ماشین مجازی جاوا در تمام روز چه کار می کند؟
این مقاله در اصل توسط Ampere Computing منتشر شده است.
من یک پست وبلاگ در مورد gprofng ، یک ابزار جدید پروفایل گنو دیدم. مثال در آن وبلاگ یک برنامه ضرب ماتریس-بردار بود که به زبان C نوشته شده بود. من یک برنامه نویس Java™ هستم، و نمایه سازی برنامه های کاربردی جاوا اغلب با ابزارهایی که برای برنامه های C کامپایل شده ایستا طراحی شده اند، به جای برنامه های جاوا که کامپایل می شوند، دشوار است. در زمان اجرا در این وبلاگ نشان میدهم که استفاده gprofng آسان است و برای تحلیل رفتار پویا یک برنامه جاوا مفید است.
اولین قدم نوشتن یک برنامه ضرب ماتریس بود. من یک برنامه کامل matrix-times-matrix نوشتم زیرا دشوارتر از matrix-times-vector نیست. سه روش اصلی وجود دارد: یک روش برای محاسبه درونی ترین ضرب- گفت ن، یک روش برای ترکیب ضرب- گفت ن در یک عنصر واحد از نتیجه، و یک روش برای تکرار محاسبه هر عنصر از نتیجه.
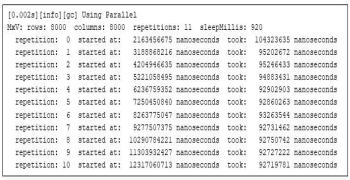
من محاسبات را در یک مهار ساده پیچیدم تا محصول ماتریس را به طور مکرر محاسبه کنم تا مطمئن شوم زمان ها قابل تکرار هستند. (به یادداشت پایانی 1 مراجعه کنید.) برنامه زمانی که هر ضرب ماتریس شروع می شود (نسبت به شروع ماشین مجازی جاوا)، و مدت زمان ضرب هر ماتریس را چاپ می کند. در اینجا من تست را برای ضرب دو ماتریس 8000×8000 اجرا کردم. مهار محاسبات را 11 بار تکرار می کند و برای برجسته کردن بهتر رفتار بعداً، 920 میلی ثانیه بین تکرارها می خوابد:
$ numactl --cpunodebind = 0 --membind = 0 -- \ java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc -XX:-UsePerfData \ MxV -m 8000 -n 8000 -r 11 -s 920 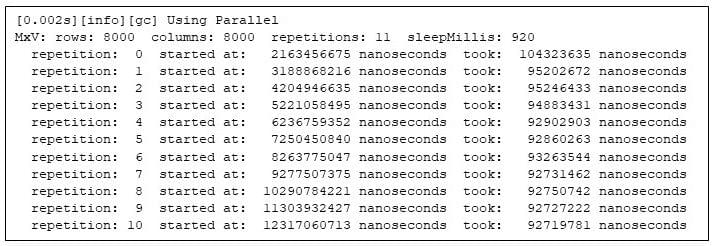
شکل 1: اجرای برنامه ضرب ماتریس
توجه داشته باشید که تکرار دوم 92 درصد از زمان تکرار اول را می گیرد و آخرین تکرار تنها 89 درصد از تکرار اول را می گیرد. این تغییرات در زمان اجرا تأیید می کند که برنامه های جاوا به مدتی برای گرم شدن نیاز دارند.
