چگونه یک توصیهکننده فیلم درجه تولید در پایتون بسازیم – کتاب راهنمای یادگیری ماشین

پروژه های ساختمانی یکی از موثرترین راه ها برای یادگیری کامل یک مفهوم و توسعه مهارت های ضروری است.
پروژه ها شما را غرق در حل مسئله در دنیای واقعی می کنند، دانش شما را تقویت می کنند و تفکر انتقادی، سازگاری و تخصص مدیریت پروژه را پرورش می دهند.
این راهنما شما را در ساختن یک سیستم توصیه فیلم که با تنظیمات برگزیده کاربر طراحی شده است راهنمایی می کند. ما از مجموعه داده عظیم 10000 فیلمی به عنوان پایه و اساس خود استفاده خواهیم کرد.
در حالی که این رویکرد عمداً ساده است، بلوکهای اصلی ساختمان مشترک برای پیچیدهترین موتورهای توصیه در صنعت را ایجاد میکند.
جعبه ابزار شما: پایتون، پانداها، و آموزش اسکیت
ما از قدرت و تطبیق پذیری پایتون برای دستکاری و تجزیه و تحلیل داده های خود استفاده خواهیم کرد.
کتابخانه پانداها آماده سازی داده ها را ساده می کند و scikit-learn الگوریتم های یادگیری ماشینی قوی مانند CountVectorizer و شباهت کسینوس را ارائه می دهد.
تجربه کاربر کلیدی است، پس ما یک برنامه وب بصری برای انتخاب فیلم و نمایش توصیه ها طراحی خواهیم کرد.
آنچه به دست خواهید آورد:
یک ذهنیت مبتنی بر داده را توسعه دهید: مراحل اساسی در ساختن یک سیستم توصیه را درک کنید.
تکنیکهای اصلی: برای توصیهها به دستکاری دادهها، مهندسی ویژگیها و یادگیری ماشینی بپردازید.
یک راه حل کاربر محور ایجاد کنید: یک تجربه یکپارچه برای پیشنهادهای شخصی فیلم ارائه دهید.
بیا شروع کنیم!
فهرست مطالب
اهمیت یادگیری ماشینی در توصیه های فیلم
CountVetorizer برای پیش پردازش متن
تقسیم داده ها: آموزش، آزمایش و اعتبارسنجی

اهداف ما چیست؟
سیستم توصیه فیلمی را تصور کنید که سلیقه منحصر به فرد شما را درک می کند و به طور مداوم فیلم هایی را پیشنهاد می کند که واقعاً از آنها لذت خواهید برد. با استراتژی درست می توانید این چشم انداز را به واقعیت تبدیل کنید.
آماده سازی داده های اصلی
در اینجا، نحوه باز کردن قدرت داده های فیلم خود را یاد خواهید گرفت. با استفاده از کتابخانه پانداهای پایتون، روی جزئیات کلیدی مانند شناسه فیلم، عنوان، نمای کلی و ژانر تمرکز خواهید کرد.
با ترکیب استراتژیک «نمای کلی» و «ژانر» در «برچسبها»، پایهای قدرتمند برای توصیههای شخصیسازی شده ایجاد خواهید کرد.
یادگیری ماشینی را برای پیشنهادات مناسب مهار کنید
یادگیری ماشینی سلاح مخفی شم است. شما یاد خواهید گرفت که چگونه از CountVetorizer برای تبدیل توضیحات فیلم به داده هایی که سیستم شما می تواند تجزیه و تحلیل کند استفاده کنید. سپس، از شباهت کسینوس برای مشخص کردن فیلمهایی که با اولویتهای شما همسو هستند، استفاده میکنید.
این تکنیکها سیستم توصیهگر شما را قادر میسازد تا هر فیلمی را که تماشا میکنید یاد بگیرد و با آن سازگار شود.
یک تابع توصیه پویا بسازید
شما تابعی خواهید ساخت که به طور ماهرانه شاخص های فیلم و نمرات شباهت را تجزیه و تحلیل می کند و مطمئن می شود که توصیه های شما دقیقاً منعکس کننده سلیقه های در حال تکامل شما است.
