نحوه استفاده از S-expressions در جاوا اسکریپت
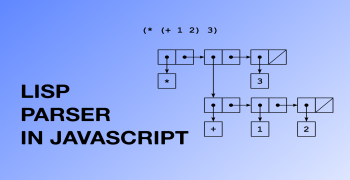
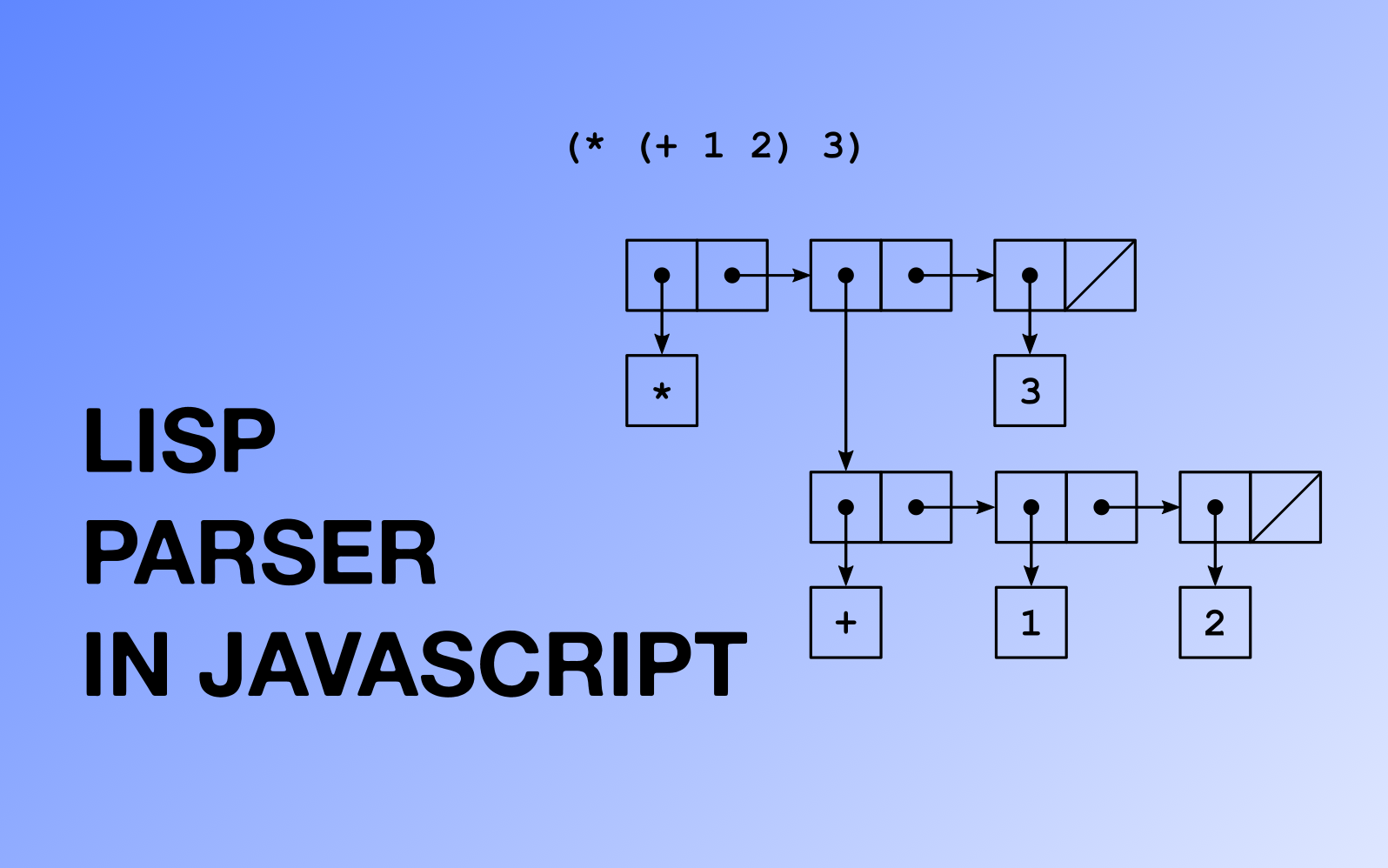
S-expressions پایه خانواده زبان های برنامه نویسی Lisp هستند. در این مقاله نحوه ایجاد یک تجزیه کننده ساده بیان S را مرحله به مرحله به شما نشان خواهم داد. این می تواند پایه ای برای تجزیه کننده Lisp باشد.