سوال این است: آیا می توانم از gprofng استفاده کنم تا ببینم بین اولین تکرار و آخرین تکرار چه اتفاقی می افتد که باعث بهبود عملکرد می شود؟
یک راه برای پاسخ به این سوال این است که برنامه را اجرا کنید و به gprofng اجازه دهید اطلاعات مربوط به اجرا را جمع آوری کند. خوشبختانه، این آسان است: من به سادگی خط فرمان را با یک دستور gprofng پیشوند می کنم تا آنچه gprofng آن را "آزمایش" می نامد جمع آوری کند:
$ numactl --cpunodebind = 0 --membind = 0 -- \ gprofng collect app \ java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc --XX:-UsePerfData \ MxV -m 8000 -n 8000 -r 11 -s 920 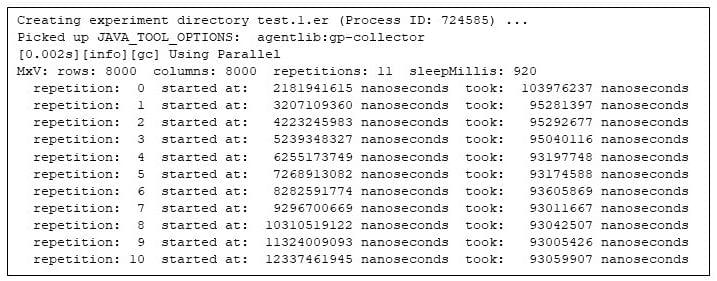
شکل 2: اجرای برنامه ضرب ماتریس تحت gprofng
اولین چیزی که باید به آن توجه کرد، مانند هر ابزار پروفایل، هزینهای است که جمعآوری اطلاعات نمایهسازی به برنامه تحمیل میکند. در مقایسه با اجرای بدون پروفایل قبلی، به نظر می رسد gprofng هیچ سربار قابل توجهی را تحمیل نمی کند.
سپس می توانم gprofng بپرسم که زمان در کل برنامه چگونه سپری شده است. (نکته پایانی 2 را ببینید.) برای کل اجرا، gprofng می گوید که داغ ترین 24 روش عبارتند از:
$ gprofng display text test.1.er -viewmode expert -limit 24 -functions 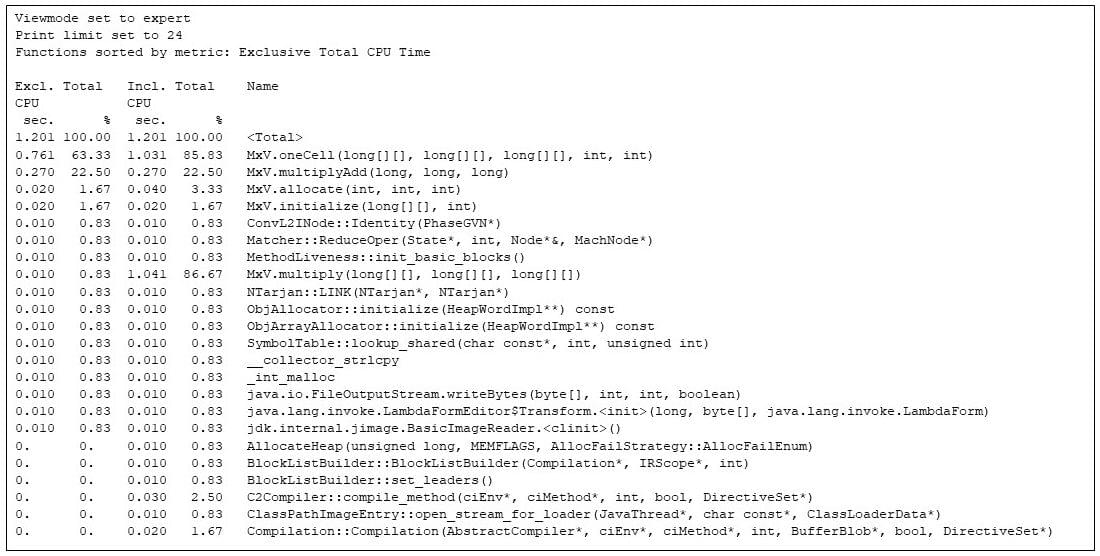 از داغترین 24 روش" loading="lazy">
از داغترین 24 روش" loading="lazy">
شکل 3: نمایش Gprofng از داغترین 24 روش
نمای توابع نشان داده شده در بالا، زمانهای منحصر به فرد و شامل CPU را برای هر روش، هم بر حسب ثانیه و هم به صورت درصدی از کل زمان CPU نشان میدهد. تابع نامگذاری شده یک تابع شبه است که توسط gprofng تولید می شود و مقدار کل معیارهای مختلف را دارد. در این حالت من می بینم که کل زمان CPU صرف شده در کل برنامه 1.201 ثانیه است.