این عملکرد جایی است که جادو اتفاق می افتد و انتخاب های گذشته شما را به یک فهرست سفارشی از فیلم هایی که باید تماشا کنید تبدیل می کند.
از طریق سریال سازی از سازگاری اطمینان حاصل کنید
برای حفظ دقت توصیه های خود در طول زمان، با استفاده از کتابخانه ترشی از سریال سازی استفاده خواهید کرد. به این به عنوان حافظه سیستم خود فکر کنید و ویژگی های شخصی سازی دقیق آن را برای جلسات آینده حفظ کنید.
یک رابط کاربری بصری بسازید
یک رابط کاربری خوب طراحی شده حیاتی است. Streamlit به شما این امکان را میدهد تا با عناصری مانند فهرستهای کشویی که توصیهها را بر اساس ورودیهای شما بیشتر اصلاح میکنند، تجربهای کاربرپسند بسازید.
در این راهنما، شما یاد خواهید گرفت که ناوبری و طراحی بصری را برای اطمینان از تعامل یکپارچه و لذت بخش با سیستم خود اولویت بندی کنید.
تحلیل اجمالی رویکرد
این فصل به طور خلاصه مراحل اصلی ساخت موتور توصیه فیلم با استفاده از پایتون را توضیح می دهد. شما سیستمی ایجاد خواهید کرد که پیشنهادات شخصی ارائه می دهد و تجربه کاربری بصری و جذابی را تقویت می کند.
مرحله 1: آماده سازی داده ها
اساس هر سیستم توصیه موفق در داده های به خوبی آماده شده نهفته است.
دیگر اخبار
اپل با نزدیک شدن به جریمه احتمالی اتحادیه اروپا، جزئیات جدیدی در مورد تجارت اسپاتیفای فاش می کند
شما با وارد کردن مجموعه داده فیلم خود (کاگل را برای یک منبع قوی در نظر بگیرید) با استفاده از کتابخانه پانداهای پایتون شروع خواهید کرد. شما بر درک ساختار داده های خود، پرداختن به مقادیر از دست رفته و اطمینان از آماده بودن آن برای تجزیه و تحلیل تمرکز خواهید کرد.
مرحله 2: مهندسی ویژگی برای بینش
تأثیرگذارترین ویژگی ها را جدا کنید - شناسه فیلم، عنوان، نمای کلی و ژانر رقبای قوی هستند.
کلید باز کردن قفل شخصیسازی ستون «برچسبها» است. شما یاد خواهید گرفت که چگونه "نمای کلی" و "ژانر" را ادغام کنید تا هم توضیحات متنی و هم دسته بندی ها را به تصویر بکشید. این رویکرد یکپارچه توانایی سیستم شما را در کاهش فیلم هایی که کاربران شما از آنها لذت خواهند برد را افزایش می دهد.
مرحله 3: الگوریتم خود را هوشمندانه انتخاب کنید
CountVetorizer از scikit-learn یک ابزار قدرتمند برای تبدیل "برچسب" شما به داده های عددی قابل استفاده است. شما یاد خواهید گرفت که چگونه شباهت کسینوس را برای محاسبه میزان تراز کردن فیلم ها بر اساس این ویژگی ها اعمال کنید.
کارشناسان اغلب شباهت کسینوس را به دلیل توانایی آن در اندازه گیری دقیق روابط بین آیتم ها، به ویژه زمانی که ابعاد متعدد درگیر هستند، ترجیح می دهند.
مرحله 4: موتور توصیه خود را بسازید
شما تابعی را طراحی خواهید کرد که به طور هوشمند شاخص های فیلم و نمرات شباهت را تجزیه و تحلیل می کند.
این قلب سیستم شما است، جایی که توصیههای مناسبی را ایجاد میکنید که منعکس کننده ترجیحات کاربر است. شما باید یک رویکرد ساده را برای موفقیت اولیه در اولویت قرار دهید - همیشه می توانید پیچیدگی را بعداً معرفی کنید.
