزیه میکند، ابزارها را انتخاب میکند، گردشهای کاری چند مرحلهای را اجرا میکند و مصنوعات را با حداقل دخالت کاربر بین مراحل تولید میکند.
در عمل، این به این معنی است که عامل، مرور وب، دستکاری فایلها و فراخوانیهای API را به صورت زنجیرهای و در یک گردش کار واحد انجام میدهد، بدون اینکه کاربران مجبور باشند هر مرحله را به صورت دستی هدایت کنند.
به جای پاسخ دادن به سوالات، عامل وظایف را اجرا میکند. کاربر یک هدف سطح بالا را به زبان طبیعی ارائه میدهد و سیستم به طور مستقل برنامهریزی، اجرا و یک نتیجه نهایی را جمعآوری میکند.
چه کسی دسترسی پیدا میکند؟
این عامل با قیمت 20 دلار در ماه برای مشترکین Perplexity Pro در دسترس است (نام سطح فعلی و قیمتگذاری را در perplexity.ai/pricing تأیید کنید). این قیمت قابل توجه است: این عامل، قابلیتهای عامل چند مدلی را در پشت اشتراک مصرفکننده قرار میدهد، نه اینکه آنها را در پشت قراردادهای سازمانی یا لیستهای انتظار که نیاز به تماسهای فروش سفارشی دارند، قرار دهد. برای مقایسه، طرح Pro شرکت OpenAI 200 دلار در ماه است، اگرچه این دو محصول از نظر دامنه متفاوت هستند. این قیمتگذاری، این ابزار را برای توسعهدهندگان، محققان و کاربران حرفهای قابل دسترس میکند، حتی اگر هدف اصلی آن، گردشهای کاری در سطح سازمانی باشد.
دسترسی به پلتفرم شامل وب و دسکتاپ میشود و دسترسی به موبایل نیز از ردپای برنامه موجود Perplexity پیروی میکند. برابری ویژگیها در سطوح مختلف تا ژوئیه 2025 ناقص است؛ برای محدودیتهای فعلی مختص پلتفرم، مستندات Perplexity را بررسی کنید. گردش کار اصلی agentic را میتوان از هر کلاینتی که یک prompt ارسال میکند و خروجی ساختاریافته دریافت میکند، آغاز کرد.
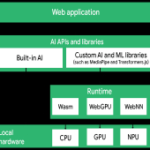
چارچوب ارکستراسیون
لایه ارکستراسیون چه کاری انجام میدهد؟
لایه ارکستراسیون چیزی است که این را به یک عامل تبدیل میکند، نه یک پوشش پیرامون یک مدل زبانی بزرگ. در عمل، ارکستراسیون به معنای وقوع هماهنگ چندین اتفاق است: تجزیه هدف کاربر به زیروظایف گسسته، انتخاب مدلی که هر زیروظیفه را مدیریت میکند، اعزام ابزارهای مناسب (مرورگر وب، سیستم فایل، کلاینت HTTP) در لحظات مناسب، حفظ حالت مشترک در سراسر گردش کار (پرپلکسیتی فاش نکرده است که آیا این از یک دفترچه یادداشت مشترک، پنجرههای زمینهای برای هر زیروظیفه یا معماری دیگری استفاده میکند) و مونتاژ خروجی نهایی از نتایج تمام عملیات موازی و متوالی.
لایه ارکستراسیون را به عنوان سیستم عصبی متصل کننده چندین LLM مرزی و لایههای ابزار در نظر بگیرید. یک معماری یکپارچه، مانند قرار دادن یک فراخوانی GPT-4 در اطراف یک اعلان، یک مدل را مجبور میکند تا استدلال، تولید کد، خلاصهسازی و استفاده از ابزار را به طور همزمان مدیریت کند. چارچوب Perplexity این نگرانیها را از هم جدا میکند. هر زیروظیفه به مدلی که برای آن مناسبتر است هدایت میشود و لایه اجرای ابزار مستقل از لایه مدل عمل میکند و توسط گراف ارکستراسیون هماهنگ میشود.