متدهای برنامه (روشهای کلاس MxV ) در آنجا هستند و اکثریت زمان CPU را اشغال میکنند، اما روشهای دیگری نیز وجود دارد، از جمله کامپایلر زمان اجرا JVM ( Compilation::Compilation ). و توابع دیگری که بخشی از ضریب ماتریس نیستند. این نمایش از کل اجرای برنامه کدهای تخصیص ( MxV.allocate ) و مقداردهی اولیه ( MxV.initialize ) را ضبط می کند، که من کمتر به آنها علاقه مند هستم زیرا بخشی از مهار تست هستند، فقط در هنگام راه اندازی استفاده می شوند و مقدار کمی دارند. برای انجام ضرب ماتریس.
من می توانم از gprofng برای تمرکز روی قسمت هایی از برنامه که به آنها علاقه دارم استفاده کنم. یکی از ویژگی های فوق العاده gprofng این است که پس از جمع آوری یک آزمایش، می توانم فیلترهایی را روی داده های جمع آوری شده اعمال کنم. به عنوان مثال، برای نگاه کردن به آنچه در یک بازه زمانی خاص اتفاق میافتد، یا زمانی که یک روش خاص در پشته تماس است. برای اهداف نمایشی و آسانتر کردن فیلتر کردن، تماسهای استراتژیک را به Thread.sleep(ms) اضافه کردم تا نوشتن فیلترها بر اساس فازهای برنامه که با فواصل یک ثانیهای از هم جدا شدهاند آسانتر شود. به همین دلیل است که خروجی برنامه بالا در شکل 1 هر تکرار با حدود یک ثانیه از هم فاصله دارد حتی اگر هر مضرب ماتریس فقط حدود 0.1 ثانیه طول بکشد.
gprofng قابل اسکریپت است، پس من یک اسکریپت نوشتم تا چند ثانیه از آزمایش gprofng استخراج شود. ثانیه اول همه چیز در مورد راه اندازی ماشین مجازی جاوا است.
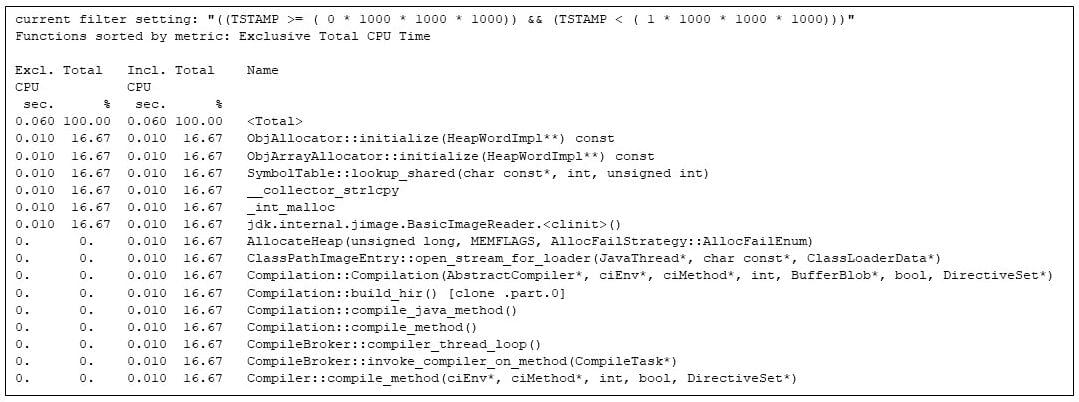 به طور مصنوعی در این ثانیه به تعویق افتاده است تا به من اجازه دهد JVM را برای راه اندازی نشان دهم" loading="lazy">
به طور مصنوعی در این ثانیه به تعویق افتاده است تا به من اجازه دهد JVM را برای راه اندازی نشان دهم" loading="lazy">
شکل 4: فیلتر کردن داغ ترین روش ها در ثانیه اول. ضرب ماتریس به طور مصنوعی در این ثانیه به تعویق افتاده است تا به من اجازه دهد JVM را برای راه اندازی نشان دهم
میتوانم ببینم که کامپایلر زمان اجرا شروع به کار میکند (به عنوان مثال، Compilation::compile_java_method ، 16 درصد از زمان CPU را میگیرد)، حتی اگر هیچیک از روشهای برنامه اجرا نشده باشد. (تماسهای ضرب ماتریس با تماسهای خوابی که من وارد کردم به تأخیر میافتد.)
