چگونه یک خط لوله RAG با LlamaIndex بسازیم
مدلهای زبان بزرگ این روزها همه جا هستند - فکر کنید ChatGPT - اما آنها سهم خود را از چالشها دارند.
یکی از بزرگترین چالش هایی که LLM ها با آن مواجه هستند، توهم هستند. این زمانی اتفاق میافتد که مدل متنی را تولید میکند که واقعاً نادرست یا گمراهکننده است، اغلب بر اساس الگوهایی که از دادههای آموزشی خود آموخته است. پس چگونه Retrieval-Augmented Generation یا RAG می تواند به کاهش این مشکل کمک کند؟
RAG با بازیابی اطلاعات مرتبط از یک پایگاه دانش گسترده تر و گسترده تر، اطمینان می دهد که پاسخ های LLM بر اساس حقایق دنیای واقعی است. این به طور قابل توجهی احتمال توهم را کاهش می دهد و دقت و قابلیت اطمینان کلی محتوای تولید شده را بهبود می بخشد.
فهرست مطالب:
Retrieval Augmented Generation (RAG) چیست؟
RAG تکنیکی است که بازیابی اطلاعات را با تولید زبان ترکیب می کند. به آن به عنوان یک فرآیند دو مرحله ای فکر کنید:
بازیابی: مدل ابتدا اطلاعات مربوطه را از مجموعه بزرگی از اسناد بر اساس درخواست کاربر بازیابی می کند.
نسل: با استفاده از این اطلاعات بازیابی شده، مدل پاسخ جامع و آموزنده ای ایجاد می کند.
چرا از LlamaIndex برای RAG استفاده کنیم؟
LlamaIndex یک چارچوب قدرتمند است که فرآیند ساخت خطوط لوله RAG را ساده می کند. این یک روش انعطافپذیر و کارآمد برای اتصال اجزای بازیابی (مانند پایگاههای داده برداری و مدلهای جاسازی) با اجزای تولید (مانند LLM) ارائه میکند.
برخی از مزایای کلیدی استفاده از Llama-Index عبارتند از:
ماژولار بودن: به شما اجازه می دهد تا به راحتی اجزای مختلف را سفارشی کنید و آزمایش کنید.
مقیاس پذیری: می تواند مجموعه داده های بزرگ و پرس و جوهای پیچیده را مدیریت کند.
سهولت استفاده: یک API سطح بالا ارائه می کند که بسیاری از پیچیدگی های اساسی را از بین می برد.
آنچه در اینجا خواهید آموخت:
در این مقاله، اجزای یک خط لوله RAG را عمیقتر خواهیم کرد و چگونگی استفاده از LlamaIndex را برای ساخت این سیستمها تحلیل خواهیم کرد.
ما موضوعاتی مانند پایگاه های داده برداری، مدل های تعبیه شده، مدل های زبان و نقش LlamaIndex در اتصال این مؤلفه ها را پوشش خواهیم داد.