لایه ارکستراسیون را به عنوان سیستم عصبی متصل کننده چندین LLM مرزی و لایههای ابزار در نظر بگیرید. یک معماری یکپارچه، یک مدل را مجبور میکند تا استدلال، تولید کد، خلاصهسازی و استفاده از ابزار را به طور همزمان مدیریت کند. چارچوب Perplexity این نگرانیها را از هم جدا میکند.
مسیریابی چند مدلی در عمل
لایه هماهنگسازی، مدلهای مختلفی را برای انواع مختلف زیروظیفه انتخاب میکند. یک زیروظیفه سنگین استدلال، مانند ارزیابی اینکه آیا دو نقطه داده متضاد از منابع مختلف قابل تطبیق هستند یا خیر، به مدلی که برای استدلال زنجیرهای از افکار بهینه شده است، مسیردهی میکند. زیروظیفهای که نیاز به تولید یک اسکریپت پایتون برای تجزیه یک CSV دارد، به یک مدل تخصصی کد میرود. خلاصهسازی، استخراج مبتنی بر بینایی از یک اسکرینشات یا PDF و بازیابی واقعی، هر کدام منطق مسیریابی خاص خود را دارند.
LLM های مرزی خاص در مجموعه مسیریابی کاملاً عمومی نیستند و گمانهزنی در مورد مشارکتهای مدل اختصاصی زودهنگام خواهد بود. آنچه از نظر معماری اهمیت دارد، اصل است: چارچوب ارکستراسیون با مدلها به عنوان متخصصان قابل تعویض رفتار میکند، نه به عنوان یک موتور عمومی واحد که مجبور به انجام همه کارها است.
تصویر نمودار وظیفه
نمودار نمایشی زیر با فرمت YAML، یک تجزیه وظیفه فرضی را نشان میدهد. این یک طرحواره API یا مشخصات قابل اجرا نیست؛ تمام نامهای فیلد و مقادیر مدل فقط برای نمایش هستند.
prompt : "Research Q1 earnings for these three companies, extract revenue figures, and compile a summary spreadsheet."
schema_version : "0.1-illustrative"
plan : - id : subtask_1 type : research model : "reasoning" tool : "web_browse" action : "Navigate to investor relations pages for each company, locate Q1 earnings reports" outputs : [ earnings_pages ]
- id : subtask_2 type : extraction model : "vision" tool : "file_read" action : "Download earnings PDFs, extract revenue figures from tables" inputs : [ earnings_pages ] outputs : [ revenue_figures ]
- id : subtask_3 type : compilation model : "code" tool : "file_write" action : "Generate a formatted spreadsheet with extracted figures" inputs : [ revenue_figures ] outputs : [ spreadsheet ]
- id : subtask_4 type : summary model : "summarize" tool : null action : "Produce a narrative summary of key findings" inputs : [ revenue_figures ] outputs : [ narrative_brief ]
assembly : merge : - subtask_id : subtask_3 output : spreadsheet - subtask_id : subtask_4 output : narrative_brief qa_check : method : cross_reference sources : [ subtask_1.earnings_pages ] on_failure : retry
final_output : files : - type : spreadsheet source : subtask_3 - type : narrative_brief source : subtask_4 description : "Summary spreadsheet + narrative brief delivered to user" هر گره در نمودار، یک واحد کاری گسسته را نشان میدهد. فیلد id به طور منحصر به فرد زیروظیفه را مشخص میکند. فیلد model تعیین میکند که کدام LLM کار شناختی را مدیریت میکند. فیلد tool تعیین میکند که عامل چه قابلیت خارجی را فراخوانی میکند (وقتی به ابزار خارجی نیاز نیست، روی null تنظیم میشود). فیلدهای inputs و outputs جریان دادهها بین زیروظایف را تعریف میکنند. مرحله assembly، خروجیها را با استفاده از ارجاعات ساختاریافته به نتایج زیروظیفه خاص ادغام میکند و یک pass تضمین کیفیت را اجرا میکند، دادههای استخراجشده را با اسناد منبع اصلی ارجاع متقابل میدهد، با یک استراتژی مدیریت شکست تعریفشده، قبل از تحویل مصنوع نهایی.