بعد از اولین ثانیه، یک ثانیه است که در طی آن روشهای تخصیص و مقداردهی اولیه، همراه با روشهای مختلف JVM اجرا میشوند، اما هیچ یک از کدهای ضرب ماتریس هنوز شروع نشده است.
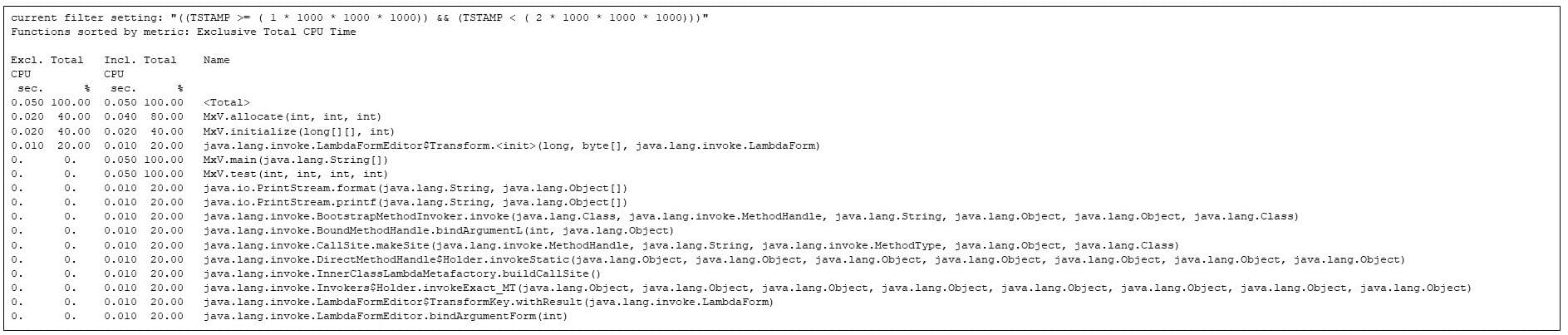
شکل 5: داغ ترین روش ها در ثانیه دوم. تخصیص و مقداردهی اولیه ماتریس در حال رقابت با راه اندازی JVM است
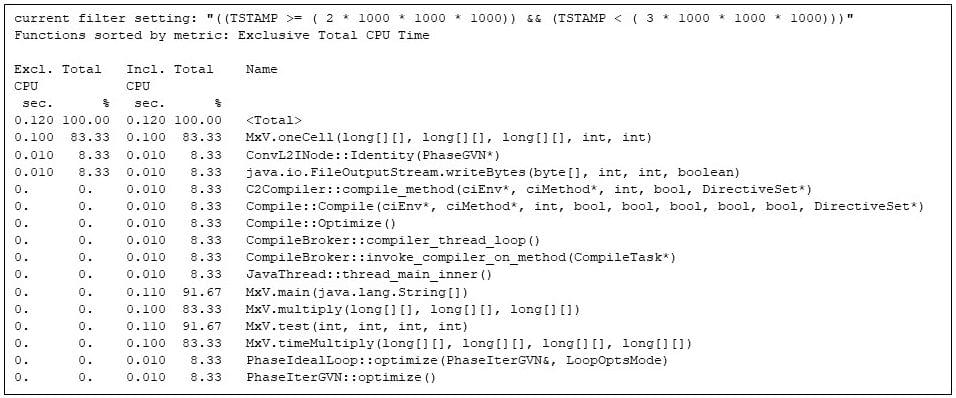
اکنون که راه اندازی JVM و تخصیص و مقداردهی اولیه آرایه ها به پایان رسیده است، ثانیه سوم دارای اولین تکرار کد ضرب ماتریس است که در شکل 6 نشان داده شده است. اما توجه داشته باشید که کد ضرب ماتریس در حال رقابت برای منابع ماشین با کامپایلر زمان اجرا جاوا است. (به عنوان مثال، CompileBroker::invoke_compiler_on_method ، 8% در شکل 6)، که در حال کامپایل کردن روش ها است زیرا کد ضرب ماتریس داغ است.
