آموزش طبقه بندی باینری با TensorFlow
طبقه بندی باینری یک وظیفه اساسی در یادگیری ماشینی است که هدف آن دسته بندی داده ها به یکی از دو کلاس یا دسته است.
طبقهبندی باینری در طیف گستردهای از برنامهها مانند شناسایی ایمیلهای اسپم، تشخیص پزشکی، تجزیه و تحلیل احساسات، تشخیص تقلب و بسیاری موارد دیگر استفاده میشود.
در این مقاله، طبقهبندی باینری را با استفاده از TensorFlow، یکی از محبوبترین کتابخانههای یادگیری عمیق، تحلیل میکنیم.
قبل از ورود به طبقه بندی باینری، اجازه دهید کمی در مورد مشکل طبقه بندی در یادگیری ماشین بحث کنیم.
مشکل طبقه بندی چیست؟
مشکل طبقه بندی نوعی از یادگیری ماشینی یا مسئله آماری است که در آن هدف، اختصاص یک دسته یا برچسب به مجموعه ای از داده های ورودی بر اساس ویژگی ها یا ویژگی های آنه است. هدف این است که یک نقشه برداری بین داده های ورودی و کلاس ها یا دسته های از پیش تعریف شده را بیاموزیم و سپس از این نگاشت برای پیش بینی برچسب های کلاس نقاط داده جدید و نادیده استفاده کنیم.
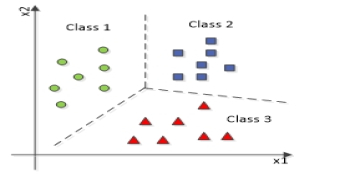
نمودار بالا یک مسئله چند طبقه بندی را نشان می دهد که در آن داده ها به بیش از دو (در اینجا سه) نوع کلاس طبقه بندی می شوند.
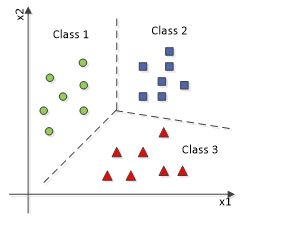
این نمودار طبقه بندی باینری را تعریف می کند که در آن داده ها به دو نوع کلاس طبقه بندی می شوند.
همین مفهوم ساده برای درک مسائل طبقه بندی کافی است. بیایید این را با یک مثال واقعی تحلیل کنیم.
پیش بینی تجزیه و تحلیل حمله قلبی با استفاده از طبقه بندی باینری
در این مقاله، ما سفر ساخت یک مدل پیشبینیکننده برای تجزیه و تحلیل حمله قلبی را با استفاده از کتابخانههای یادگیری عمیق ساده آغاز خواهیم کرد.
مدلی که میسازیم، در حالی که یک شبکه عصبی نسبتاً ساده است، میتواند به سطح دقت تقریباً ۸۰ درصد دست یابد.
حل مسائل دنیای واقعی از طریق لنز یادگیری ماشینی مستلزم یک سری مراحل ضروری است:
جمع آوری داده ها و تجزیه و تحلیل
پیش پردازش داده ها
مدل ML ساختمان
مدل را آموزش دهید
پیش بینی و ارزیابی
جمع آوری داده ها و تجزیه و تحلیل
شایان ذکر است که برای این پروژه، مجموعه داده را از Kaggle ، یک پلتفرم محبوب برای مسابقات علم داده و مجموعه داده ها، به دست آوردم.
توصیه می کنم به محتویات آن نگاه کنید. درک مجموعه داده بسیار مهم است، زیرا به شما امکان می دهد تفاوت های ظریف و پیچیدگی داده ها را درک کنید، که می تواند به شما در تصمیم گیری آگاهانه در سراسر خط لوله یادگیری ماشین کمک کند.
این مجموعه داده به خوبی ساختار یافته است و نیازی فوری به تجزیه و تحلیل بیشتر ندارد. با این حال، اگر به تنهایی مجموعه داده را جمع آوری می کنید، برای دستیابی به دقت بهتر، باید تجزیه و تحلیل داده ها و تجسم را به طور مستقل انجام دهید.
بیایید کفش های کدنویسی خود را بپوشیم.
در اینجا من از Google Colab استفاده می کنم. برای اجرای نوت بوک می توانید از دستگاه خود (در این صورت باید یک فایل .ipynb بسازید) یا Google Colab در حساب خود استفاده کنید. شما می توانید کد منبع من را اینجا پیدا کنید.
به عنوان اولین قدم، بیایید کتابخانه های مورد نیاز را وارد کنیم.