مرور وب و اتوماسیون
قابلیت مرور وب این عامل فراتر از بازیابی نتایج جستجو است. این عامل صفحات را پیمایش میکند، فرمها را پر میکند، دادههای ساختاریافته را از HTML استخراج میکند و گردشهای کاری چند مرحلهای وب را که معمولاً نیاز به کلیک انسان در میان صفحات متوالی دارند، مدیریت میکند. اتوماسیون مرورگر یک لایه قابلیت جداگانه است که در کنار زیرساخت جستجو و بازیابی موجود Perplexity ساخته شده است و محصول را به قلمرو تعاملی گسترش میدهد که نمایهسازی جستجو به تنهایی آن را پوشش نمیدهد.
فرض کنید کاربری از نماینده میخواهد که قیمتگذاری رقبا را در پنج وبسایت محصول SaaS بررسی کند. نماینده به هر صفحه قیمتگذاری میرود، نام ردیفها، لیست ویژگیها و نقاط قیمت را استخراج میکند و نتایج را در یک جدول مقایسه ساختاریافته گردآوری میکند. وقتی به جای قیمتگذاری عمومی با صفحه "تماس با فروش" مواجه میشود، آن ورودی را در جدول خروجی به عنوان غیرقابل تجزیه علامتگذاری میکند و شکاف را یادداشت میکند تا کاربر بداند کدام فروشندگان نیاز به پیگیری دستی دارند. پیمایش چند مرحلهای، استخراج دادهها و مونتاژ خروجی ساختاریافته، همگی بدون دخالت کاربر بین مراحل اتفاق میافتند.
دستکاری سیستم فایل
خواندن، ایجاد، ویرایش و سازماندهی فایلها در قالبهای رایج (اسناد، صفحات گسترده، CSVها، تصاویر و PDFها) همگی در محدودهی کاری عامل قرار میگیرند. این فراتر از تولید فایلها از ابتدا است. عامل فایلهای موجودی را که کاربر ارائه میدهد میخواند، دادهها را از آنها استخراج میکند، آن دادهها را تبدیل میکند و بر اساس نتایج، فایلهای جدید مینویسد.
یک کاربر سه فایل PDF درآمد سه ماهه را آپلود میکند و درخواست یک سند خلاصه که روند درآمد را برجسته میکند، میکند. نماینده هر PDF را میخواند، ارقام مالی مربوطه را با استفاده از مدلهای دارای قابلیت بینایی برای استخراج جدول استخراج میکند، تغییرات سه ماهه به سه ماهه را محاسبه میکند و یک صفحه گسترده قالببندی شده و یک سند خلاصه روایی تولید میکند.
فراخوانیهای HTTP API
این عامل با استفاده از APIهای شخص ثالث، احراز هویت را انجام داده و از طرف کاربر فراخوانی میکند و گردشهای کاری یکپارچهسازی را که قبلاً به اسکریپتنویسی سفارشی یا پلتفرمهای اتوماسیون اختصاصی مانند Zapier نیاز داشتند، فراهم میکند.