مرحله 5: افزایش تجربه
سریال سازی (با استفاده از ماژول ترشی پایتون) تضمین می کند که سیستم شما انتخاب های گذشته را برای توصیه های ثابت به یاد می آورد.
شما از Streamlit برای ایجاد یک رابط کاربر پسند با حداقل تلاش برای کدنویسی استفاده خواهید کرد. آپشن های ی مانند فهرستهای کشویی تعامل یکپارچه و شخصیسازی بیشتر نتایج را ترویج میکنند.
مرحله 6: مایل اضافی را طی کنید
سپس API هایی مانند TMDb را برای نمایش پویا پوسترهای فیلم ادغام خواهید کرد و یک عنصر بصری غنی به توصیه های خود اضافه می کنید. ویژگی هایی مانند چرخ فلک های تصویر را برای یک رابط پویا و همه جانبه در نظر بگیرید.
این سیستم پایه می تواند به عنوان یک سکوی پرتاب برای کاوش تکنیک ها و ویژگی های پیشرفته تر برای بهینه سازی مداوم توصیه های شما عمل کند.

اهمیت یادگیری ماشینی در توصیه های فیلم
بیایید تحلیل کنیم که چگونه یادگیری ماشینی توصیههای فیلم را متحول میکند و تجربههای شخصیسازی شدهای را ارائه میکند که کاربران را درگیر میکند.
یادگیری تحت نظارت: پیش بینی تنظیمات کاربر
یادگیری تحت نظارت پایه ای برای پیش بینی فیلم هایی است که کاربر از آن لذت خواهد برد. این دادههای تاریخی مانند رتبهبندیهای گذشته و مشاهده تاریخچه را برای کشف الگوها تجزیه و تحلیل میکند.
به عنوان مثال، اگر کاربر عاشق فیلم های علمی تخیلی است، یک مدل نظارت شده که بر اساس این داده ها آموزش دیده است، به طور هوشمندانه فیلم های علمی تخیلی دیگری را توصیه می کند.
یادگیری بدون نظارت: یافتن ارتباطات پنهان
یادگیری بدون نظارت در یافتن شباهتهای بین فیلمها بر اساس آپشن های ی مانند ژانر، کارگردان یا داستان عالی است - حتی زمانی که بازخورد مستقیم کاربر محدود است. ممکن است فیلمها را در گروههایی مانند «اکشن»، «کمدی رمانتیک» یا «ترسناک» دستهبندی کند و ابزاری قدرتمند برای توصیهها ارائه دهد.
یادگیری تقویتی: بهبود مستمر
یادگیری تقویتی شخصی سازی را به سطح بعدی می برد. سیستم توصیه می کند، پاسخ کاربر (رتبه بندی، تماشا/بدون تماشا) را تجزیه و تحلیل می کند و دائما تطبیق می دهد. این رویکرد پویا تضمین میکند که توصیهها با تغییر تنظیمات کاربر مرتبط هستند.
چگونه رویکرد خود را انتخاب کنید
یادگیری نظارت شده: بهترین زمانی که رتبهبندی/سابقه مشاهده کاربر فراوانی دارید.
یادگیری بدون نظارت الگوها را در داده های فیلم، حتی با بازخورد محدود، آشکار می کند.
یادگیری تقویتی: ایده آل برای سازگاری در زمان واقعی و به حداکثر رساندن رضایت کاربر در دراز مدت.
بهترین سیستم ها از هر سه استفاده می کنند
ترکیب استراتژیک این تکنیک ها اغلب بهترین ایده است! یادگیری نظارت شده رتبهبندیها را پیشبینی میکند، یادگیری بدون نظارت ارتباطات پنهان فیلم را پیدا میکند، و یادگیری تقویتی با تعاملات زمان واقعی سازگار است.
این ترکیب دقت توصیه و رضایت کاربر را به حداکثر می رساند.
داده ها کلید موفقیت هستند
داده های متنوع و با کیفیت بالا برای موفقیت بسیار مهم است:
مبانی فیلم: عناوین، ژانرها.
بینش کاربر: جمعیت شناسی، سابقه مشاهده، فعالیت رسانه های اجتماعی.