آشنایی با اجزای یک خط لوله RAG
در اینجا نموداری وجود دارد که به شما کمک می کند تا با اصول معماری RAG آشنا شوید:
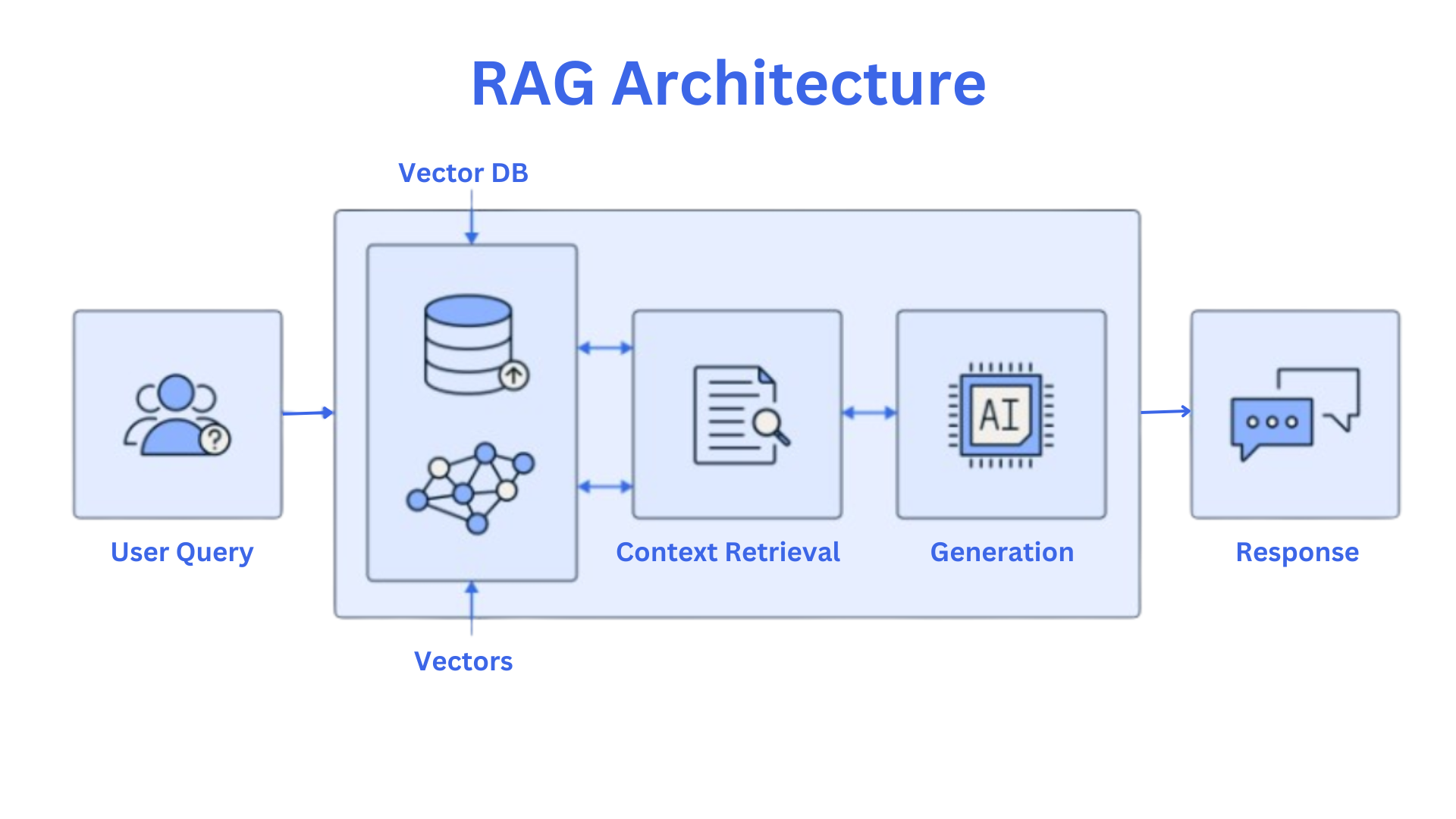 که جریان از پرس و جو کاربر تا پاسخ را نشان می دهد" class="image--center mx-auto" width="1920" height="1080" loading="lazy">
که جریان از پرس و جو کاربر تا پاسخ را نشان می دهد" class="image--center mx-auto" width="1920" height="1080" loading="lazy">
این نمودار از این مقاله الهام گرفته شده است. بیایید قطعات کلیدی را مرور کنیم.
اجزای RAG
جزء بازیابی:
پایگاه های داده برداری: این پایگاه های داده برای ذخیره و جستجوی بردارهای با ابعاد بالا بهینه شده اند. آنها برای یافتن کارآمد اطلاعات مرتبط از مجموعه وسیعی از اسناد بسیار مهم هستند.
