چگونه از Python SDK برای ساختن وب Scraper خود استفاده کنید

Web scraping چیست؟
Web scraping تکنیکی است که برای جمع آوری مقادیر زیادی داده به صورت خودکار با استفاده از یک اسکریپت برنامه نویسی استفاده می شود. این امر آن را برای بسیاری از متخصصان مانند تحلیلگران داده، محققان بازار، متخصصان سئو، تحلیلگران تجاری و محققان دانشگاهی مفید می کند.
آنچه در اینجا خواهید آموخت
پایتون دو کتابخانه به نامهای Requests و Beautiful Soup ارائه میکند که به شما کمک میکند وبسایتها را راحتتر خراش دهید. استفاده ترکیبی از درخواستهای Python و Beautiful Soup میتواند محتوای HTML را از یک وبسایت بازیابی کند و سپس آن را برای استخراج دادههای مورد نیاز تجزیه کند. در این مقاله نحوه استفاده از این کتابخانه ها را با یک مثال به شما نشان می دهم.
اگر با این مفهوم تازه کار هستید و در سطح متوسطی از تخصص پایتون دارید، میتوانید دوره توسعهدهنده Python در Hyperskill را تحلیل کنید، جایی که من به عنوان یک متخصص در آن مشارکت میکنم.
در پایان این راهنما، شما برای ساختن Web Scraper خود مجهز خواهید شد و درک عمیق تری از کار با حجم زیادی از داده ها و نحوه اعمال آن برای تصمیم گیری های مبتنی بر داده خواهید داشت.
لطفاً توجه داشته باشید که اگرچه وب اسکراپر ابزار مفیدی است، مطمئن شوید که با تمام دستورالعملهای قانونی مطابقت دارید. این شامل احترام به فایل robots.txt وب سایت و رعایت شرایط خدمات است تا از استخراج غیرمجاز داده ها جلوگیری کنید.
همچنین، قبل از خراش دادن، مطمئن شوید که فرآیند خراش دادن به عملکرد وب سایت آسیبی نمی رساند یا سرورهای آن را بیش از حد بارگذاری نمی کند. در نهایت، با حذف نکردن اطلاعات شخصی یا حساس بدون رضایت مناسب، به حریم خصوصی داده ها احترام بگذارید.
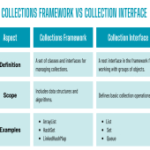
چگونه سوپ زیبا و درخواست های پایتون با هم کار می کنند
بیایید نقش هر کتابخانه را درک کنیم.
کتابخانه درخواستهای پایتون مسئول واکشی محتوای HTML از آدرس اینترنتی شما در اسکریپت است. هنگامی که محتوا را بازیابی می کند، داده ها را در یک شی پاسخ ذخیره می کند.
سپس Beautiful Soup کار را به دست می گیرد و HTML خام را از پاسخ Requests به قالبی ساختاریافته تبدیل می کند و آن را تجزیه می کند. سپس میتوانید با مشخص کردن ویژگیها، دادهها را از HTML تجزیهشده پاک کنید و به شما این امکان را میدهد که جمعآوری دادههای خاص از وبسایتها یا مخازن را خودکار کنید.
اما این دوتایی محدودیت هایی دارد. کتابخانه Requests نمی تواند وب سایت هایی با محتوای جاوا اسکریپت پویا را مدیریت کند. پس شما باید از آن در درجه اول برای سایت هایی استفاده کنید که محتوای ثابت از سرورها را ارائه می دهند. اگر نیاز به خراش دادن یک سایت بارگذاری شده پویا دارید، باید از ابزارهای اتوماسیون پیشرفته تری مانند سلنیوم استفاده کنید.
چگونه با Python SDK یک Web Scraper بسازیم
اکنون که فهمیدیم Beautiful Soup و Python Requests چه کاری می توانند انجام دهند، بیایید در مورد اینکه چگونه می توانیم داده ها را با استفاده از این ابزارها خراش دهیم، بحث کنیم.
در مثال زیر، دادهها را از مخزن یادگیری ماشین UC Irvine جمعآوری میکنیم.