تبدیل داده ها: عادی سازی رفتار بی طرفانه توسط مدل شما را تضمین می کند. TF-IDF داده های متنی (توضیحات، تحلیل ها) را به اعداد قابل استفاده تبدیل می کند.
پیش پردازش ضروری است
داده های پاک از اهمیت بالایی برخوردار است. مقادیر از دست رفته را مدیریت کنید، موارد تکراری را حذف کنید و هر چیزی را که ممکن است نتایج را منحرف کند فیلتر کنید. این ممکن است ثانویه به نظر برسد، اما تأثیر قابل توجهی بر دقت توصیه دارد.

جمع آوری و پیش پردازش داده ها
بسیار خوب، اکنون تقریباً آماده ساختن سیستمی هستید که تنظیمات برگزیده فیلم شما را درک کند. من مراحل کلیدی را در اینجا تشریح میکنم و به شما قدرت میدهم که دادههای فیلم را تجزیه و تحلیل کنید و توصیههایی را ارائه دهید.
جعبه ابزار توسعه شما
Python Power: پانداها را برای دستکاری داده ها و یادگیری scikit برای جادوی یادگیری ماشین مهار کنید. ما خواهیم کرد
محیط های کدنویسی: اسلحه خود را انتخاب کنید - Jupyter Notebook برای اکتشاف تعاملی، VS Code برای توسعه، یا Google Colab برای همکاری مبتنی بر ابر.
جمع آوری داده ها
مجموعه داده خود را پیدا کنید: با مجموعه داده های Kaggle شروع کنید یا جایگزین هایی مانند TMDb را تحلیل کنید. به دنبال مجموعه ای غنی با عناوین فیلم، توضیحات، ژانرها و در حالت ایده آل، رتبه بندی کاربران باشید.
آن را بارگذاری کنید: pd.read_csv() مجموعه داده شما را به یک DataFrame پاندا می آورد که برای تجزیه و تحلیل آماده است.
اطلاعات خود را درک کنید
نگاه اول: movies.head(10) ساختار داده های شما را نشان می دهد.
آمار: movies.describe() آمار خلاصه را آشکار می کند.
مقادیر از دست رفته: movies.isnull().sum() شکاف های داده را علامت گذاری می کند - پاکسازی بسیار مهم است!
مهندسی ویژگی
روی موتور خود تمرکز کنید: ویژگی های ضروری را هدف قرار دهید - شناسه، عنوان، نمای کلی و ژانر.
مزیت «برچسبها»: «نمای کلی» و «ژانر» را برای نمایش غنیتر هر فیلم ترکیب کنید.
ساده: ستون های اضافی را رها کنید تا کارایی را به حداکثر برسانید.
دادههای متنی خود را آماده کنید: ماشینها بهطور متفاوتی میخوانند
CountVetorizer: تبدیل متن به عدد شما. برای نتایج بهینه، پارامترها را آزمایش کنید.
تبدیل "برچسب ها": توضیحات غنی خود را به قالبی تبدیل کنید که مدل شما قابل درک است.
اندازهگیری شباهت: کلید توصیههای مرتبط
شباهت کسینوس: استاندارد صنعتی برای مقایسه ویژگی های مبتنی بر متن. برای درک چگونگی کارکرد آن عمیق تر حفاری کنید!
ماتریس شباهت: این خروجی قلب موتور توصیه شم است.
عملکرد توصیه خود را بسازید
منطق کلید است: تابعی را طراحی کنید که شاخص های فیلم، امتیازات شباهت را تجزیه و تحلیل می کند و پیشنهادات هدفمند را ارائه می دهد.
تست درایو: recommend("Iron Man") امتحان کنید - آیا به نتایج منطقی رسیدید؟
پیشرفت خود را ذخیره کنید
Pickle Power: داده های پردازش شده و مدل شباهت خود را برای راه اندازی مجدد سریع و بهبودهای آینده سریال کنید.