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split import sklearn import pandas as pd import keras from keras.models import Sequential from keras.layers import Dense import tensorflow as tf from sklearn.metrics import confusion_matrix,ConfusionMatrixDisplay from sklearn.preprocessing import MinMaxScalerمن مجموعه داده را در درایو خود دارم و آن را از درایو خود می خوانم. شما می توانید همان مجموعه داده را از اینجا دانلود کنید.
مسیر فایل خود را به روش read_csv جایگزین کنید:
df = pd.read_csv("/content/drive/MyDrive/Datasets/heart.csv") df.head()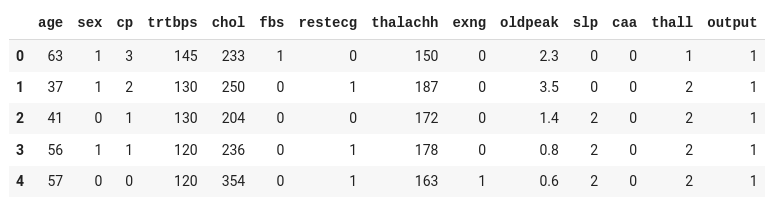
مجموعه داده شامل سیزده ستون ورودی (سن، جنس، cp و غیره) و یک ستون خروجی ( output ) است که شامل داده ها به صورت ۰ یا ۱ خواهد بود.
با در نظر گرفتن خوانش های ورودی، ۰ در output نشان می دهد که فرد دچار حمله قلبی نمی شود، در حالی که عدد ۱ نشان می دهد که فرد تحت تاثیر حمله قلبی قرار می گیرد.
بیایید ورودی و خروجی خود را از مجموعه داده فوق برای آموزش مدل خود تقسیم کنیم:
target_column = "output" numerical_column = df.columns.drop(target_column) output_rows = df[target_column] df.drop(target_column,axis=1,inplace=True)از آنجایی که هدف ما پیشبینی احتمال حمله قلبی (۰ یا ۱) است که با ستون هدف نشان داده میشود، آن را به یک مجموعه داده جداگانه تقسیم کردیم.
پیش پردازش داده ها
پیش پردازش داده ها یک مرحله مهم در خط لوله یادگیری ماشین است و طبقه بندی باینری نیز از این قاعده مستثنی نیست. این شامل تمیز کردن، تبدیل و سازماندهی داده های خام به قالبی است که برای آموزش مدل های یادگیری ماشین مناسب است.
یک مجموعه داده شامل چندین نوع داده مانند داده های عددی، داده های دسته بندی، داده های مهر زمانی و غیره خواهد بود.
اما بیشتر الگوریتم های یادگیری ماشین برای کار با داده های عددی طراحی شده اند. آنها نیاز دارند که داده های ورودی در قالب عددی برای عملیات ریاضی، بهینه سازی و آموزش مدل باشد.
در این مجموعه داده، تمام ستون ها حاوی داده های عددی هستند، پس ما نیازی به رمزگذاری داده ها نداریم. ما می توانیم با عادی سازی ساده ادامه دهیم.
به یاد داشته باشید که اگر ستون های غیر عددی در مجموعه داده خود دارید، ممکن است مجبور شوید آن را با انجام رمزگذاری یکباره یا استفاده از سایر الگوریتم های رمزگذاری به عدد تبدیل کنید.
استراتژی های عادی سازی زیادی وجود دارد. در اینجا من از Min-Max Normalization استفاده می کنم:
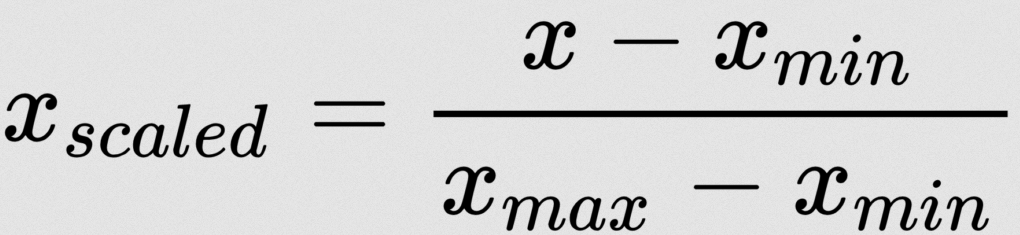
نگران نباشید - ما نیازی به اعمال این فرمول به صورت دستی نداریم. ما چند کتابخانه یادگیری ماشین برای انجام این کار داریم. در اینجا من از MinMaxScaler از sklearn استفاده می کنم:
scaler = MinMaxScaler() scaler.fit(df) t_df = scaler.transform(df) scaler.fit(df) میانگین و انحراف استاندارد (یا سایر پارامترهای مقیاس بندی) لازم برای انجام عملیات مقیاس بندی را محاسبه می کند. روش fit اساساً این پارامترها را از داده ها یاد می گیرد.
t_df = scaler.transform(df) : پس از برازش مقیاسکننده، باید مجموعه داده را تبدیل کنیم. تبدیل معمولاً ویژگی ها را با میانگین ۰ و انحراف استاندارد ۱ (استانداردسازی) مقیاس می کند یا آنها را به یک محدوده خاص (مثلا [۰، ۱] با مقیاس Min-Max) بسته به مقیاس کننده مورد استفاده مقیاس می کند.
