خبرکاو - جستجوگر هوشمند اخبار و مطالب
سرخط خبر ها

مستند میتواند ارزآوری بسیار خوبی داشته باشد/ توجه به مستند باعث بالاتر رفتن سطح کیفی آثار سینمایی میشود
خبرکاو :محمد زکیزاده: امیرحسین علم الهدی کارشناس و مدیر فرهنگی درباره بهترین راه برای عرضه مستند گفت: همچنان باتوجه به دسترسی راحتتر، خاستگاه اصلی مستند، تلویزیون است. با آمدن سکوهای نمایشی و پلتفرم های اصلی مانند نتفلیکس، اچ بی اُ و... ...
جديدترين اخبار
-

«پدینگتون ۳ » به سرعت از ۱۰۰ میلیون دلار گذشت
«پدینگتون ۳ » به سرعت از ۱۰۰ میلیون دلار گذشت
خبرکاو:به گزارش خبرگزاری خبرآنلاین، در حالی که شماری از سینمادوستان در آخر هفتهای که گذشت به سمت «کاپیتان آمریکا» رفتند اما «پدینگتون در پرو» هم مخاطبان خود را داشت.به گزارش خبرگزاری مهر به نقل از کولیدر، سومین قسمت از این مجموعه محبوب کودکان که با اقتباس از کتابهای مایکل باند ساخته شده، بیش از ۱۰۰ میلیون دلار ...
-

«جشن سپاسِ» تهیهکنندگان در رقابت با جایی نیست/ داوری سه اثر بدون اکران عمومی
«جشن سپاسِ» تهیهکنندگان در رقابت با جایی نیست/ داوری سه اثر بدون اکران عمومی
خبرکاو:به گزارش خبرگزاری خبرآنلاین، نشست خبری چهارمین جشن سپاس تهیه کنندگان سینمای ایران با حضور سیدضیا هاشمی رئیس جامعه صنفی تهیه کنندگان، مهدی کرمپور کارگردان سینما و سخنگوی جامعه صنفی و مجید کریمی دبیر چهارمین آکادمی سپاس تهیه کنندگان و جمعی از اصحاب رسانه در جامعه صنفی تهیهکنندگان برگزار شد.به گزارش ایرنا، در این جلسه سیدضیا هاشمی درباره چهارمین جشن سپاس گفت: ...
-

بازدید هیات سینمایی هند از موزه سینما
بازدید هیات سینمایی هند از موزه سینما
خبرکاو:به گزارش خبرگزاری خبرآنلاین به نقل از روابط عمومی موزه سینما، در این دیدار موهان داس دبیر جشنواره lake city، ارهان جمال نویسنده،کارگردان و پخشکننده فیلم، شانموگام دبیر جشنواره بینالمللی فیلم چنای را همراهی کردند. ذاکر حسین شیخ کارشناس سینمایی خانه فرهنگ ج.ا.ایران، مهدی صالحی رئیس اداره همکاریهای رادیویی، تلویزیونی و مطبوعاتی سازمان فرهنگ و ارتباطات ...
-

«رها»؛ تسلسل رنجهای بیپایان
«رها»؛ تسلسل رنجهای بیپایان
خبرکاو:سراسر فیلم با رنج حاصل از چنین تقابل و جدالی با مسائل و معضلات آنها میگذرد. پدر خانواده تلاش میکند با توانی اندک، سر و ته مشکلاتی عمیق را خیلی ساده و سطحی هم بیاورد و اوضاع را سر و سامان بدهد، اما شوربختانه بهجز دامن زدن به آنها، کاری از پیش نمیبرد. او به ...
-

فرامرز قریبیان، نعمت حقیقی و سعید پیردوست پشت صحنه «گوزنها» مسعود کیمیایی/ عکس
فرامرز قریبیان، نعمت حقیقی و سعید پیردوست پشت صحنه «گوزنها» مسعود کیمیایی/ عکس
خبرکاو:[ez-toc] فرامرز قریبیان قهرمان گوزنها به گزارش خبرگزاری خبرآنلاین، فرامرز قریبیان قهرمان گوزنها است و بازی او در این فیلم یکی از عوامل شهرت فراگیر او شد؛ اگرچه قریبیان پیش از این تجربه بازیگری برای ساموئل خاچکیان و کیمیایی داشت؛ اما گوزن ها نقطه عطف بازیگری او بود. سعید پیردوست در فیلم گوزن ها در صحنه پاسگاه حاضر است ...
-