انتخاب ویژگی و مهندسی
انتخاب ویژگی و مهندسی جایی است که جادو در سیستم های توصیه فیلم اتفاق می افتد. با ایجاد مجموعه کاملی از نقاط داده، به مدل خود قدرت میدهید تا توصیههایی ارائه کند که برای هر کاربر طراحی شده است. بیایید پتانسیل کامل این فرآیند را باز کنیم:
از قدرت داده های متنی با TF-IDF (و فراتر از آن!) استفاده کنید.
متن بهعنوان گنج: توضیحات فیلم، بررسیها و پچ پچهای رسانههای اجتماعی ارزش زیادی دارند اگر بدانید چگونه آن را استخراج کنید. TF-IDF نقطه شروع قدرتمندی است، اما تنها ابزار موجود در زرادخانه شما نیست.
تجزیه و تحلیل احساسات : ابزارهایی که لحن یا محتوای احساسی متن را تجزیه و تحلیل میکنند، میتوانند لایه دیگری از اولویتها را آشکار کنند ("تاریک و پرتعلیق" در مقابل "روشن دل و سرگرم کننده").
مدلسازی موضوع : موضوعات اساسی و مفاهیم تکرارشونده را در توضیحات یا بررسیها شناسایی کنید. این به ویژه برای یافتن فیلم هایی که حال و هوای مشابهی دارند مفید است، حتی اگر ژانرها متفاوت باشند.
مدیریت همبستگی ویژگی ها: بهره وری و بینش های پنهان
همبستگی به عنوان یک نقشه راه: چگونگی ارتباط ویژگی ها با یکدیگر را تجزیه و تحلیل کنید. همبستگیهای قوی نشاندهنده افزونگی است، در حالی که همبستگیهای ضعیف ممکن است به حوزههای استفاده نشده ترجیحات کاربر اشاره کند.
داده ها دروغ نمی گویند: فرضیات نسازید! اجازه دهید تجزیه و تحلیل داده های شما ارتباطات غیرمنتظره بین ویژگی ها را نشان دهد. شاید کاربرانی که از درامهای تاریخی لذت میبرند، تمایلی شگفتانگیز به کمدیهای علمی تخیلی عجیب و غریب دارند.
ساده سازی و بهینه سازی: از بینش های همبستگی خود برای حذف ویژگی های غیر ضروری، افزایش کارایی مدل خود و جلوگیری از برازش بیش از حد استفاده کنید.
مهندسی ویژگی: نمونه های دنیای واقعی (گسترش یافته)
فراتر از ژانرها: برای شخصیسازی بینظیر، دستهبندیهای گسترده را به زیرژانرهای خردهریز یا علایق خاص تقسیم کنید.
بازخورد کاربر Goldmine: فقط رتبه بندی ها را ردیابی نکنید. نرخ های تکمیل، زمان تماشا، الگوهای جستجو و حتی نظرات را برای شاخص های ترجیحی ظریف تجزیه و تحلیل کنید.
غیرمنتظره را در آغوش بگیرید: ویژگی هایی را بر اساس کارگردان، بازیگران، فیلمبردار یا حتی سبک موسیقی متن ایجاد کنید. اینها می توانند به کاربرانی با سلیقه های خاص پاسخ دهند.
برچسبگذاری دوست شماست: به کاربران اجازه دهید برچسبهای خود را ایجاد کنند یا از پردازش زبان طبیعی برای استخراج مضامین کلیدی از توضیحات فیلم برای توصیههای بسیار مناسب استفاده کنند.
سطح بالا: استراتژی های پیشرفته
دینامیک را در آغوش بگیرید: زمان روز، موقعیت مکانی، حال و هوای فعلی یا سابقه تماشای اخیر را برای شخصی سازی در زمان واقعی در نظر بگیرید.
فراداده مهم است: سال اکران فیلم، جوایز یا حتی استقبال منتقدان میتواند قدرت پیشبینی ارزشمندی را به خصوص زمانی که با آپشن های دیگر ترکیب شود، اضافه کند.
آزمایش و یادگیری: با یک پایه محکم شروع کنید، سپس ترکیبات مختلف ویژگی را آزمایش کنید. معیارهای دقت مدل خود را برای هدایت فرآیند اصلاح خود نظارت کنید. از امتحان کردن چیزی خارج از جعبه نترسید!