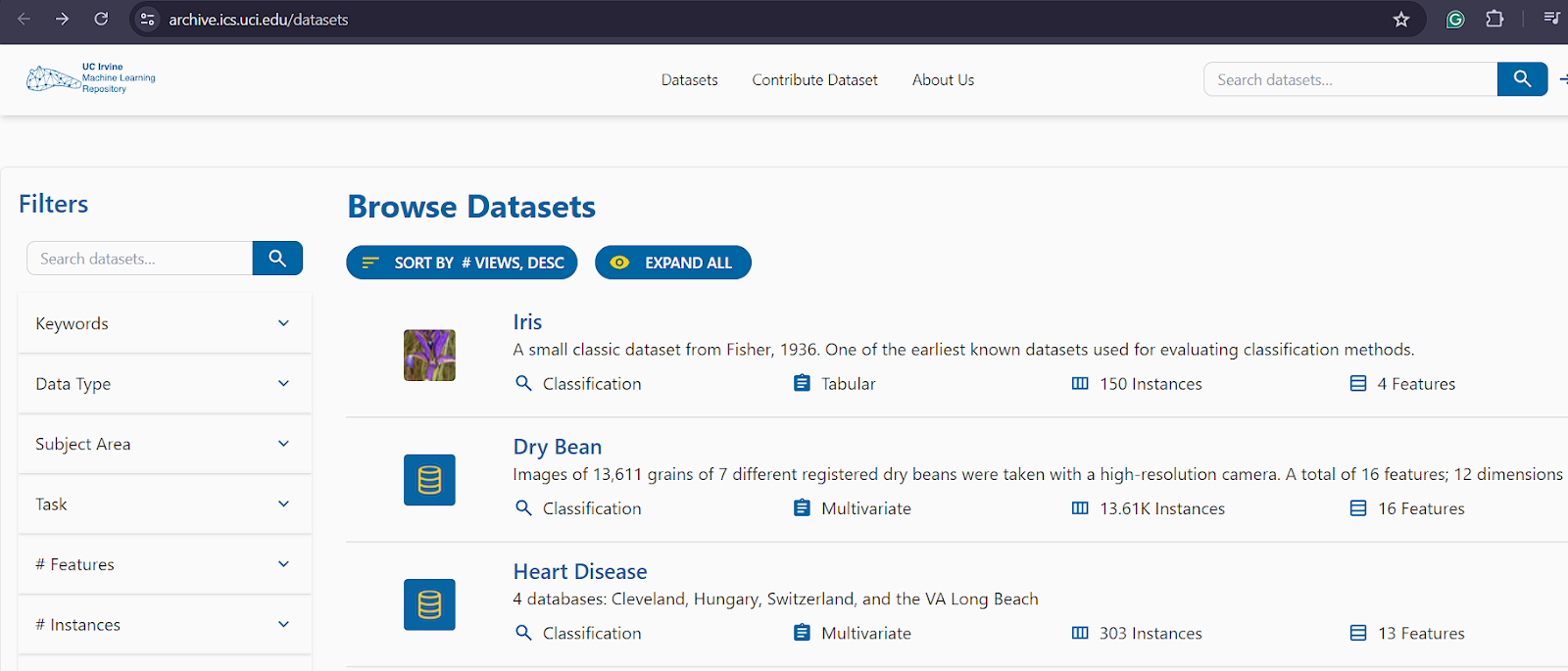
همانطور که می بینید، شامل مجموعه داده های زیادی است و می توانید با رفتن به صفحه اختصاصی مجموعه داده، جزئیات بیشتری در مورد هر مجموعه پیدا کنید. با کلیک بر روی نام مجموعه داده در فهرست بالا می توانید به صفحه اختصاصی دسترسی پیدا کنید.
برای دریافت ایده از اطلاعات ارائه شده برای هر مجموعه داده، تصویر زیر را تحلیل کنید.
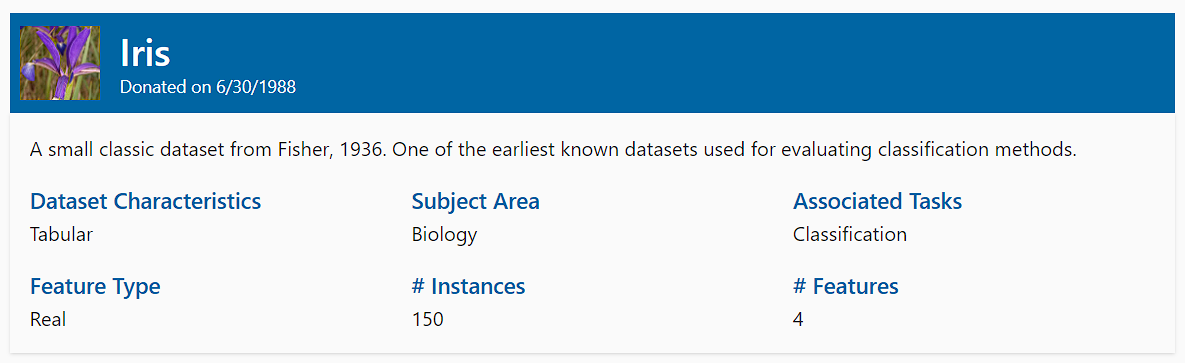
کدی که در زیر می نویسیم از هر مجموعه داده عبور می کند، جزئیات را می خراشد و آنها را در یک فایل CSV ذخیره می کند.