با این حال، کد ضرب ماتریس (به عنوان مثال، زمان "شامل" در روش MxV.main ، 91٪، بخش عمده ای از زمان CPU را دریافت می کند. زمان فراگیر می گوید که ضرب ماتریس (مثلا MxV.multiply ) 0.100 ثانیه CPU طول می کشد، که با زمان دیواری گزارش شده توسط برنامه در شکل 2 مطابقت دارد. زمان CPU gprofng به MxV.multiply می شود.)
 که کامپایلر زمان اجرا با روش های ضرب ماتریس رقابت می کند." loading="lazy">
که کامپایلر زمان اجرا با روش های ضرب ماتریس رقابت می کند." loading="lazy">
شکل 6: داغ ترین روش ها در ثانیه سوم، نشان می دهد که کامپایلر زمان اجرا با روش های ضرب ماتریس رقابت می کند.
در این مثال خاص، ضرب ماتریس واقعاً برای زمان CPU رقابت نمی کند، زیرا آزمایش بر روی یک سیستم چند پردازنده با تعداد زیادی چرخه بیکار اجرا می شود و کامپایلر زمان اجرا به عنوان رشته های جداگانه اجرا می شود. در شرایط محدودتر، به عنوان مثال در یک ماشین مشترک با بارگذاری سنگین، ممکن است 8 درصد از زمان صرف شده در کامپایلر زمان اجرا مشکل ساز باشد. از سوی دیگر، زمان صرف شده در کامپایلر زمان اجرا، پیادهسازی کارآمدتری از روشها را ایجاد میکند، پس اگر من چندین ضربهای ماتریس را محاسبه کنم، سرمایهگذاری است که مایل به انجام آن هستم.
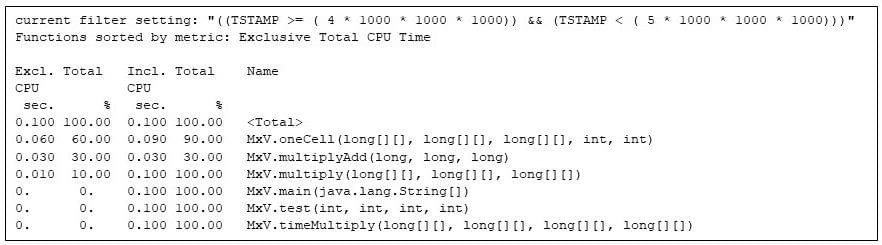
تا پنجمین ثانیه کد ضرب ماتریسی ماشین مجازی جاوا را به خود اختصاص می دهد.
 که فقط روش های ضرب ماتریسی فعال هستند." loading="lazy">
که فقط روش های ضرب ماتریسی فعال هستند." loading="lazy">
شکل 7: تمام روش های در حال اجرا در ثانیه پنجم، نشان می دهد که فقط روش های ضرب ماتریسی فعال هستند.
