چگونه یک مدل هوش مصنوعی کوانتومی برای پیش بینی داده های گل زنبق با پایتون بسازیم

یادگیری ماشینی حوزه ای از هوش مصنوعی است که در آن امثال ChatGPT و سایر مدل های معروف ایجاد شده است. این سیستم ها همگی با شبکه های عصبی ایجاد شده اند.
حوزه یادگیری ماشینی که با ایجاد این شبکه های عصبی سروکار دارد، یادگیری عمیق نامیده می شود.
در این پست وبلاگ، یک شبکه عصبی با تعدادی نورون که روی یک کامپیوتر کلاسیک اجرا می شوند و بقیه در کامپیوترهای کوانتومی ایجاد می کنیم.
به این ترتیب، ایجاد و آموزش یک شبکه عصبی با هر دو نوع نورون، یک مدل هوش مصنوعی مبتنی بر محاسبات کوانتومی ایجاد میکند، زیرا بیشتر پردازش در نورونهای کوانتومی انجام میشود.
در مورد این موارد صحبت خواهیم کرد:
مقدمه ای بر هوش مصنوعی، شبکه های عصبی ترکیبی و مزایای آن
هوش مصنوعی کوانتومی در عمل: پیشبینی دادههای گل زنبق با پایتون
نتیجه گیری: آینده مدل های هوش مصنوعی کارآمد
توجه: ما یک شبکه عصبی ساده ایجاد خواهیم کرد و از معماری های پیچیده مانند ترانسفورماتورها، غواصی عمیق در فیزیک کوانتومی یا تکنیک های بهینه سازی مدل هوش مصنوعی پیشرفته اجتناب می کنیم.
مقدمه ای بر هوش مصنوعی، شبکه های عصبی ترکیبی و مزایای آن

یادگیری عمیق در هوش مصنوعی چیست؟
یادگیری عمیق زیر شاخه ای از هوش مصنوعی است که از شبکه های عصبی برای پیش بینی الگوهای پیچیده مانند آب و هوا، طبقه بندی تصاویر، پاسخ به متن و غیره استفاده می کند.
هر چه شبکه عصبی بزرگتر باشد، کارهای پیچیده تری می تواند انجام دهد. مانند ChatGPT که می تواند زبان طبیعی را برای تعامل با کاربران پردازش کند.
شبکه های عصبی

یادگیری عمیق آموزش شبکه های عصبی برای پیش بینی داده های آینده است. آموزش یک شبکه عصبی شامل تغذیه داده ها، اجازه یادگیری و سپس انجام پیش بینی است.
شبکه های عصبی از نورون های بسیاری تشکیل شده اند که در لایه ها سازماندهی شده اند. همه لایه ها الگوهای متفاوتی از داده ها را دریافت می کنند.
این ساختار نوع لایه به مدل های هوش مصنوعی اجازه می دهد تا داده ها و الگوهای پیچیده را تفسیر کنند. به عنوان مثال، شبکه عصبی در تصویر بالا، به عنوان مثال، با 8 ویژگی از داده های آب و هوا، می تواند آموزش داده شود که آیا باران خواهد بارید یا خیر.
لایه ای که داده می گیرد لایه ورودی و لایه نهایی لایه خروجی نامیده می شود. بین اینها لایههای پنهانی هستند که الگوهای پیچیده را به تصویر میکشند.
البته این یک شبکه عصبی بسیار ساده است، اما ایده آموزش شبکه عصبی برای هر معماری پیچیده یکسان است.
شبکه های عصبی ترکیبی - ترکیب محاسبات کوانتومی و کلاسیک
اکنون یک شبکه عصبی ترکیبی ایجاد می کنیم. اساساً، لایههای ورودی و خروجی روی رایانههای کلاسیک کار میکنند در حالی که لایه پنهان دادهها را روی رایانههای کوانتومی پردازش میکند.
این رویکرد از بهترین محاسبات کلاسیک و کوانتومی برای آموزش شبکه عصبی استفاده می کند.
چرا شبکه های عصبی ترکیبی را نسبت به شبکه های عصبی سنتی انتخاب کنیم؟

ایده اصلی استفاده از یک شبکه عصبی ترکیبی این است که پردازش داده ها در یک کامپیوتر کوانتومی انجام شود که بسیار سریعتر از یک کامپیوتر کلاسیک است.
علاوه بر این، کامپیوترهای کوانتومی وظایف خاصی را با مصرف انرژی بسیار کمتر انجام می دهند. این کارایی در پردازش و استفاده از انرژی باعث ایجاد مدلهای هوش مصنوعی کوچکتر و قابل اعتمادتر میشود.
این ایده اصلی یک شبکه عصبی ترکیبی است: ایجاد مدلهای هوش مصنوعی کوچکتر و کارآمدتر.
هوش مصنوعی کوانتومی در عمل: پیشبینی دادههای گل زنبق با پایتون