مرحله 1: وارد کردن کتابخانه های ضروری
ابتدا کتابخانه های لازم را وارد کنید: درخواست هایی برای ایجاد درخواست های HTTP، BeautifulSoup برای تجزیه محتوای HTML و CSV برای ذخیره داده ها.
import requests from bs4 import BeautifulSoup import csvمرحله 2: URL پایه و سرصفحه CSV را تعریف کنید
URL پایه را برای فهرست های مجموعه داده تنظیم کنید و سرصفحه های فایل CSV را که در آن داده های خراشیده شده ذخیره می شود، تعریف کنید.
def scrape_uci_datasets(): base_url = "https://archive.ics.uci.edu/datasets" headers = [ "Dataset Name", "Donated Date", "Description", "Dataset Characteristics", "Subject Area", "Associated Tasks", "Feature Type", "Instances", "Features" ] data = []مرحله 3: یک تابع برای خراش دادن جزئیات مجموعه داده ایجاد کنید
یک تابع scrape_dataset_details تعریف کنید که URL یک صفحه مجموعه داده جداگانه را می گیرد، محتوای HTML را بازیابی می کند، آن را با استفاده از BeautifulSoup تجزیه می کند و اطلاعات مرتبط را استخراج می کند.
def scrape_dataset_details(dataset_url): response = requests.get(dataset_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_name = soup.find( 'h1', class_='text-3xl font-semibold text-primary-content') dataset_name = dataset_name.text.strip() if dataset_name else "N/A" donated_date = soup.find('h2', class_='text-sm text-primary-content') donated_date = donated_date.text.strip().replace( 'Donated on ', '') if donated_date else "N/A" description = soup.find('p', class_='svelte-17wf9gp') description = description.text.strip() if description else "N/A" details = soup.find_all('div', class_='col-span-4') dataset_characteristics = details[0].find('p').text.strip() if len( details) > 0 else "N/A" subject_area = details[1].find('p').text.strip() if len( details) > 1 else "N/A" associated_tasks = details[2].find('p').text.strip() if len( details) > 2 else "N/A" feature_type = details[3].find('p').text.strip() if len( details) > 3 else "N/A" instances = details[4].find('p').text.strip() if len( details) > 4 else "N/A" features = details[5].find('p').text.strip() if len( details) > 5 else "N/A" return [ dataset_name, donated_date, description, dataset_characteristics, subject_area, associated_tasks, feature_type, instances, features ] تابع scrape_dataset_details محتوای HTML یک صفحه مجموعه داده را بازیابی می کند و آن را با استفاده از BeautifulSoup تجزیه می کند. اطلاعات را با هدف قرار دادن عناصر خاص HTML بر اساس برچسبها و کلاسهای آنها، مانند نام مجموعه دادهها، تاریخ اهدا و توضیحات استخراج میکند.
این تابع از روشهایی مانند find و find_all برای مکان یابی این عناصر و بازیابی محتوای متنی آنها استفاده میکند و با ارائه مقادیر پیشفرض، مواردی را که ممکن است عناصر گم شده باشند، مدیریت میکند.
این رویکرد سیستماتیک تضمین می کند که جزئیات مربوطه به طور دقیق ضبط شده و در قالبی ساختاریافته بازگردانده می شوند.
مرحله 4: یک تابع برای خراش دادن فهرست های مجموعه داده ایجاد کنید
یک تابع scrape_datasets تعریف کنید که URL صفحه ای را که مجموعه داده های متعددی را فهرست می کند، می گیرد، محتوای HTML را بازیابی می کند و همه پیوندهای مجموعه داده را پیدا می کند. برای هر پیوند، scrape_dataset_details برای دریافت اطلاعات دقیق فراخوانی می کند.