سریال محمدعلی کلی یک گام جلو رفت؛ انتخاب بازیگران
سریال محمدعلی کلی یک گام جلو رفت؛ انتخاب بازیگران
خبرکاو: به گزارش خبرگزاری خبرآنلاین، اومری هاردویک و دانا گوریر به سریال «بزرگترین» پیوستهاند که اولین سریال با فیلمنامه تایید شده از سوی بنیاد محمدعلی کلی درباره زندگی این مشتزن فراموش نشدنی است. این ۲ در کنار جیلین بست که پیشتر به عنوان بازیگر اصلی سریال معرفی شده بود، در این مجموعه تلویزیونی بازی خواهند کرد. به ...
-

برلیناله سیاسی شروع کرد؛ اعتراض تیلدا سوینتون و تاد هینز به ترامپ
برلیناله سیاسی شروع کرد؛ اعتراض تیلدا سوینتون و تاد هینز به ترامپ
خبرکاو:به گزارش خبرگزاری خبرآنلاین، تیلدا سوینتون در مراسم افتتاحیه هفتاد و پنجمین جشنواره بین المللی فیلم برلیناله که دیشب برگزار شد، با دریافت خرس طلایی افتخاری برای یک عمر دستاورد هنری تجلیل شد.به گزارش خبرگزاری مهر به نقل از ورایتی،وی در حالی که جایزه خود را در دست گرفته بود، در سخنانی به خشونت دنیای امروز اعتراض کرد ...
-

بازیگر مشهور زندانبان میشود
بازیگر مشهور زندانبان میشود
خبرکاو:به گزارش خبرگزاری خبرآنلاین، ایتن هاوک و راسل کرو برای بازی در فیلم «سنگینی» فرارداد امضا کرده اند تا در این درام تاریخی مربوط به دهه ۱۹۳۰ نقشآفرینی کنند.در این فیلم که داستانش در سال ۱۹۳۳ در اورگان اتفاق میافتد، هاوک در نقش ساموئل مورفی بازی میکند که پس از مرگ همسرش، به زندان میافتد ...
-

احضار دو کارگردان سینما به دادگاه /اتهام: تبلیغ علیه نظام ، تولید و تکثیر فیلم با محتوای مبتذل
احضار دو کارگردان سینما به دادگاه /اتهام: تبلیغ علیه نظام ، تولید و تکثیر فیلم با محتوای مبتذل
خبرکاو:به گزارش خبرگزاری خبرآنلاین، مریم مقدم و بهتاش صناعیها، سازندگان فیلم «کیک محبوب من» به دادگاه احضار شدند.به گزارش شرق؛ مریم مقدم و بهتاش صناعیها، سازندگان فیلم «کیک محبوب من»، با انتشار ابلاغیه رسمی قوه قضائیه جمهوری اسلامی خبر دادند قرار است ۱۱ اسفند به اتهامهایی چون «تبلیغ علیه نظام، تهیه و تولید و تکثیر ...
-

جزئیات تازه از فیلم قاتل و وحشی به روایت لیلا حاتمی
جزئیات تازه از فیلم قاتل و وحشی به روایت لیلا حاتمی
خبرکاو:به گزارش خبرگزاری خبرآنلاین، لیلا حاتمی، بازیگر فیلم قاتل و وحشی در یک گفتوگوی صوتی با آرمین میلادی جزئیاتی از این فیلم جنجالی را بازگو کرد و گفت: هنوز به طور کامل این فیلم را ندیدم اما میتوانم بگویم این فقط یک فیلم است و خشونتی که در آن وجود دارد خیلی نیست و در برابر ...
-