Lisp ساده ترین زبان برای پیاده سازی است و ایجاد تجزیه کننده اولین قدم است. ما میتوانیم از یک تجزیهکننده برای این کار استفاده کنیم، اما نوشتن تجزیهکننده را خودتان آسانتر است. ما از جاوا اسکریپت استفاده خواهیم کرد.
عبارات S چیست؟
اگر با زبان Lisp آشنایی ندارید، S-expressions به این صورت است:
(+ (second (list "xxx" 10)) 20)این یک فرمت داده است که در آن همه چیز از اتم ها یا فهرست هایی که با پرانتز احاطه شده اند ایجاد می شود (جایی که اتم های فهرست های دیگر با فاصله از هم جدا می شوند).
S-expressions می توانند انواع داده های مختلفی داشته باشند، درست مانند JSON:
شماره
رشته های
نمادها - که مانند رشته ها هستند اما بدون نقل قول می توانند تفسیر شوند
به عنوان نام متغیر از زبان های مختلف.
علاوه بر این، می توانید از یک عملگر نقطه خاصی استفاده کنید که یک جفت ایجاد می کند.
(1 . b)شما می توانید یک فهرست را به صورت جفت های نقطه چین نشان دهید (که نشان می دهد آنها در واقع یک ساختار داده فهرست پیوندی هستند).
این فهرست :
(1 2 3 4)می توان به صورت زیر نوشت:
(1 . (2 . (3 . (4 . nil)))) nil نماد خاصی است که پایان فهرست یک فهرست خالی را نشان می دهد. با این فرمت می توانید هر درخت باینری ایجاد کنید. اما ما از این علامت نقطهگذاری در تجزیهکننده خود استفاده نمیکنیم تا مسائل را پیچیده نکنیم.
عبارات S برای چه مواردی استفاده می شود؟
کد Lisp از S-expressions ایجاد می شود، اما می توانید از آن برای تبادل فرمت نیز استفاده کنید.
آنها همچنین بخشی از نمایش متن WebAssembly هستند. احتمالاً به دلیل سادگی تجزیه کننده است، و اینکه شما نیازی به ارائه فرمت خود ندارید. می توانید به جای JSON از آنها برای ارتباط بین سرور و مرورگر استفاده کنید.
توکنایزر
توکنایزر بخشی از تجزیه کننده است که متن را به نشانه هایی تقسیم می کند که می توان آنها را تجزیه کرد.
معمولاً یک تجزیه کننده با Lexer یا توکنایزر همراه است که توکن ها را تولید می کند.
برخی از مولدهای تجزیه کننده اینگونه کار می کنند (مانند lex و Yacc یا flex و bison. دومی نرم افزار رایگان و متن باز است که بخشی از پروژه گنو است).
ساده ترین راه نشانه گذاری استفاده از عبارات منظم است. اگر با عبارات منظم (یا به اختصار Regex) آشنا نیستید، می توانید این مقاله را بخوانید:
راهنمای عملی عبارات منظم - Regex را با مثال های واقعی بیاموزید .
این ساده ترین راه توکن سازی است:
'(foo bar (baz))'.split(/(\(|\)|\n|\s+|\S+)/);این یک اتحادیه (با اپراتور لوله) یا موارد مختلفی است که باید رسیدگی کنیم. پرانتزها کاراکترهای خاصی در Regex هستند، پس باید با یک اسلش از آنها فرار کنید.
تقریباً کار می کند. اولین مشکل این است که رشته های خالی بین تطبیق regex وجود دارد. مانند این عبارت:
'(('.split(/(\(|\)|\n|\s+|\S+)/); // ==> [ '', '(', '', '(', '' ]ما به جای 2 تا 5 توکن داریم. می توانیم این مشکل را با Array::filter حل کنیم.
'(('.split(/(\(|\)|\n|\s+|\S+)/).filter(token => token.length); // ==> ["(", "("] اگر توکن خالی باشد، طول 0 برمی گردد و به false تبدیل می شود، به این معنی که تمام رشته های خالی را فیلتر می کند.