def scrape_datasets(page_url): response = requests.get(page_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_list = soup.find_all( 'a', class_='link-hover link text-xl font-semibold') if not dataset_list: print("No dataset links found") return for dataset in dataset_list: dataset_link = "https://archive.ics.uci.edu" + dataset['href'] print(f"Scraping details for {dataset.text.strip()}...") dataset_details = scrape_dataset_details(dataset_link) data.append(dataset_details)مرحله 5: با استفاده از پارامترهای صفحه بندی، صفحات را حلقه بزنید
یک حلقه برای پیمایش در صفحات با استفاده از پارامترهای صفحه بندی پیاده سازی کنید. این حلقه تا زمانی ادامه می یابد که هیچ داده جدیدی اضافه نشود، که نشان می دهد تمام صفحات خراشیده شده اند.
skip = 0 take = 10 while True: page_url = f"https://archive.ics.uci.edu/datasets?skip={skip}&take={take}&sort=desc&orderBy=NumHits&search=" print(f"Scraping page: {page_url}") initial_data_count = len(data) scrape_datasets(page_url) if len( data ) == initial_data_count: break skip += takeمرحله 6: داده های خراشیده شده را در یک فایل CSV ذخیره کنید
پس از خراش دادن تمام داده ها، آن را در یک فایل CSV ذخیره کنید.
with open('uci_datasets.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerow(headers) writer.writerows(data) print("Scraping complete. Data saved to 'uci_datasets.csv'.")مرحله 7: عملکرد Scraping را اجرا کنید
در نهایت، تابع scrape_uci_datasets را فراخوانی کنید تا فرآیند خراشیدن شروع شود.
scrape_uci_datasets()کد کامل
در اینجا کد کامل وب اسکراپر آمده است:
import requests from bs4 import BeautifulSoup import csv def scrape_uci_datasets(): base_url = "https://archive.ics.uci.edu/datasets" headers = [ "Dataset Name", "Donated Date", "Description", "Dataset Characteristics", "Subject Area", "Associated Tasks", "Feature Type", "Instances", "Features" ] # List to store the scraped data data = [] def scrape_dataset_details(dataset_url): response = requests.get(dataset_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_name = soup.find( 'h1', class_='text-3xl font-semibold text-primary-content') dataset_name = dataset_name.text.strip() if dataset_name else "N/A" donated_date = soup.find('h2', class_='text-sm text-primary-content') donated_date = donated_date.text.strip().replace( 'Donated on ', '') if donated_date else "N/A" description = soup.find('p', class_='svelte-17wf9gp') description = description.text.strip() if description else "N/A" details = soup.find_all('div', class_='col-span-4') dataset_characteristics = details[0].find('p').text.strip() if len( details) > 0 else "N/A" subject_area = details[1].find('p').text.strip() if len( details) > 1 else "N/A" associated_tasks = details[2].find('p').text.strip() if len( details) > 2 else "N/A" feature_type = details[3].find('p').text.strip() if len( details) > 3 else "N/A" instances = details[4].find('p').text.strip() if len( details) > 4 else "N/A" features = details[5].find('p').text.strip() if len( details) > 5 else "N/A" return [ dataset_name, donated_date, description, dataset_characteristics, subject_area, associated_tasks, feature_type, instances, features ] def scrape_datasets(page_url): response = requests.get(page_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_list = soup.find_all( 'a', class_='link-hover link text-xl font-semibold') if not dataset_list: print("No dataset links found") return for dataset in dataset_list: dataset_link = "https://archive.ics.uci.edu" + dataset['href'] print(f"Scraping details for {dataset.text.strip()}...") dataset_details = scrape_dataset_details(dataset_link) data.append(dataset_details) # Loop through the pages using the pagination parameters skip = 0 take = 10 while True: page_url = f"https://archive.ics.uci.edu/datasets?skip={skip}&take={take}&sort=desc&orderBy=NumHits&search=" print(f"Scraping page: {page_url}") initial_data_count = len(data) scrape_datasets(page_url) if len( data ) == initial_data_count: break skip += take with open('uci_datasets.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerow(headers) writer.writerows(data) print("Scraping complete. Data saved to 'uci_datasets.csv'.") scrape_uci_datasets()هنگامی که اسکریپت را اجرا می کنید، برای مدتی اجرا می شود تا زمانی که ترمینال بگوید "هیچ پیوند داده ای یافت نشد" و سپس "خراش کامل شد". دادهها در "uci_datasets.csv" ذخیره شدند، که نشان میدهد دادههای خراشیده شده در یک فایل CSV ذخیره شدهاند.