تاثیر برادران کارامازوف و ابله داستایوفسکی در سینمای ایران و جهان
تاثیر برادران کارامازوف و ابله داستایوفسکی در سینمای ایران و جهان
خبرکاو:[ez-toc] تاثیر برادران کارامازوف و ابله داستایوفسکی در سینمای ایران و جهان فئودور داستایوفسکی در «برادران کارامازوف» و «ابله» شخصیتهایی را خلق میکند که در عمیقترین لایههای روان انسان، در نبردی دائمی میان خیر و شر دستوپا میزنند. این دو اثر سرشار از کشمکشهای فلسفی، روانشناختی و اخلاقیاند؛ جایی که شخصیتها بیش از آنکه بهدنبال تغییر دنیای ...
-

ایتن هاوک دلیل به تعویق افتادن ۱۲ ساله «ماه آبی» را فاش کرد
ایتن هاوک دلیل به تعویق افتادن ۱۲ ساله «ماه آبی» را فاش کرد
خبرکاو:به گزارش خبرگزاری خبرآنلاین، ایتن هاوک برای اولین بار درباره جدیدترین فیلم مشترک خود با ریچارد لینکلیتر صحبت کرد و فاش کرد که برای اولین بار فیلمنامه «ماه آبی» را که با تمرکز بر زندگینامه لورنز هارت نوشته شده، ۱۲ سال پیش خواند.به گزارش خبرگزاری مهر به نقل از ورایتی، وی وقتی فیلمنامه را خواند گفت آن ...
-

طعنه کیهان به ضرغامی: مگر مدیر سابق رسانهای میتواند داور خوبی برای جشنواره فیلم فجر باشد؟
طعنه کیهان به ضرغامی: مگر مدیر سابق رسانهای میتواند داور خوبی برای جشنواره فیلم فجر باشد؟
خبرکاو: به گزارش خبرآنلاین، روزنامه کیهان نوشت: طبعا یک تدوینگر یا فیلمبردار یا مدیر اسبق رسانه ملی و یا سینمایینویس و... نمیتوانند در این فرصت محدود و از میان این تعداد زیاد فیلم و تعدد شاخههای سینمایی و عدم تخصص در بسیاری از آنها مانند صدا و جلوههای ویژه و موسیقی و طراحی صحنه ...
-

اپل با راه اندازی یک برنامه شریک جدید، SMB، سازمانی را به عنوان جریان درآمد اصلی بعدی خود در نظر می گیرد
اپل با راه اندازی یک برنامه شریک جدید، SMB، سازمانی را به عنوان جریان درآمد اصلی بعدی خود در نظر می گیرد
خبرکاو: (اعتبار تصویر: اپل) اپل قصد دارد یک سیستم دیجیتالی جدید را برای همکاری آسان با شرکا راه اندازی کند شرکای اپل برای تبدیل شدن به مشاوران قابل اعتماد آموزش خواهند دید شرکای اپل از برنامه جدید به عنوان یک تغییر دهنده بازی استقبال می کنند اپل به دنبال کسب و کارهای کوچک و متوسط ...
-

از ترانه علیدوستی تا ژولیت رضاعی/ میترسم بخوابم داداش! تو خواب یکی هست میافته دنبالم…/صحنه هایی از فیلم «زیبا صدایم کن» توی ذوق می زند
از ترانه علیدوستی تا ژولیت رضاعی/ میترسم بخوابم داداش! تو خواب یکی هست میافته دنبالم…/صحنه هایی از فیلم «زیبا صدایم کن» توی ذوق می زند
خبرکاو:به گزارش خبرگزاری خبرانلاین، مقصود فراستخواه، جامعهشناس در یادداشتی در روزنامه هم میهن به نقد و بررسی فیلم «زیبا صدایم کن» رسول صدرعاملی که در جشنواره فیلم فجر امسال به نمایش درآمد پرداخته و نوشته است؛میترسم بخوابم داداش! تو خواب یکی هست میافته دنبالم... فیلمی در ژانر سینمای آموزشی، سینمای نوجوان. یک «معرفی نسلی» از صدرعاملی ...
-
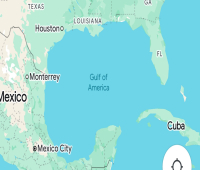
Google Maps و Apple Maps خلیج مکزیک را به خلیج آمریکا تغییر نام دادند و من خیلی گیج شدم
Google Maps و Apple Maps خلیج مکزیک را به خلیج آمریکا تغییر نام دادند و من خیلی گیج شدم
خبرکاو: (اعتبار تصویر: آینده) من دوست دارم کسی را تصور کنم که در خلیج مکزیک شنا می کند، زمانی که گوگل نام آن را بدون تشریفات به خلیج آمریکا تغییر داد. آنها آنجا هستند، در حالی که کلمات غولپیکر از آسمان شناور میشوند و بر بالای آنها فرود میآیند، روی آبهای سبز و آبی بکر ...
-

