الگوریتم جنگل تصادفی در یادگیری ماشین الگوریتم جنگل تصادفی در یادگیری ماشین شناسهٔ خبر: 847442 - تاریخ: ژانویه 27, 2025 مهدی نوروزی برچسبها آموزش آموزش برنامه نویسی آموزش خارجی اخبار مرتبط : چرا مقیاس پذیری وردپرس با ساختار سایت هوشمند از روز اول شروع می شود؟ چرا مقیاس پذیری وردپرس با ساختار سایت هوشمند از روز اول شروع می شود؟ نحوه ساخت برنامه های وب مقیاس پذیر با React JS آموزش Ampere Porting Advisor مبانی Node.js Streams ارسال نظر دیدگاهها بسته شدهاند.
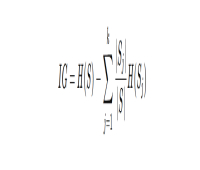






ارسال نظر