مدلهای جاسازی: این مدلها متن را به نمایش عددی یا جاسازی تبدیل میکنند. این تعبیهها معنای معنایی متن را میگیرند و امکان مقایسه و بازیابی کارآمد در پایگاههای داده برداری را فراهم میکنند.
بردار یک جسم ریاضی است که کمیتی را با قدر (اندازه) و جهت نشان می دهد. در زمینه RAG، embedding ها بردارهایی با ابعاد بالا هستند که معنای معنایی متن را به تصویر می کشند. هر بعد از بردار جنبه متفاوتی از معنای متن را نشان می دهد و امکان مقایسه و بازیابی کارآمد را فراهم می کند.
مولفه نسل:
مدلهای زبان: این مدلها بر روی حجم عظیمی از دادههای متنی آموزش داده میشوند و به آنها امکان میدهد متنی با کیفیت انسانی تولید کنند. آنها قادر به درک و پاسخگویی به اطالعات به شیوه ای منسجم و آموزنده هستند.
جریان RAG
ارسال درخواست: کاربر یک پرس و جو یا سوال ارسال می کند.
ایجاد جاسازی: پرس و جو با استفاده از همان مدل جاسازی مورد استفاده برای پیکره به یک جاسازی تبدیل می شود.
بازیابی: جاسازی در پایگاه داده برداری برای یافتن مرتبط ترین اسناد جستجو می شود.
زمینه سازی: اسناد بازیابی شده با پرس و جو اصلی ترکیب می شوند تا یک زمینه را تشکیل دهند.
نسل: مدل زبان پاسخی را بر اساس زمینه ارائه شده ایجاد می کند.
LamaIndex
LlamaIndex نقش مهمی در اتصال اجزای بازیابی و تولید ایفا می کند. به عنوان شاخصی عمل می کند که پرس و جوها را به اسناد مربوطه نگاشت می کند. LlamaIndex با مدیریت کارآمد ایندکس تضمین می کند که فرآیند بازیابی سریع و دقیق است.
پیش نیازها
ما در این مقاله از Python و IBM watsonx از طریق LlamaIndex استفاده خواهیم کرد. قبل از شروع باید موارد زیر را در سیستم خود داشته باشید:
پایتون 3.9+
کنجکاوی برای یادگیری
بیایید شروع کنیم!
در این مقاله، ما از LlamaIndex برای ساخت یک خط لوله RAG ساده استفاده خواهیم کرد.
بیایید با استفاده از دستور زیر در ترمینال خود یک محیط مجازی برای پایتون ایجاد کنیم: python -m venv venv . این یک محیط مجازی (venv) برای پروژه شما ایجاد می کند. اگر کاربر ویندوز هستید، میتوانید آن را با استفاده از .\venv\Scripts\activate و کاربران مک میتوانند آن را با source venv/bin/activate فعال کنند.
حالا بیایید بسته ها را نصب کنیم:
pip install wikipedia llama-index-llms-ibm llama-index-embeddings-huggingfaceپس از نصب این بسته ها، به کلید API watsonx.ai نیز نیاز خواهید داشت. این به نوبه خود به شما کمک می کند تا از LLM ها از طریق LlamaIndex استفاده کنید.
برای آشنایی با نحوه دریافت کلیدهای API watsonx.ai، اینجا را کلیک کنید. برای اینکه بتوانید روی جنبه "Generation" RAG کار کنید، به شناسه پروژه و کلید API نیاز دارید. داشتن آنها به شما کمک می کند تا تماس های LLM را از طریق watsonx.ai برقرار کنید.
import wikipedia # Search for a specific page page = wikipedia.page( "Artificial Intelligence" ) # Access the content print(page.content)حالا بیایید محتوای صفحه را در یک سند متنی ذخیره کنیم. ما این کار را انجام می دهیم تا بعداً بتوانیم به آن دسترسی پیدا کنیم. با استفاده از کد زیر می توانید این کار را انجام دهید:
import os # Create the 'Document' directory if it doesn't exist if not os.path.exists( 'Document' ): os.mkdir( 'Document' ) # Open the file 'AI.txt' in write mode with UTF-8 encoding with open( 'Document/AI.txt' , 'w' , encoding= 'utf-8' ) as f: # Write the content of the 'page' object to the file f.write(page.content)اکنون ما از watsonx.ai از طریق LlamaIndex استفاده خواهیم کرد. این به ما کمک می کند تا پاسخ هایی را بر اساس درخواست کاربر ایجاد کنیم.