یک کاربر میخواهد دادههای معاملات اخیر را از یک رابط برنامهنویسی نرمافزار CRM دریافت کند، آن را با اهداف موجود در یک صفحه گسترده موجود مقایسه کند و خلاصهای از آن را از طریق وبهوک به یک کانال Slack ارسال کند. عامل، دادهها را تأیید اعتبار میکند، بازیابی میکند، مقادیر را مقایسه میکند و وبهوک را فعال میکند، همه اینها در یک گردش کار. مدیریت اعتبارنامه در اینجا بسیار مهم است: عامل با مجوزهای اعطا شده توسط کاربر کار میکند و کلیدهای API یا توکنهای OAuth را به جلسه گردش کار خاص محدود میکند، نه اینکه آنها را به طور گسترده حفظ کند.
راهنمای گردش کار: یک گام تا تحویل نهایی
کاربر یک هدف به زبان طبیعی ارائه میدهد. هیچ نحو یا ورودی ساختاریافته خاصی لازم نیست. درخواست میتواند از باز ("تهیه تحلیل بازار از بخش شارژ خودروهای برقی اروپا") تا محدود ("دانلود این CSV، فیلتر کردن ردیفهایی که درآمد آنها از 1 میلیون دلار بیشتر است، و ارسال نتیجه به من از طریق ایمیل") متغیر باشد.
از آن دستور، چارچوب ارکستراسیون یک نمودار ساختاریافته از زیروظایف میسازد. هر زیروظیفه ورودیها، خروجیها، وابستگیها و الزامات ابزار تعریفشدهای دارد. ساختار نمودار به زیروظایف مستقل اجازه میدهد تا به صورت موازی اجرا شوند، در حالی که وابستگیهای متوالی را رعایت میکنند. سپس لایه ارکستراسیون هر زیروظیفه را به یک مدل مرزی متناسب با نوع آن اختصاص میدهد: وظایف استدلال، تولید کد، خلاصهسازی و وظایف بینایی که هر کدام به مدلهای تخصصی منتهی میشوند.
زیروظایف از طریق لایه ابزار مناسب اجرا میشوند: مرور وب برای تحقیق و استخراج دادهها، ابزارهای فایل برای خواندن و نوشتن اسناد، یا کلاینتهای HTTP برای فراخوانیهای API. پس از اتمام اجرا، مرحله مونتاژ، خروجیهای همه زیروظایف را ادغام میکند. عامل یک بررسی خودکار را در برابر دستور اصلی انجام میدهد تا کامل بودن و سازگاری را تأیید کند. اگر شکافهایی را تشخیص دهد، زیروظایف را دوباره اجرا یا تکمیل میکند. کاربر مصنوع تکمیلشده را دریافت میکند: یک سند، یک مجموعه داده، تأیید یک اقدام تکمیلشده یا ترکیبی از خروجیها.
جایگاه کامپیوتر سرگشتگی در چشمانداز عاملهای هوش مصنوعی
مقایسه با سایر سیستمهای عامل
مامور وارد میدانی میشود که به سرعت شلوغ میشود.
بیشتر بخوانید
رقبا تقریباً به دو اردوگاه تقسیم میشوند. عاملهای سطح محصول، اجرای وظایف را به صورت آماده ارائه میدهند: Operator شرکت OpenAI گردشهای کاری عاملمحور را به عنوان یک محصول مستقل ارائه میدهد، در حالی که قابلیتهای استفاده از ابزار ChatGPT، فراخوانی تابع و مرور وب را در یک زمینه مدل واحد قرار میدهد. استفاده از کامپیوتر Claude شرکت Anthropic، محیطهای دسکتاپ مجازی را از طریق API، که مبتنی بر دیدگاه و استدلال Claude است، خودکار میکند. Project Mariner گوگل، یک نمونه اولیه تحقیقاتی DeepMind که گردشهای کاری عامل مبتنی بر مرورگر را هدف قرار میدهد، هنوز به طور کلی در دسترس نیست. ابزارهای سطح چارچوب مانند AutoGPT، CrewAI و LangGraph بلوکهای سازنده خام را برای ساخت خطوط لوله عامل از ابتدا در اختیار توسعهدهندگان قرار میدهند، اما به مونتاژ قابل توجهی نیاز دارند.