ما پیش پردازش را کامل کرده ایم. گام مهم بعدی تقسیم مجموعه داده ها به مجموعه های آموزشی و آزمایشی است.
برای انجام این کار، من از تابع train_test_split از scikit-learn استفاده خواهم کرد.
X_train و X_test متغیرهایی هستند که متغیرهای مستقل را نگه می دارند.
y_train و y_test متغیرهایی هستند که متغیر وابسته را نگه می دارند که نشان دهنده خروجی ما برای پیش بینی است.
X_train, X_test, y_train, y_test = train_test_split(t_df, output_rows, test_size=0.25, random_state=0) print('X_train:',np.shape(X_train)) print('y_train:',np.shape(y_train)) print('X_test:',np.shape(X_test)) print('y_test:',np.shape(y_test))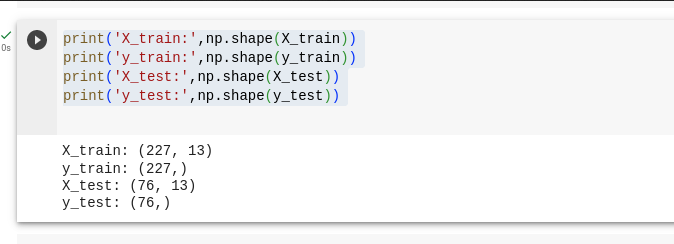
ما مجموعه داده را ۷۵% و ۲۵% تقسیم کردیم که ۷۵% برای آموزش مدل ما و ۲۵% برای آزمایش مدل ما اختصاص می یابد.
مدل ML ساختمان
مدل یادگیری ماشینی نمایش محاسباتی یک مشکل یا سیستمی است که برای یادگیری الگوها، روابط و تداعی ها از داده ها طراحی شده است. این به عنوان یک چارچوب ریاضی و الگوریتمی قادر به پیشبینی، طبقهبندی یا تصمیمگیری بر اساس دادههای ورودی است.
در اصل، یک مدل دانش استخراجشده از دادهها را محصور میکند و به آن اجازه تعمیم داده و پاسخهای آگاهانه به دادههای جدید و قبلاً دیده نشده را میدهد.
در اینجا، من در حال ساخت یک مدل متوالی ساده با یک لایه ورودی و یک لایه خروجی هستم. به عنوان یک مدل ساده، از هیچ لایه پنهانی استفاده نمی کنم زیرا ممکن است پیچیدگی مفهوم را افزایش دهد.
مدل متوالی را راه اندازی کنید
basic_model = Sequential() Sequential نوعی مدل در Keras است که به شما امکان می دهد شبکه های عصبی را لایه به لایه به صورت متوالی ایجاد کنید. هر لایه روی لایه قبلی اضافه می شود.
لایه ورودی
basic_model.add(Dense(units=16, activation='relu', input_shape=(13,))) Dense نوعی لایه در کراس است که نمایانگر یک لایه کاملاً متصل است. ۱۶ واحد دارد، یعنی ۱۶ نورون دارد.
activation='relu' تابع فعالسازی Rectified Linear Unit (ReLU) را مشخص میکند که معمولاً در لایههای ورودی یا پنهان شبکههای عصبی استفاده میشود.
input_shape=(13,) شکل داده های ورودی این لایه را نشان می دهد. در این مورد، ما از ۱۳ ویژگی ورودی (ستون) استفاده می کنیم.
لایه خروجی
basic_model.add(Dense(1, activation='sigmoid'))این خط لایه خروجی را به مدل اضافه می کند.
این یک نورون منفرد (۱ واحد) است زیرا به نظر می رسد این یک مشکل طبقه بندی باینری است، جایی که شما یکی از دو کلاس (۰ یا ۱) را پیش بینی می کنید.
تابع فعال سازی مورد استفاده در اینجا 'sigmoid' است که معمولاً برای کارهای طبقه بندی باینری استفاده می شود. خروجی را در محدوده ای بین ۰ و ۱ له می کند که نشان دهنده احتمال تعلق به یکی از کلاس ها است.