توجه: مطمئن شوید که پارامترهای WATSONX_APIKEY و project_id را با مقادیر خود در کد زیر جایگزین کنید:
import os from llama_index.llms.ibm import WatsonxLLM from llama_index.core import SimpleDirectoryReader, Document # Define a function to generate responses using the WatsonxLLM instance def generate_response ( prompt ): """ Generates a response to the given prompt using the WatsonxLLM instance. Args: prompt (str): The prompt to provide to the large language model. Returns: str: The generated response from the WatsonxLLM. """ response = watsonx_llm.complete(prompt) return response # Set the WATSONX_APIKEY environment variable (replace with your actual key) os.environ[ "WATSONX_APIKEY" ] = 'YOUR_WATSONX_APIKEY' # Replace with your API key # Define model parameters (adjust as needed) temperature = 0 max_new_tokens = 1500 additional_params = { "decoding_method" : "sample" , "min_new_tokens" : 1 , "top_k" : 50 , "top_p" : 1 , } # Create a WatsonxLLM instance with the specified model, URL, project ID, and parameters watsonx_llm = WatsonxLLM( model_id= "meta-llama/llama-3-1-70b-instruct" , url= "https://us-south.ml.cloud.ibm.com" , project_id= "YOUR_PROJECT_ID" , temperature=temperature, max_new_tokens=max_new_tokens, additional_params=additional_params, ) # Load documents from the specified directory documents = SimpleDirectoryReader( input_files=[ "Document/AI.txt" ] ).load_data() # Combine the text content of all documents into a single Document object combined_documents = Document(text= "\n\n" .join([doc.text for doc in documents])) # Print the combined document print(combined_documents)در اینجا به تفکیک پارامترها آمده است:
دما = 0: این تنظیم باعث میشود که مدل محتملترین دنباله متن را تولید کند که منجر به خروجی قطعیتر و قابل پیشبینیتر میشود. مثل این است که به مدل بگویید به رایج ترین کلمات و عبارات پایبند باشد.
max_new_tokens = 1500: این متن تولید شده را به حداکثر 1500 نشانه جدید (کلمات یا قسمت هایی از کلمات) محدود می کند.
extra_params:
decoding_method = "sample": این بدان معناست که مدل به صورت تصادفی متنی را بر اساس توزیع احتمال هر توکن تولید می کند.
min_new_tokens = 1: تضمین می کند که حداقل یک توکن جدید تولید شده است و از تکرار مدل جلوگیری می کند.
top_k = 50: این انتخاب مدل را به 50 توکن محتمل در هر مرحله محدود میکند و خروجی را متمرکزتر و تصادفیتر میکند.
top_p = 1: احتمال نمونه برداری هسته را روی 1 تنظیم می کند، به این معنی که همه نشانه هایی با احتمال بیشتر یا مساوی با مقدار top_p در نظر گرفته می شوند.
میتوانید این پارامترها را برای آزمایش تغییر دهید و ببینید که چگونه بر پاسخ شما تأثیر میگذارند. اکنون یک نمایه ذخیره برداری برداری از سند داده شده ایجاد و بارگذاری می کنیم. اما ابتدا بیایید بفهمیم که چیست.