به تقسیم 60%/30%/10% در ثانیه های CPU انحصاری بین MxV.oneCell ، MxV.multiplyAdd و MxV.multiply توجه کنید. روش MxV.multiplyAdd به سادگی یک ضرب و یک جمع را محاسبه می کند: اما درونی ترین روش در ضرب ماتریس است. MxV.oneCell یک حلقه دارد که MxV.multiplyAdd را فراخوانی می کند. من می توانم ببینم که سربار حلقه و فراخوانی (ارزیابی شرطی ها و انتقال کنترل) نسبتاً کار بیشتری نسبت به محاسبات مستقیم در MxV.multiplyAdd دارند. (این تفاوت در زمان انحصاری برای MxV.oneCell در 0.060 ثانیه CPU منعکس می شود، در مقایسه با 0.030 ثانیه CPU برای MxV.multiplyAdd .) حلقه بیرونی در MxV.multiply به ندرت اجرا می شود که کامپایلر زمان اجرا هنوز آن را کامپایل نکرده است. آن روش از 0.010 ثانیه CPU استفاده می کند.
ضربهای ماتریس تا ثانیه نهم ادامه مییابد، زمانی که کامپایلر زمان اجرا JVM دوباره شروع میشود و متوجه شد که MxV.multiply داغ شده است.
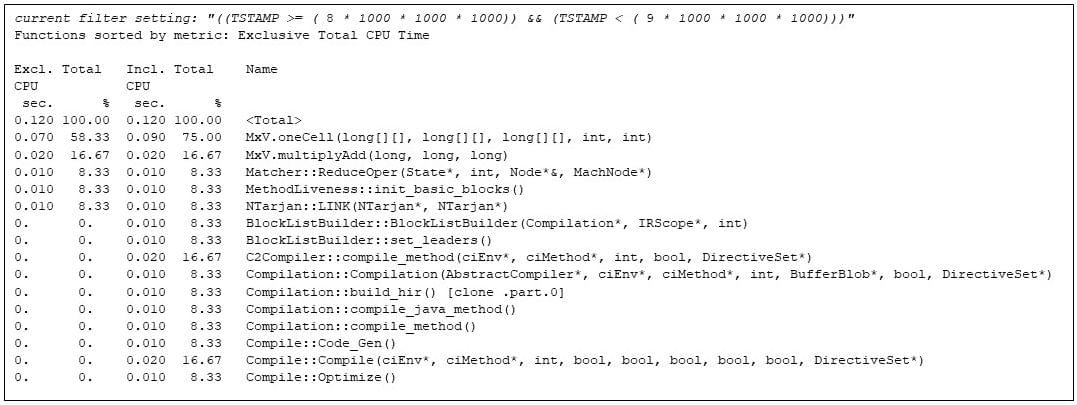 که کامپایلر زمان اجرا دوباره وارد شده است. " loading="lazy">
که کامپایلر زمان اجرا دوباره وارد شده است. " loading="lazy">
با تکرار نهایی، کد ضرب ماتریس به طور کامل از ماشین مجازی جاوا استفاده می کند.
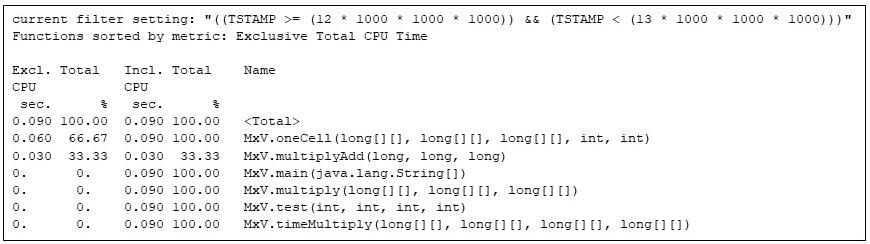 که پیکربندی نهایی کد را نشان می دهد." loading="lazy">
که پیکربندی نهایی کد را نشان می دهد." loading="lazy">
شکل 9: تکرار نهایی برنامه ضرب ماتریس که پیکربندی نهایی کد را نشان می دهد.