کامپیوتر پرپلکسیتی در سه انتخاب معماری با هر دو اردوگاه متفاوت است. اول، مسیریابی چند مدلی: چارچوب هماهنگسازی، وظایف فرعی را به جای محدود شدن به یک ارائهدهنده واحد، در چندین LLM توزیع میکند. این یک تفاوت در سطح طراحی است؛ اینکه آیا خروجیهای به مراتب بهتری نسبت به رویکردهای تک مدلی تولید میکند یا خیر، به طور مستقل معیارسنجی نشده است. دوم، قیمتگذاری: با قیمت 20 دلار در ماه برای Pro (در مقایسه با سطح Pro 200 دلار در ماه OpenAI)، مانع ورود کمتر است، اگرچه این دو محصول از نظر دامنه قابلیت متفاوت هستند. سوم، پایهگذاری دادههای بومی جستجو: از آنجا که پرپلکسیتی زیرساخت بازیابی خود را قبل از ساخت لایه عامل ساخته است، عامل دارای یک ستون فقرات بازیابی داخلی است که رقبا باید جداگانه آن را نصب کنند. این یک مزیت معماری در تئوری است. در عمل، دقت پایهگذاری در گردشهای کاری عامل به طور مستقل اندازهگیری نشده است.
این چه سیگنالی برای بازار دارد؟
عاملها در حال تبدیل شدن به محصولات مستقل هستند، نه ویژگیهایی که به رابطهای چت متصل شدهاند. اگر این روند ادامه یابد، تصمیمات خرید از «کدام مدل در معیارها بالاترین امتیاز را کسب میکند» به «کدام لایه هماهنگسازی، قابل اعتمادترین گردشهای کاری سرتاسری را ارائه میدهد» تغییر خواهد کرد. این پیشبینی قابل ابطال است: اگر بازار حول عاملهای تک مدلی که از نظر قابلیت اطمینان با هماهنگسازی چند مدلی مطابقت دارند، متمرکز شود، رویکرد مسیریابی ارزش خود را از دست میدهد. برای توسعهدهندگانی که بر روی این پلتفرمها کار میکنند یا با آنها رقابت میکنند، درک لایه هماهنگسازی حداقل به اندازه درک مدلهای اساسی اهمیت دارد.
نمایندگان در حال تبدیل شدن به محصولات مستقل هستند، نه ویژگیهایی که به رابطهای چت متصل شدهاند. اگر این روند ادامه یابد، تصمیمات خرید از «کدام مدل در معیارها بالاترین امتیاز را کسب میکند» به «کدام لایه هماهنگسازی، قابل اعتمادترین گردشهای کاری سرتاسری را ارائه میدهد» تغییر خواهد کرد.
ایمنی، مجوزها و محدودیتها
مدل مجوز و کنترل کاربر
این عامل در یک مدل مجوز فعالیت میکند که در آن اقدامات با ریسک بالا نیاز به تأیید صریح کاربر دارند. Perplexity اظهار میکند که بدون بررسیهای انسانی در حلقه، تراکنشهای مالی را به صورت خودکار انجام نمیدهد، ارتباطات ارسال نمیکند یا سیستمهای خارجی را تغییر نمیدهد. کاربران باید قبل از واگذاری گردشهای کاری حساس، رفتار مجوز فعلی را در مستندات Perplexity در perplexity.ai تأیید کنند. عامل به جای اینکه اعتبارنامهها را به طور گسترده حفظ کند، هر کلید API و جلسه ورود را به جلسه گردش کاری فعال محدود میکند. کاربران مجوزها را به ازای هر وظیفه اعطا میکنند، نه به صورت کلی.