درک نمایه های فروشگاه برداری
شاخص ذخیره برداری یک ساختار داده تخصصی است که برای ذخیره و بازیابی موثر بردارهای با ابعاد بالا طراحی شده است. در زمینه شاخص لاما، این بردارها تعبیههای معنایی اسناد را نشان میدهند.
ویژگی های کلیدی شاخص های فروشگاه برداری:
بردارهای با ابعاد بالا: هر سند به عنوان یک بردار با ابعاد بالا نشان داده می شود و معنای معنایی آن را در بر می گیرد.
بازیابی کارآمد: نمایه های فروشگاه برداری برای جستجوی سریع تشابه بهینه شده اند و به شما امکان می دهند اسنادی را که از نظر معنایی شبیه به یک جستار داده شده هستند به سرعت بیابید.
مقیاس پذیری: آنها می توانند مجموعه داده های بزرگ را مدیریت کنند و با افزایش تعداد اسناد، به طور موثر مقیاس شوند.
نحوه استفاده لاما ایندکس از نمایه های ذخیره برداری:
جاسازی سند: اسناد ابتدا با استفاده از مدل زبانی مانند Llama به بردارهایی با ابعاد بالا تبدیل می شوند.
ایجاد ایندکس: جاسازیها در فهرست ذخیرهسازی برداری ذخیره میشوند.
پردازش پرس و جو: هنگامی که یک کاربر درخواستی را ارسال می کند، آن را نیز به یک بردار تبدیل می کند. سپس از نمایه ذخیره برداری برای یافتن مشابه ترین اسناد بر اساس جاسازی آنها استفاده می شود.
تولید پاسخ: اسناد بازیابی شده برای ایجاد پاسخ مربوطه استفاده می شود.
در کد زیر با کلمه chunk مواجه خواهید شد. قطعه یک واحد کوچکتر و قابل مدیریت از متن است که از یک سند بزرگتر استخراج می شود. معمولاً یک پاراگراف یا چند جمله است. آنها برای کارآمدتر کردن بازیابی و پردازش اطلاعات، به ویژه در هنگام برخورد با اسناد بزرگ استفاده می شوند.
با تقسیم اسناد به قطعات، سیستمهای RAG میتوانند بر مرتبطترین بخشها تمرکز کنند و پاسخهای دقیقتر و مختصرتری تولید کنند.
from llama_index.core.node_parser import SentenceSplitter from llama_index.core import VectorStoreIndex, load_index_from_storage from llama_index.core import Settings from llama_index.core import StorageContext def get_build_index ( documents, embed_model= "local:BAAI/bge-small-en-v1.5" , save_dir= "./vector_store/index" ): """ Builds or loads a vector store index from the given documents. Args: documents (list[Document]): A list of Document objects. embed_model (str, optional): The embedding model to use. Defaults to "local:BAAI/bge-small-en-v1.5". save_dir (str, optional): The directory to save or load the index from. Defaults to "./vector_store/index". Returns: VectorStoreIndex: The built or loaded index. """ # Set index settings Settings.llm = watsonx_llm Settings.embed_model = embed_model Settings.node_parser = SentenceSplitter(chunk_size= 1000 , chunk_overlap= 200 ) Settings.num_output = 512 Settings.context_window = 3900 # Check if the save directory exists if not os.path.exists(save_dir): # Create and load the index index = VectorStoreIndex.from_documents( [documents], service_context=Settings ) index.storage_context.persist(persist_dir=save_dir) else : # Load the existing index index = load_index_from_storage( StorageContext.from_defaults(persist_dir=save_dir), service_context=Settings, ) return index # Get the Vector Index vector_index = get_build_index(documents=documents, embed_model= "local:BAAI/bge-small-en-v1.5" , save_dir= "./vector_store/index" )این آخرین بخش RAG است: ما یک موتور جستجو با جایگزینی ابرداده و رتبه بندی مجدد ترانسفورماتور جمله ایجاد می کنیم. رفیق پسر! حالا رتبه بندی مجدد چیست؟
رتبهبندی مجدد مؤلفهای است که اسناد بازیابی شده را بر اساس ارتباط آنها با پرس و جو مرتب میکند. از اطلاعات اضافی مانند شباهت معنایی یا عوامل زمینه خاص برای اصلاح رتبه بندی اولیه ارائه شده توسط سیستم بازیابی استفاده می کند. این کمک می کند تا اطمینان حاصل شود که مرتبط ترین اسناد به کاربر ارائه می شود و منجر به پاسخ های دقیق تر و آموزنده تر می شود.