ما همچنین به فضاها نیاز نداریم، پس می توانیم آنها را فیلتر کنیم:
'( ('.split(/(\(|\)|\n|\s+|\S+)/).filter(token => token.trim().length); // ==> ["(", "("] دومین مشکل بزرگتر مربوط به baz)) به عنوان آخرین نشانه، در اینجا یک مثال است:
دیگر اخبار
Vision Pro اپل اکنون دارای بیش از 1000 برنامه است که به طور خاص برای دستگاه جدید طراحی شده است
'(foo bar (baz))'.split(/(\(|\)|\n|\s+|\S+)/).filter(token => token.trim().length); // ==> ["(", "foo", "bar", "(", "baz))"] مشکل عبارت \S+ است که حریص است و با هر چیزی که فاصله نیست مطابقت دارد. برای رفع مشکل، میتوانیم از این عبارت استفاده کنیم: [^\s()]+ .
با هر چیزی که فاصله و پرانتز نیست مطابقت دارد (همانند \S+ اما
با پرانتز).
(foo bar (baz))'.split(/(\(|\)|\n|\s+|[^\s()]+)/).filter(token => token.trim().length); // ==> ["(", "foo", "bar", "(", "baz", ")", ")"]همانطور که می بینید، خروجی درست است. بیایید این توکنایزر را به عنوان یک تابع بنویسیم:
const tokens_re = /(\(|\)|\n|\s+|[^\s()]+)/; function tokenize(string) { string = string.trim(); if (!string.length) { return []; } return string.split(tokens_re).filter(token => token.trim()); } ما نیازی به استفاده از length بعد از token.trim() نداریم زیرا یک رشته خالی نیز به مقدار false تبدیل می شود و فیلتر آن مقادیر را حذف می کند.
اما در مورد عبارات رشته ای (آنهایی که در نقل قول هستند) چطور؟ ببینیم چی میشه:
tokenize(`(define (square x) "Function calculate square of a number" (* xx))`); // ==> ["(", "define", "(", "square", "x", ")", "\"Function", "calculate", "square", // ==> "of", "a", "number\"", "(", "*", "x", "x", ")", ")"] توجه: این یک تابع در گویش Scheme از Lisp است. ما از الفبای الگو استفاده کردیم،
پس می توانیم کاراکترهای خط جدید را در داخل کد Lisp اضافه کنیم.
همانطور که از خروجی می بینید، تک نیش ها همه با فاصله تقسیم می شوند. بیایید آن را اصلاح کنیم:
عبارات منظم برای رشته ها
ما باید به عنوان یک استثنا به توکنایزر خود، لفظ رشته ای اضافه کنیم. بهترین اولین مورد در اتحادیه در regex ما است.
عبارتی که لفظ رشته ای را کنترل می کند به این صورت است:
/"[^"\\]*(?:\\[\S\s][^"\\]*)*"/نقل قول های فرار را در داخل یک رشته کنترل می کند.
عبارت منظم کامل باید به این صورت باشد:
const tokens_re = /("[^"\\]*(?:\\[\S\s][^"\\]*)*"|\(|\)|\n|\s+|[^\s()]+)/;توجه: ما همچنین میتوانیم نظرات Lisp را اضافه کنیم، اما چون این یک تجزیهکننده Lisp نیست، بلکه یک بیان S است، در اینجا این کار را انجام نمیدهیم. JSON از نظرات نیز پشتیبانی نمی کند. اگر می خواهید یک تجزیه کننده Lisp ایجاد کنید، می توانید آنها را به عنوان تمرین اضافه کنید.
توکنایزر ما اکنون به درستی کار می کند:
tokenize(`(define (square x) "Function calculate square of a number" (* xx))`); // ==> ["(", "define", "(", "square", "x", ")", // ==> "\"Function calculate square of a number\"", // ==> "(", "*", "x", "x", ")", ")"]تجزیه کننده
ما تجزیه کننده خود را با استفاده از ساختار داده پشته (LIFO - Last In First Out) ایجاد می کنیم.
برای درک کامل نحوه عملکرد تجزیه کننده، خوب است در مورد ساختارهای داده مانند فهرست های پیوندی، درختان باینری و پشته ها بدانید.