در این کد، یک مدل هوش مصنوعی مبتنی بر کوانتومی برای پیشبینی گونههای گل زنبق از مجموعه داده معروف زنبق ایجاد میکنیم.
این کد از یک شبیه ساز کوانتومی به نام default.qubit استفاده می کند که رفتار کامپیوتر کوانتومی را در یک کامپیوتر کلاسیک تقلید می کند.
این به دلیل استفاده از مدل های ریاضی برای شبیه سازی عملیات کوانتومی امکان پذیر است.
با این حال، با برخی تغییرات کد، میتوانید این کد را بر روی پلتفرمهای IBM، Amazon یا Microsoft اجرا کنید تا عملاً روی یک رایانه کوانتومی اجرا شود.
import pennylane as qml import numpy as np from sklearn.datasets import load_iris from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # Load and preprocess the Iris dataset data = load_iris() X = data.data y = data.target # Standardize the features scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # One-hot encode the labels encoder = OneHotEncoder(sparse=False) y_onehot = encoder.fit_transform(y.reshape(-1, 1)) # Split the dataset X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_onehot, test_size=0.2, random_state=42) # Define a quantum device n_qubits = 4 dev = qml.device('default.qubit', wires=n_qubits) # Define a quantum node @qml.qnode(dev) def quantum_circuit(inputs, weights): for i in range(len(inputs)): qml.RY(inputs[i], wires=i) for i in range(n_qubits): qml.RX(weights[i], wires=i) qml.RY(weights[n_qubits + i], wires=i) return [qml.expval(qml.PauliZ(i)) for i in range(n_qubits)] # Define a hybrid quantum-classical model def hybrid_model(inputs, weights): return quantum_circuit(inputs, weights) # Initialize weights np.random.seed(0) weights = np.random.normal(0, np.pi, (2 * n_qubits,)) # Define a cost function def cost(weights): predictions = np.array([hybrid_model(x, weights) for x in X_train]) loss = np.mean((predictions - y_train) ** 2) return loss # Optimize the weights using gradient descent opt = qml.GradientDescentOptimizer(stepsize=0.1) steps = 100 for i in range(steps): weights = opt.step(cost, weights) if i % 10 == 0: print(f"Step {i}, Cost: {cost(weights)}") # Test the model predictions = np.array([hybrid_model(x, weights) for x in X_test]) predicted_labels = np.argmax(predictions, axis=1) true_labels = np.argmax(y_test, axis=1) # Calculate the accuracy accuracy = accuracy_score(true_labels, predicted_labels) print(f"Test Accuracy: {accuracy * 100:.2f}%") 
بیایید بلوک به بلوک کد را ببینیم!
واردات کتابخانه ها
import pennylane as qml import numpy as np from sklearn.datasets import load_iris from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score 
در این قسمت از کد، کتابخانه های لازم را وارد کردیم:
pennylane و pennylane.numpy : برای ایجاد و دستکاری مدارهای کوانتومی.
sklearn.datasets : برای بارگذاری مجموعه داده Iris.
sklearn.preprocessing : برای پیش پردازش داده ها مانند مقیاس بندی و رمزگذاری.
sklearn.model_selection : برای تقسیم داده ها به مجموعه های آموزشی و آزمایشی.
sklearn.metrics : برای ارزیابی دقت مدل.
مجموعه داده Iris را بارگیری و از قبل پردازش کنید
# Load and preprocess the Iris dataset data = load_iris() X = data.data y = data.target # Standardize the features scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # One-hot encode the labels encoder = OneHotEncoder(sparse=False) y_onehot = encoder.fit_transform(y.reshape(-1, 1)) # Split the dataset X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_onehot, test_size=0.2, random_state=42) 
در اینجا داده ها را برای آموزش شبکه عصبی آماده کردیم:
مجموعه داده Iris را بارگیری می کند و ویژگی های ( X ) و برچسب ها ( y ) را استخراج می کند.
با استفاده از StandardScaler ویژگی ها را به گونه ای استاندارد می کند که میانگین و واریانس واحد صفر داشته باشند.
One-hot برچسب ها را برای طبقه بندی چند کلاسه با استفاده از OneHotEncoder رمزگذاری می کند.
مجموعه داده را به مجموعه های آموزشی و آزمایشی با نسبت 80/20 تقسیم می کند.
دستگاه و مدار کوانتومی را تعریف کنید