from llama_index.core.postprocessor import MetadataReplacementPostProcessor, SentenceTransformerRerank def get_query_engine ( sentence_index, similarity_top_k= 6 , rerank_top_n= 2 ): """ Creates a query engine with metadata replacement and sentence transformer reranking. Args: sentence_index (VectorStoreIndex): The sentence index to use. similarity_top_k (int, optional): The number of similar nodes to consider. Defaults to 6. rerank_top_n (int, optional): The number of nodes to rerank. Defaults to 2. Returns: QueryEngine: The query engine. """ postproc = MetadataReplacementPostProcessor(target_metadata_key= "window" ) rerank = SentenceTransformerRerank( top_n=rerank_top_n, model= "BAAI/bge-reranker-base" ) engine = sentence_index.as_query_engine( similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank] ) return engine # Create a query engine with the specified parameters query_engine = get_query_engine(sentence_index=vector_index, similarity_top_k= 8 , rerank_top_n= 5 ) # Query the engine with a question query = 'What is Deep learning?' response = query_engine.query(query) prompt = f'''Generate a detailed response for the query asked based only on the context fetched: Query: {query} Context: {response} Instructions: 1. Show query and your generated response based on context. 2. Your response should be detailed and should cover every aspect of the context. 3. Be crisp and concise. 4. Don't include anything else in your response - no header/footer/code etc ''' response = generate_response(prompt) print(response.text) ''' OUTPUT - Query: What is Deep learning? Deep learning is a subset of artificial intelligence that utilizes multiple layers of neurons between the network's inputs and outputs to progressively extract higher-level features from raw input data. This technique allows for improved performance in various subfields of AI, such as computer vision, speech recognition, natural language processing, and image classification. The multiple layers in deep learning networks are able to identify complex concepts and patterns, including edges, faces, digits, and letters. The reason behind deep learning's success is not attributed to a recent theoretical breakthrough, but rather the significant increase in computer power, particularly the shift to using graphics processing units (GPUs), which provided a hundred-fold increase in speed. Additionally, the availability of vast amounts of training data, including large curated datasets, has also contributed to the success of deep learning. Overall, deep learning's ability to analyze and extract insights from raw data has led to its widespread application in various fields, and its performance continues to improve with advancements in technology and data availability. '''نحوه تنظیم دقیق خط لوله
هنگامی که یک خط لوله اصلی RAG را ساختید، گام بعدی تنظیم دقیق آن برای عملکرد بهینه است. این شامل تنظیم مکرر مؤلفه ها و پارامترهای مختلف برای بهبود کیفیت پاسخ های تولید شده است.
نحوه ارزیابی عملکرد خط لوله
برای ارزیابی اثربخشی خط لوله، می توانید از معیارهایی مانند:
دقت: خط لوله هر چند وقت یک بار پاسخ های صحیح و مرتبط ایجاد می کند؟
ارتباط: اسناد بازیابی شده چقدر با پرس و جو مطابقت دارند؟
انسجام: آیا متن تولید شده ساختار خوبی دارد و به راحتی قابل درک است؟
واقعیت: آیا پاسخ های تولید شده دقیق و مطابق با حقایق شناخته شده هستند؟
روی ساختار شاخص، مدل جاسازی و مدل زبان تکرار کنید
شما می توانید با ساختارهای شاخص مختلف (به عنوان مثال نمایه مسطح، نمایه سلسله مراتبی) آزمایش کنید تا ساختاری را پیدا کنید که به بهترین وجه با داده ها و الگوهای پرس و جو شما مطابقت دارد. استفاده از مدلهای مختلف تعبیهسازی را برای گرفتن تفاوتهای معنایی مختلف در نظر بگیرید. تنظیم دقیق مدل زبان همچنین می تواند توانایی آن را برای ایجاد پاسخ های با کیفیت بالا بهبود بخشد.