نتیجه
من نشان دادهام که با نمایهسازی با gprofng چقدر میتوان بینش در مورد زمان اجرا برنامههای جاوا به دست آورد. استفاده از ویژگی فیلتر کردن gprofng برای تحلیل یک آزمایش بر اساس برش های زمانی به من این امکان را داد که فقط مراحل برنامه مورد علاقه را تحلیل کنم. به عنوان مثال، حذف مراحل تخصیص و مقداردهی اولیه برنامه، و نمایش تنها یک تکرار از برنامه در حالی که کامپایلر زمان اجرا در حال کار با جادوی خود است، که به من این امکان را داد تا عملکرد بهبود یافته را با کامپایل شدن تدریجی کد داغ برجسته کنم.
بیشتر خواندن
برای خوانندگانی که میخواهند درباره gprofng بیشتر بیاموزند، این پست وبلاگ با یک ویدیوی مقدماتی در مورد gprofng ، شامل دستورالعملهایی در مورد نحوه نصب آن در لینوکس اوراکل وجود دارد.
سپاسگزاریها
از رود وان در پاس، کورت گوبل و ولادیمیر مزنتسف برای پیشنهادات و پشتیبانی فنی، و از النا زانونی، دیوید بانمن، کریگ هاردی و دیو نیری برای تشویق من به نوشتن این وبلاگ تشکر می کنم.
یادداشت های پایانی
1. انگیزه های اجزای خط فرمان برنامه عبارتند از:
numactl --cpunodebind=0 --membind=0 -- . حافظه مورد استفاده توسط ماشین مجازی جاوا را به هسته ها و حافظه یک گره NUMA محدود کنید. محدود کردن JVM به یک گره، تنوع اجرا به اجرا برنامه را کاهش می دهد.
java . من از بیلد OpenJDK jdk-17.0.4.1 برای aarch64 استفاده می کنم.
-XX:+UseParallelGC . جمعآوری زباله موازی را فعال کنید، زیرا کمترین کار پسزمینه جمعآوریکنندههای موجود را انجام میدهد.
-Xms31g -Xmx31g . فضای هپ شی جاوا کافی را فراهم کنید تا هرگز به جمع آوری زباله نیاز نداشته باشید.
-Xlog:gc . فعالیت GC را ثبت کنید تا تأیید کنید که مجموعه واقعاً مورد نیاز نیست. ("اعتماد کن اما تایید کن.")
-XX: -UsePerfData . سربار ماشین مجازی جاوا را پایین بیاورید.
2. توضیحات گزینه های gprofng عبارتند از:
-limit 24 . فقط 24 روش برتر را نشان دهید (در اینجا بر اساس زمان اختصاصی CPU مرتب شده است). من می توانم ببینم که نمایش 24 روش، من را به خوبی وارد روش هایی می کند که تقریباً از زمان استفاده نمی کنند. بعداً از محدودیت 16 در جاهایی استفاده خواهم کرد که در آن 16 روش به روش هایی ختم می شود که به مقدار ناچیزی از زمان CPU کمک می کنند. در برخی از مثالها، gprofng خود نمایشگر را محدود میکند، زیرا روشهای زیادی برای جمعآوری زمان وجود ندارد.
-viewmode expert همه روشهایی که زمان CPU را جمعآوری میکنند، نه فقط روشهای جاوا، از جمله روشهایی که بومی خود JVM هستند را نشان دهید. استفاده از این پرچم به من امکان می دهد تا متدهای کامپایلر زمان اجرا و غیره را ببینم.
برچسبها
|
|



ارسال نظر