در اینجا اولین نسخه تجزیه کننده ما است:
function parse(string) { const tokens = tokenize(string); const result = []; // as normal array const stack = []; // as stack tokens.forEach(token => { if (token == '(') { stack.push([]); // add new list to stack } else if (token == ')') { if (stack.length) { // top of the stack is already constructed list const top = stack.pop(); if (stack.length) { // add constructed list to previous list var last = stack[stack.length - 1]; last.push(top); } else { result.push(top); // fully constructed list } } else { throw new Error('Syntax Error - unmached closing paren'); } } else { // found atom add to the top of the stack // top is used as an array we only add at the end const top = stack[stack.length - 1]; top.push(token); } }); if (stack.length) { throw new Error('Syntax Error - expecting closing paren'); } return result; } تابع آرایه ای از ساختارهای ما را به شکل آرایه برمی گرداند. اگر نیاز داریم
برای تجزیه بیش از یک عبارت S، آیتم های بیشتری در یک آرایه خواهیم داشت:
parse(`(1 2 3) (1 2 3)`) // ==> [["1", "2", "3"], ["1", "2", "3"]]اگرچه نیازی به رسیدگی به نقاط نداریم، عبارات S می توانند به این شکل باشند:
((foo . 10) (bar . 20)) ما نیازی به ایجاد ساختار خاصی برای فهرست های خود نداریم تا تجزیه کننده کار کنند. اما داشتن این ساختار از ابتدا ایده خوبی است ( پس می توانید از آن به عنوان پایه ای برای مفسر Lisp استفاده کنید). ما از یک کلاس Pair استفاده خواهیم کرد، پس می توانیم هر درخت دودویی ایجاد کنیم.
class Pair { constructor(head, tail) { this.head = head; this.tail = tail; } } ما همچنین به چیزی نیاز داریم که نمایانگر انتهای فهرست (یا یک فهرست خالی) باشد. در زبان Lisp معمولا nil است:
class Nil {} const nil = new Nil();ما می توانیم یک متد استاتیک ایجاد کنیم که یک آرایه را به ساختار ما تبدیل می کند:
class Pair { constructor(head, tail) { this.head = head; this.tail = tail; } static fromArray(array) { if (!array.length) { return nil; } let [head, ...rest] = array if (head instanceof Array) { head = Pair.fromArray(head); } return new Pair(head, Pair.fromArray(rest)); } }برای اضافه کردن آن به تجزیه کننده خود، تنها کاری که باید انجام دهیم این است که آن را در پایان اضافه کنیم:
result.map(Pair.fromArray); توجه: اگر I بعداً یک عملگر نقطه اضافه کنید، باید جفتها را با دست، در داخل تجزیهکننده ایجاد کنید.
ما کل آرایه را تبدیل نکردیم زیرا این محفظه برای عبارات S ما خواهد بود. هر عنصر در یک آرایه باید یک فهرست باشد، به همین دلیل از Array::map استفاده کردیم.
بیایید ببینیم چگونه کار می کند:
parse('(1 (1 2 3))') خروجی ساختاری مانند این خواهد بود (این خروجی JSON.stringify با مقدار درج شده nil است).
{ "head": "1", "tail": { "head": { "head": "1", "tail": { "head": "2", "tail": { "head": "3", "tail": nil } } }, "tail": nil } } آخرین چیزی که میتوانیم اضافه کنیم این است که با گفت ن یک متد toString به کلاس Pair ، فهرست را stringify :
class Pair { constructor(head, tail) { this.head = head; this.tail = tail; } toString() { const arr = ['(']; if (this.head) { const value = this.head.toString(); arr.push(value); if (this.tail instanceof Pair) { // replace hack for the nested list // because the structure is a tree // and here tail is next element const tail = this.tail.toString().replace(/^\(|\)$/g, ''); arr.push(' '); arr.push(tail); } } arr.push(')'); return arr.join(''); } static fromArray(array) { // ... same as before } }بیایید ببینیم چگونه کار می کند:
parse("(1 (1 2 (3)))")[0].toString() // ==> "(1 (1 2 (3)))"آخرین مشکل این است که ساختار خروجی اعداد ندارد. همه چیز یک رشته است.