انتقاد از مصرف تریاک و سیگار در فیلم های جشنواره فجر/صددام، کفایت مذاکرات یا تاکسیدرمی چرا به جشنواره آمدند؟/ فیلم«پیر پسر» فرسنگ ها از بقیه جلوتر بود
انتقاد از مصرف تریاک و سیگار در فیلم های جشنواره فجر/صددام، کفایت مذاکرات یا تاکسیدرمی چرا به جشنواره آمدند؟/ فیلم«پیر پسر» فرسنگ ها از بقیه جلوتر بود
خبرکاو: به گزارش خبرگزاری خبرآنلاین، روزنامه جوان نوشت: انتخاب زیاد فیلم در جشنواره فجر افتخار نیست و اینکه فیلمهای بیکیفیت را در جشنواره بپذیریم اعتبار محسوب نمیشود. به نظر میرسد دبیر ...
-

با یادی از بهروز وثوقی، حسن پورشیرازی و حضور عنایت بخشی؛ سیمرغ روی شانه ستارهها نشست
با یادی از بهروز وثوقی، حسن پورشیرازی و حضور عنایت بخشی؛ سیمرغ روی شانه ستارهها نشست
خبرکاو:به گزارش خبرگزاری خبرآنلاین، فیلم سینمایی «موسی کلیمالله» به کارگردانی ابراهیم حاتمی کیا با دریافت پنج جایزه شامل سیمرغ بلورین بهترین بازیگر نقش مکمل مرد، بهترین طراحی لباس،بهترین طراحی صحنه، بهترین چهرهپردازی و بهترین دستاورد فنی در چهل و سومین جشنواره فیلم فجر بیشترین جوایز را از آن خود کرد.در همین حال، جایزه بهترین فیلم ...
-

پلید با گلدمن ساکس برای جمع آوری 300 میلیون دلار به 400 میلیون دلار در مناقصه کار می کند.
پلید با گلدمن ساکس برای جمع آوری 300 میلیون دلار به 400 میلیون دلار در مناقصه کار می کند.
خبرکاو: به گزارش بلومبرگ به نقل از منابع، Plaid، شرکتی که حسابهای بانکی را به برنامههای مالی متصل میکند، با گلدمن ساکس روی معاملهای کار میکند تا به سرمایهگذاران و کارمندان در مراحل اولیه اجازه دهد سهام موجود را بفروشند که بین 300 تا 400 میلیون دلار افزایش مییابد. پیشنهاد مناقصه، همانطور که چنین معاملاتی ...
-

اینها سرمایه گذارانی هستند که تلاش 97 میلیارد دلاری ماسک برای تصاحب OpenAI را تامین می کنند
اینها سرمایه گذارانی هستند که تلاش 97 میلیارد دلاری ماسک برای تصاحب OpenAI را تامین می کنند
خبرکاو: انگار ایلان ماسک به اندازه کافی در جریان نیست، کنسرسیومی از سرمایه گذاران به رهبری او دوشنبه برنامه هایی را برای آنچه که به نظر می رسد تصرف خصمانه OpenAI است، اعلام کردند. در یک بیانیه مطبوعاتی که به TechCrunch ارسال شده است، گفت که گروه سرمایهگذار نزدیک به 97.4 میلیارد دلار برای خرید ...