بهینه ساز
adam = keras.optimizers.Adam(learning_rate=0.001)این خط بهینه ساز Adam را با نرخ یادگیری ۰.۰۰۱ مقداردهی اولیه می کند. بهینه ساز وظیفه به روز رسانی وزنه های مدل را در طول تمرین به منظور به حداقل رساندن عملکرد تلفات تعریف شده بر عهده دارد.
کامپایل مدل
basic_model.compile(loss='binary_crossentropy', optimizer=adam, metrics=["accuracy"])در اینجا، مدل را کامپایل می کنیم.
loss='binary_crossentropy' تابع ضرر است که برای طبقهبندی باینری استفاده میشود. تفاوت بین مقادیر پیش بینی شده و واقعی را اندازه گیری می کند و در طول تمرین به حداقل می رسد.
metrics=["accuracy"] : در طول آموزش، ما قصد داریم متریک دقت را کنترل کنیم، که به شما می گوید مدل از نظر پیش بینی های صحیح چقدر خوب عمل می کند.
مدل قطار با مجموعه داده
هورا، ما مدل را ساختیم. اکنون زمان آموزش مدل با مجموعه داده های آموزشی است.
basic_model.fit(X_train, y_train, epochs=100) X_train داده های آموزشی را نشان می دهد که از متغیرهای مستقل (ویژگی ها) تشکیل شده است. مدل از این ویژگی ها برای پیش بینی یا طبقه بندی یاد می گیرد.
y_train برچسب های هدف یا متغیرهای وابسته مربوط به داده های آموزشی هستند. مدل از این اطلاعات برای یادگیری الگوها و روابط بین ویژگی ها و متغیر هدف استفاده می کند.
epochs=100 : پارامتر epochs تعداد دفعاتی را که مدل در کل مجموعه داده آموزشی تکرار می شود را مشخص می کند. به هر عبور در مجموعه داده، یک دوره می گویند. در این مورد، ما ۱۰۰ دوره داریم، به این معنی که مدل کل مجموعه داده آموزشی را ۱۰۰ بار در طول آموزش مشاهده خواهد کرد.
loss_and_metrics = basic_model.evaluate(X_test, y_test) print(loss_and_metrics) print('Loss = ',loss_and_metrics[0]) print('Accuracy = ',loss_and_metrics[1]) روش evaluate برای ارزیابی عملکرد مدل آموزشدیده در مجموعه دادههای آزمایشی استفاده میشود. این تلفات (اغلب همان تابع ضرری که در طول آموزش استفاده می شود) و هر معیار مشخص شده (مثلاً دقت) را برای پیش بینی های مدل در داده های آزمون محاسبه می کند.
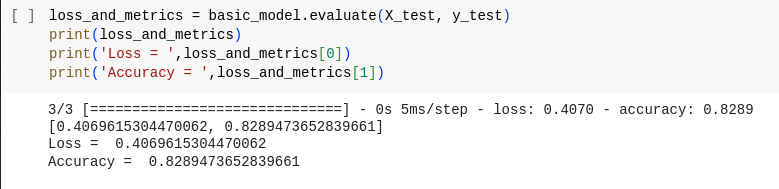
در اینجا ما حدود ۸۲ درصد دقت را به دست آوردیم.
پیش بینی و ارزیابی
predicted = basic_model.predict(X_test) روش predict برای تولید پیش بینی از مدل بر اساس داده های ورودی استفاده می شود ( X_test در این مورد). خروجی ( predicted ) شامل پیش بینی های مدل برای هر نقطه داده در مجموعه داده آموزشی خواهد بود.
از آنجایی که من فقط حداقل مجموعه داده دارم، از مجموعه داده آزمایشی برای پیش بینی استفاده می کنم. با این حال، تقسیم بخشی از مجموعه داده (مثلاً ۱۰٪) برای استفاده به عنوان یک مجموعه داده اعتبار سنجی توصیه می شود.
ارزیابی
ارزیابی پیشبینیها در یادگیری ماشین گامی مهم برای ارزیابی عملکرد یک مدل است.