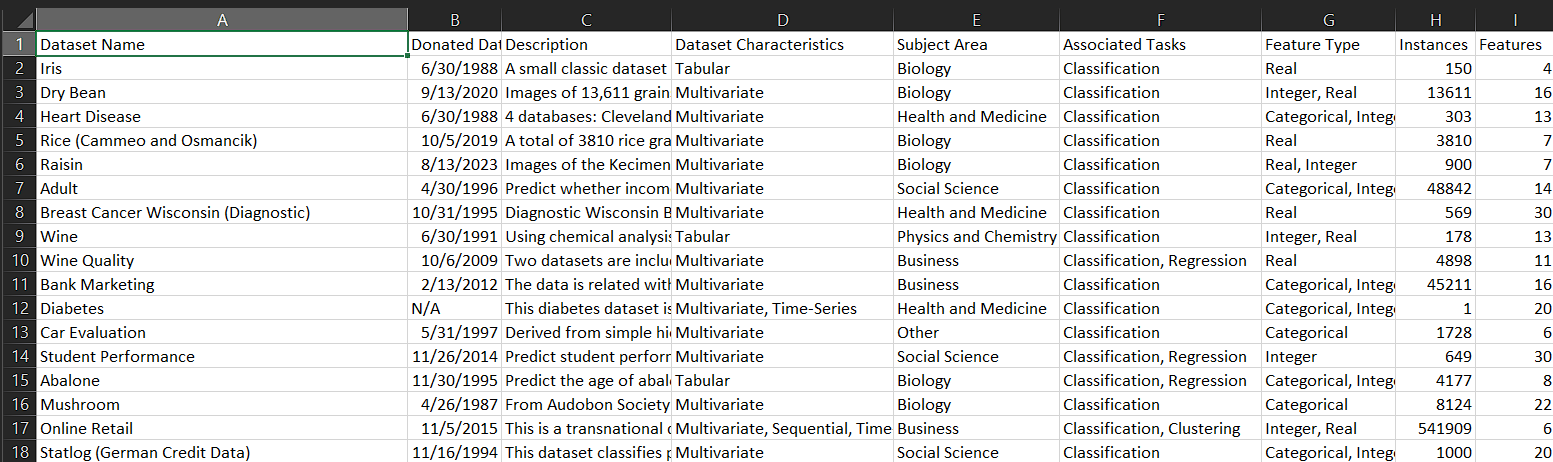
برای مشاهده داده های خراشیده شده، 'uci_datasets.csv' را باز کنید، باید بتوانید داده های سازماندهی شده بر اساس نام مجموعه داده، تاریخ اهدا، توضیحات، ویژگی ها، منطقه موضوعی و غیره را مشاهده کنید.

اگر فایل را از طریق اکسل باز کنید، می توانید دید بهتری از داده ها داشته باشید.
با پیروی از منطق ذکر شده در این مقاله، می توانید بسیاری از سایت ها را خراش دهید. تنها کاری که باید انجام دهید این است که از URL اصلی شروع کنید، نحوه پیمایش در فهرست را بیابید و به صفحه اختصاصی برای هر مورد فهرست بروید. سپس، عناصر صفحه مناسب مانند شناسهها و کلاسها را شناسایی کنید تا بتوانید دادههای مورد نظر خود را جداسازی و استخراج کنید.
همچنین باید منطق پشت صفحه بندی را درک کنید. اغلب، صفحهبندی تغییرات جزئی در URL ایجاد میکند، که میتوانید از آن برای چرخش از یک صفحه به صفحه دیگر استفاده کنید.
در نهایت، می توانید داده ها را در یک فایل CSV بنویسید که برای ذخیره سازی و به عنوان ورودی برای تجسم مناسب است.
نتیجه
استفاده از Python SDK به همراه درخواست ها و Beautiful Soup به شما این امکان را می دهد که وب اسکرپرهای کاملاً کاربردی برای استخراج داده ها از وب سایت ها ایجاد کنید. در حالی که این عملکرد می تواند برای تصمیم گیری مبتنی بر داده بسیار سودمند باشد، مهم است که ملاحظات اخلاقی و قانونی را در نظر داشته باشید.
هنگامی که با روش های استفاده شده در این اسکریپت آشنا شدید، می توانید تکنیک هایی مانند مدیریت پروکسی و ماندگاری داده ها را تحلیل کنید. همچنین می توانید با کتابخانه های دیگر مانند Scrapy، Selenium و Puppeteer آشنا شوید تا نیازهای جمع آوری داده های خود را برآورده کنید.
با تشکر از شما برای خواندن! من جس هستم و در Hyperskill متخصص هستم. می توانید یک توسعه دهنده پایتون را تحلیل کنید دوره روی پلت فرم
برچسبها
|
|



ارسال نظر