محدودیتهای فعلی برای بررسی
محدودیتهای واقعی وجود دارد. گردشهای کاری پیچیده چند مرحلهای به سقف پیچیدگی وظیفه میرسند که در آن نمودار هماهنگی شکننده میشود و شکستهای زیروظیفه به صورت آبشاری رخ میدهند. پرپلکسیتی آستانه مشخصی برای این مورد منتشر نکرده است (مثلاً حداکثر تعداد زیروظیفه یا عمق وابستگی)، بنابراین کاربران باید با گردشهای کاری سادهتر شروع کنند و پیچیدگی را به صورت تدریجی افزایش دهند. هر مرحله زنجیرهای، خطر توهم را افزایش میدهد: یک خطای واقعی در مرحله دوم، هر خروجی پاییندستی را خراب میکند. پرپلکسیتی از ژوئیه 2025 ارقام محدودیت سرعت یا اعداد تأخیر معمول را برای گردشهای کاری عاملمحور منتشر نکرده است. مشترکینی که گردشهای کاری فشرده را اجرا میکنند باید انتظار تغییرپذیری را داشته باشند و تحمل تلاشهای مجدد را در نظر بگیرند. قبل از واگذاری کارهای حساس، سیاست حفظ حریم خصوصی فعلی پرپلکسیتی را در perplexity.ai/privacy، به ویژه بخشهایی که شامل نگهداری دادهها برای جلسات عاملمحور و دادههای API شخص ثالث است، بررسی کنید.
چک لیست ایمنی و مجوزها
قبل از واگذاری وظایف حساس، توسعهدهندگان و کاربران حرفهای باید موارد زیر را بررسی کنند:
قبل از هر جلسه، مجوزهای اعطا شده را بررسی کنید. فرض نکنید که مجوزها به طور ایمن از گردشهای کاری قبلی منتقل میشوند.
کلیدهای API در حال تولید به توکنهای محدود شده نیاز دارند، نه اعتبارنامههای اصلی. برای مثال، هنگام ادغام با یک API CRM، به جای استفاده از کلید API اصلی خود، یک توکن OAuth فقط خواندنی ایجاد کنید. برای دستورالعملهای محدود کردن توکن، به مستندات ارائه دهنده API خود مراجعه کنید.
خروجیهای نماینده را در وظایف مالی یا حقوقی پرمخاطره به عنوان پیشنویس در نظر بگیرید، نه به عنوان محصول نهایی. تأیید مسئولیت شماست، نه نماینده.
سیاستهای نگهداری دادهها مهم هستند. آنچه را که Perplexity از جلسات اپراتورها ذخیره میکند، به ویژه هنگامی که دادههای شخص ثالث در میان است، در perplexity.ai/privacy بررسی کنید.
زنجیرههای چند ابزار را برای عوارض جانبی ناخواسته رصد کنید. نوشتن فایلی که توسط یک پاسخ نادرست API ایجاد میشود، میتواند مشکلات بعدی ایجاد کند که ردیابی آنها دشوار است.
نکات کلیدی
لایه هماهنگسازی، نه یک مدل واحد، چیزی است که Perplexity Computer را متمایز میکند: این لایه زیروظایف را در LLMهای تخصصی و لایههای ابزار مسیریابی میکند، به این معنی که ارزیابی عامل نیازمند ارزیابی منطق مسیریابی است، نه فقط مدلهای زیربنایی. با قیمت 20 دلار در ماه، قیمتگذاری از اکثر رقبایی که دامنه عامل مشابهی دارند، کمتر است، اگرچه تفاوت در قابلیتها، مقایسه مستقیم را دشوار میکند (قیمتگذاری فعلی را در perplexity.ai/pricing تأیید کنید). اگر گردشهای کاری چند مرحلهای را واگذار میکنید، هر خروجی را به عنوان یک پیشنویس در نظر بگیرید: خطر توهم در هر مرحله زنجیرهای افزایش مییابد و هیچ نقطه بازرسی انسانی در حلقه، خطاهایی را که به نظر محتمل میرسند، شناسایی نمیکند.
برچسبها
|
|



ارسال نظر