تجزیه اتم ها
ما از عبارات منظم زیر استفاده خواهیم کرد:
const int_re = /^[-+]?[0-9]+([eE][-+]?[0-9]+)?$/; const float_re = /^([-+]?((\.[0-9]+|[0-9]+\.[0-9]+)([eE][-+]?[0-9]+)?)|[0-9]+\.)$/; if (atom.match(int_re) || atom.match(float_re)) { // in javascript every number is float but if it's slow you can use parseInt for int_re return parseFloat(atom); } بعد، می توانیم رشته ها را تجزیه کنیم. رشتههای ما تقریباً مشابه رشتههای JSON هستند، تنها تفاوت آنها این است که میتوانند خطوط جدید داشته باشند (معمولاً رشتهها در گویشهای Lisp به این صورت است). پس می توانیم از JSON.parse استفاده کنیم و فقط \n با \\n جایگزین کنیم (گریز از خط جدید).
if (atom.match(/^".*"$/)) { return JSON.parse(atom.replace(/\n/g, '\\n')); } پس با این کار، میتوانیم همه کاراکترهای فرار را به صورت رایگان داشته باشیم (یعنی: \t یا کاراکترهای Unicode \u ).
عنصر بعدی عبارات S نمادها هستند. آنها هر دنباله کاراکتری هستند که عدد یا رشته نیستند. ما می توانیم یک کلاس LSymbol ایجاد کنیم تا از Symbol از جاوا اسکریپت متمایز شود.
class LSymbol { constructor(name) { this.name = name; } toString() { return this.name; } }تابع تجزیه اتم ها می تواند به شکل زیر باشد:
function parseAtom(atom) { if (atom.match(int_re) || atom.match(float_re)) { // numbers return parseFloat(atom); } else if (atom.match(/^".*"$/)) { return JSON.parse(atom.replace(/\n/g, '\\n')); // strings } else { return new LSymbol(atom); // symbols } } تابع تجزیه کننده ما با اضافه کردن parseAtom :
function parse(string) { const tokens = tokenize(string); const result = []; const stack = []; tokens.forEach(token => { if (token == '(') { stack.push([]); } else if (token == ')') { if (stack.length) { const top = stack.pop(); if (stack.length) { const last = stack[stack.length - 1]; last.push(top); } else { result.push(top); } } else { throw new Error('Syntax Error - unmached closing paren'); } } else { const top = stack[stack.length - 1]; top.push(parseAtom(token)); // this line was added } }); if (stack.length) { throw new Error('Syntax Error - expecting closing paren'); } return result.map(Pair.fromArray); } همچنین میتوانیم متد toString را در Pair بهبود دهیم تا از JSON.stringify برای رشتهها برای تشخیص از نمادها استفاده کنیم:
class Pair { constructor(head, tail) { this.head = head; this.tail = tail; } toString() { const arr = ['(']; if (this.head) { let value; if (typeof this.head === 'string') { value = JSON.stringify(this.head).replace(/\\n/g, '\n'); } else { // any object including Pair and LSymbol value = this.head.toString(); } arr.push(value); if (this.tail instanceof Pair) { // replace hack for the nested list because // the structure is a tree and here tail // is next element const tail = this.tail.toString().replace(/^\(|\)$/g, ''); arr.push(' '); arr.push(tail); } } arr.push(')'); return arr.join(''); } static fromArray(array) { // ... same as before } } و این یک تجزیه کننده کامل است. آنچه باقی می ماند مقادیر true و false (و شاید null ) است، اما آنها به عنوان تمرینی برای خواننده باقی می مانند. کد کامل را می توانید در GitHub پیدا کنید.
رویکردهای مختلف برای تجزیه کننده Lisp در جاوا اسکریپت
کد بالا برای پیاده سازی ساده Lisp خوب است. من از کد مشابهی به عنوان اجرای اولیه LIPS Scheme استفاده کردم که هنوز در CodePen یافت می شود.
در حال حاضر، LIPS از Lexer پیشرفته تر (با استفاده از ماشین حالت ) به جای توکنایزر استفاده می کند. Lexer بازنویسی شد زیرا تغییر رویکرد با پشته بسیار دشوار بود.
توجه : این مقاله برای اولین بار در وبلاگ لهستانی Głównie JavaScript (ang. عمدتاً جاوا اسکریپت) ظاهر شد، عنوان مقاله: Parser S-Wyrażeń (języka LISP) w JavaScript .
برچسبها
|
|




ارسال نظر