# Define a quantum device n_qubits = 4 dev = qml.device('default.qubit', wires=n_qubits) # Define a quantum node @qml.qnode(dev) def quantum_circuit(inputs, weights): for i in range(len(inputs)): qml.RY(inputs[i], wires=i) for i in range(n_qubits): qml.RX(weights[i], wires=i) qml.RY(weights[n_qubits + i], wires=i) return [qml.expval(qml.PauliZ(i)) for i in range(n_qubits)] 
این بخش دستگاه و مدار کوانتومی را تعریف می کند:
با استفاده از شبیه ساز پیش فرض PennyLane یک دستگاه کوانتومی با 4 کیوبیت راه اندازی می کند.
مدار کوانتومی ( quantum_circuit ) را تعریف می کند که ورودی ها و وزن ها را می گیرد. مدار از گیت های چرخشی ( RY ، RX ) برای رمزگذاری ورودی ها و پارامترها استفاده می کند و مقادیر مورد انتظار عملگرهای PauliZ را در هر کیوبیت اندازه گیری می کند.
مدل ترکیبی را تعریف کنید و وزن ها را اولیه کنید
# Define a hybrid quantum-classical model def hybrid_model(inputs, weights): return quantum_circuit(inputs, weights) # Initialize weights np.random.seed(0) weights = np.random.normal(0, np.pi, (2 * n_qubits,)) 
در اینجا، ما در واقع مدل را ایجاد کردیم و وزن آن را شروع کردیم.
یک تابع مدل ترکیبی را تعریف می کند که از مدار کوانتومی استفاده می کند.
وزنها را برای مدل با استفاده از توزیع نرمال با دانه مشخص برای تکرارپذیری اولیه میکند.
تابع هزینه را تعریف کنید و وزن ها را بهینه کنید
# Define a cost function def cost(weights): predictions = np.array([hybrid_model(x, weights) for x in X_train]) loss = np.mean((predictions - y_train) ** 2) return loss # Optimize the weights using gradient descent opt = qml.GradientDescentOptimizer(stepsize=0.1) steps = 100 for i in range(steps): weights = opt.step(cost, weights) if i % 10 == 0: print(f"Step {i}, Cost: {cost(weights)}") 
در نهایت آموزش شبکه عصبی مبتنی بر کوانتومی را آغاز کردیم.
یک تابع هزینه را تعریف می کند که میانگین مربعات خطا بین پیش بینی ها و برچسب های واقعی را محاسبه می کند.
از GradientDescentOptimizer PennyLane برای به حداقل رساندن تابع هزینه با بهروزرسانی وزنها به طور مکرر استفاده میکند. این هزینه را هر 10 مرحله برای پیگیری پیشرفت چاپ می کند.
چاپ می کند:
Step 0, Cost: 0.35359229278282217 Step 10, Cost: 0.3145818194833503 Step 20, Cost: 0.28937668289628116 Step 30, Cost: 0.2733108557682183 Step 40, Cost: 0.26273285477208475 Step 50, Cost: 0.25532913470009133 Step 60, Cost: 0.24973939376050813 Step 70, Cost: 0.24517135825709957 Step 80, Cost: 0.2411459409849017 Step 90, Cost: 0.23735091263019087مدل را تست کنید و دقت را ارزیابی کنید
# Test the model predictions = np.array([hybrid_model(x, weights) for x in X_test]) predicted_labels = np.argmax(predictions, axis=1) true_labels = np.argmax(y_test, axis=1) # Calculate the accuracy accuracy = accuracy_score(true_labels, predicted_labels) print(f"Test Accuracy: {accuracy * 100:.2f}%") 
در مرحله بعد، مدل آموزش دیده را ارزیابی می کنیم:
با استفاده از وزنهای بهینهشده، روی مجموعه آزمایشی پیشبینی میکند.
پیشبینیهای کدگذاریشده و برچسبهای واقعی را به برچسبهای کلاس تبدیل میکند.
با استفاده از accuracy_score دقت مدل را محاسبه و چاپ می کند.
و نتایج نهایی نشان داد:
Test Accuracy: 66.67%دقت 67 درصد نتیجه مدل هوش مصنوعی خوبی نیست. این به این دلیل است که ما این شبکه عصبی را برای این داده ها بهینه نکرده ایم.
برای به دست آوردن نتایج بهتر باید ساختار شبکه عصبی را تغییر دهیم.
با این حال، برای این مجموعه داده، فقط با شبکههای عصبی معمولی و کتابخانهای مانند optuna برای بهینهسازی هایپرپارامتر، دقت بسیار بالاتری بیش از ۹۸ درصد امکانپذیر است و میتوان به راحتی به آن دست یافت.
با این وجود، ما یک مدل هوش مصنوعی کوانتومی ساده ایجاد کردیم.
نتیجه گیری: آینده مدل های هوش مصنوعی کارآمد

ادغام محاسبات کوانتومی در هوش مصنوعی امکان ایجاد مدل های هوش مصنوعی کوچکتر و کارآمدتر را فراهم می کند. با پیشرفتهای بیشتر در فناوری کوانتومی، این فناوری بیشتر و بیشتر در هوش مصنوعی اعمال خواهد شد.
به نظر من، آینده هوش مصنوعی در نهایت با کامپیوترهای کوانتومی ادغام خواهد شد.
این هم کد کامل:
 GitHub
GitHubبرچسبها
|
|

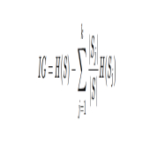


ارسال نظر