یکی از ابزارهای رایج برای ارزیابی مدل های طبقه بندی، ماتریس سردرگمی است. بیایید تحلیل کنیم که ماتریس سردرگمی چیست و چگونه برای ارزیابی مدل استفاده می شود:
در یک مسئله طبقه بندی باینری (دو کلاس، به عنوان مثال، "مثبت" و "منفی")، یک ماتریس سردرگمی معمولاً به این صورت است:
| منفی پیش بینی شده (۰) | مثبت پیش بینی شده (۱) | |
| منفی واقعی (۰) | منفی واقعی | مثبت کاذب |
| مثبت واقعی (۱) | منفی اشتباه | مثبت واقعی |
در اینجا کد رسم ماتریس سردرگمی از داده های پیش بینی شده مدل ما آمده است:
predicted = tf.squeeze(predicted) predicted = np.array([1 if x >= 0.5 else 0 for x in predicted]) actual = np.array(y_test) conf_mat = confusion_matrix(actual, predicted) displ = ConfusionMatrixDisplay(confusion_matrix=conf_mat) displ.plot()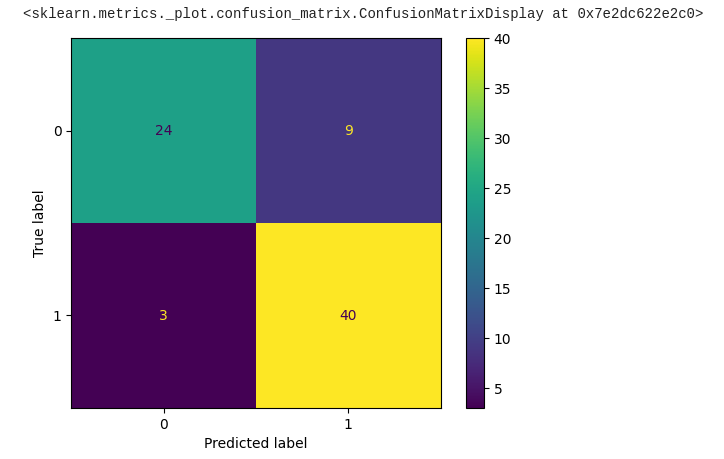
براوو! ما پیشرفت قابل توجهی در جهت به دست آوردن خروجی مورد نیاز داشته ایم و تقریباً ۸۴ درصد از داده ها صحیح به نظر می رسند.
شایان ذکر است که میتوانیم این مدل را با استفاده از مجموعه دادههای بزرگتر و تنظیم دقیق پارامترهای فوق، بیشتر بهینه کنیم. با این حال، برای درک اساسی، آنچه ما تا کنون انجام داده ایم بسیار چشمگیر است.
از آنجایی که این مجموعه داده و مدلهای یادگیری ماشین مربوطه در سطح بسیار ابتدایی هستند، مهم است که اذعان کنیم که سناریوهای دنیای واقعی اغلب شامل مجموعه دادههای بسیار پیچیدهتر و وظایف یادگیری ماشین هستند.
در حالی که این مدل ممکن است برای مشکلات ساده به اندازه کافی عمل کند، ممکن است برای مقابله با چالش های پیچیده تر مناسب نباشد.
در برنامههای کاربردی دنیای واقعی، مجموعه دادهها میتوانند گسترده و متنوع باشند، که شامل بسیاری از ویژگیها، روابط پیچیده و الگوهای پنهان هستند. در نتیجه، پرداختن به چنین پیچیدگیهایی اغلب نیازمند رویکرد پیچیدهتری است.
در اینجا چند فاکتور کلیدی وجود دارد که باید هنگام کار با مجموعه داده های پیچیده در نظر بگیرید.
پیش پردازش داده های پیچیده
رمزگذاری داده های پیشرفته
درک همبستگی داده ها
چندین لایه شبکه عصبی
مهندسی ویژگی
منظم سازی
اگر از قبل با ساخت یک شبکه عصبی اولیه آشنا هستید، من به شدت توصیه میکنم که در این مفاهیم برای برتری در دنیای یادگیری ماشینی بگردید.
نتیجه
در این مقاله، سفری را به دنیای جذاب یادگیری ماشین آغاز کردیم و با اصول اولیه شروع کردیم.
ما اصول طبقه بندی باینری را تحلیل کردیم - یک کار اساسی یادگیری ماشین. از درک مسئله تا ساخت یک مدل ساده، ما بینش هایی را در مورد مفاهیم اساسی که زیربنای این زمینه قدرتمند است به دست آورده ایم.
پس ، چه تازه شروع کردهاید و چه در حال پیشرفت در مسیر هستید، به کاوش، آزمایش، و فشار دادن مرزهای امکانپذیر با یادگیری ماشین ادامه دهید. من شما را در یک مقاله هیجان انگیز دیگر می بینم!
اگر می خواهید در مورد هوش مصنوعی / یادگیری ماشین / یادگیری عمیق اطلاعات بیشتری کسب کنید، با بازدید از سایت من در مقاله من مشترک شوید، که فهرست تلفیقی از همه مقالات من را دارد.
برچسبها
|
|



ارسال نظر