با فراپارامترهای مختلف آزمایش کنید
هایپرپارامترها تنظیماتی هستند که رفتار اجزای خط لوله را کنترل می کنند. با آزمایش مقادیر مختلف، می توانید عملکرد خط لوله را بهینه کنید. چند نمونه از هایپرپارامترها عبارتند از:
بعد تعبیه: اندازه بردارهای تعبیه شده
اندازه فهرست: حداکثر تعداد اسناد برای ذخیره در فهرست
آستانه بازیابی: حداقل امتیاز شباهت برای سندی که باید مرتبط در نظر گرفته شود
کاربردهای RAG در دنیای واقعی
خطوط لوله RAG طیف وسیعی از کاربردها از جمله:
چت ربات های پشتیبانی مشتری: ارائه پاسخ های آموزنده و مفید به سوالات مشتری
جستجوی پایگاه دانش: بازیابی کارآمد اطلاعات مرتبط از مجموعه اسناد بزرگ
خلاصه اسناد بزرگ: متراکم کردن اسناد طولانی به خلاصه های مختصر
سیستم های پاسخگویی به سؤال: پاسخ به سؤالات پیچیده بر اساس مجموعه ای از دانش
بهترین اقدامات و ملاحظات RAG
برای ایجاد خطوط لوله RAG موثر، این بهترین شیوه ها را در نظر بگیرید:
کیفیت داده و پیش پردازش: اطمینان حاصل کنید که داده های شما تمیز، سازگار و مرتبط با مورد استفاده شما هستند. داده ها را برای حذف نویز و بهبود کیفیت آن از قبل پردازش کنید.
انتخاب مدل جاسازی: مدلی را انتخاب کنید که برای دامنه و کار خاص شما مناسب باشد. عواملی مانند دقت، کارایی محاسباتی و قابلیت تفسیر را در نظر بگیرید.
بهینه سازی شاخص: ساختار و پارامترهای شاخص را برای بهبود کارایی و دقت بازیابی بهینه کنید.
ملاحظات و سوگیری های اخلاقی: از سوگیری های احتمالی در داده ها و مدل های خود آگاه باشید. اقداماتی را برای کاهش تعصب و اطمینان از عدالت در خط لوله RAG خود انجام دهید.
نتیجه گیری
خطوط لوله RAG یک رویکرد قدرتمند برای استفاده از مدل های زبان بزرگ برای کارهای مختلف ارائه می دهد. با انتخاب دقیق و تنظیم دقیق اجزای یک خط لوله RAG، میتوانید سیستمهایی بسازید که پاسخهای آموزنده، دقیق و مرتبط را ارائه دهند.
نکات کلیدی که باید به خاطر بسپارید:
RAG ترکیبی از بازیابی اطلاعات و تولید زبان است.
Llama-Index فرآیند ساخت خطوط لوله RAG را ساده می کند.
تنظیم دقیق برای بهینه سازی عملکرد خط لوله ضروری است.
RAG دارای طیف گسترده ای از برنامه های کاربردی در دنیای واقعی است.
ملاحظات اخلاقی در ایجاد سیستم های RAG مسئول بسیار مهم است.
همانطور که فناوری RAG به تکامل خود ادامه می دهد، می توان انتظار داشت که در آینده شاهد برنامه های نوآورانه و قدرتمندتر باشیم. تا آن زمان، بیایید منتظر آینده باشیم!
برچسبها
|
|




ارسال نظر