نکته تخصصی: به یاد داشته باشید، حتی با تکنیک های پیشرفته، برخی از قدرتمندترین ویژگی ها می توانند به طرز شگفت آوری ساده باشند. پربیننده ترین کارگردان یا بازیگر مورد علاقه یک کاربر ممکن است تنها چیزی باشد که برای یک پیشنهاد واقعی نیاز دارید.

CountVetorizer برای پیش پردازش متن
بردارسازی متن یک فرآیند مهم در یادگیری ماشینی است زیرا داده های متن را به قالب عددی تبدیل می کند که الگوریتم ها می توانند به طور موثر پردازش کنند. این دگرگونی به ویژه در هنگام برخورد با حجم زیادی از داده های متنی قابل توجه است.
CountVetorizer، ابزاری پرکاربرد در پردازش زبان طبیعی (NLP)، نقش کلیدی در پردازش داده های متن ایفا می کند. این داده های متنی را به یک فرم ساختاریافته تبدیل می کند، به ویژه یک ماتریس پراکنده از تعداد نشانه ها، که برای مدل های یادگیری ماشین بسیار مناسب است.
در سیستم توصیه فیلم ما، CountVectorizer برای تعیین کمیت توضیحات فیلم ضروری است. با کمی کردن توضیحات، این سیستم می تواند فیلم ها را بر اساس شباهت های متنی به طور دقیق مقایسه و توصیه کند.
برای پیاده سازی CountVetorizer در پایتون، می توانید از کد مثال زیر استفاده کنید:
# Import CountVectorizer again (redundant import) from sklearn.feature_extraction.text import CountVectorizer # Initialize a CountVectorizer object with a maximum of 10,000 features and English stop words cv = CountVectorizer(max_features=10000, stop_words='english') # Fit the CountVectorizer to the 'tags_clean' column and transform the text data into a numerical vector representation vector = cv.fit_transform(new_data['tags_clean'].values.astype('U')).toarray()به یاد داشته باشید که CountVetorizer را برای دادههای فیلم با تنظیم پارامترهای آن برای ثبت جنبههای منحصربهفرد توضیحات فیلم، مانند اصطلاحات خاص ژانر، سفارشی کنید.
ایجاد تعادل بین دقت و کارایی در برداری بسیار مهم است. یافتن سطح مناسب عمق در برداری با حفظ کارایی محاسباتی برای یک سیستم توصیه پاسخگو و دقیق بسیار مهم است.
همچنین، برای مجموعه دادههای فیلم بزرگ، اجرای شیوههایی مانند کاهش ابعاد و بهروزرسانی منظم واژهنامه میتواند عملکرد CountVectorizer را بهینه کند.
مبانی داده های متنی در سیستم های توصیه
دادههای متنی در فیلمها، از جمله توصیفها و ژانرها، ذاتاً بیساختار و متنوع هستند، و چالشی را در استانداردسازی دادهها برای الگوریتمهای پیشنهادی ایجاد میکنند.
بیشتر بخوانید
اما تجزیه و تحلیل دقیق داده های متنی نقش مهمی در افزایش توصیه های فیلم ایفا می کند. با درک عمیق محتوای فیلم ها از طریق تجزیه و تحلیل داده های متنی، سیستم توصیه می تواند توصیه های دقیق و شخصی تری ارائه دهد.
هنگام برخورد با متن بدون ساختار در توضیحات فیلم، پرداختن به تفاوت های ظریف زبان طبیعی، مانند اصطلاحات، زمینه و احساسات ضروری است. این عناصر در درک محتوای فیلم و اطمینان از توصیه های دقیق بسیار مهم هستند.
برای رفع این چالش ها، باید مقداری پیش پردازش متن را انجام دهید تا داده ها را تمیز و آماده کنید. این شامل حذف نویسههای نامربوط، تصحیح غلطهای املایی و استاندارد کردن قالبهای متن برای سازگاری است.
توکنسازی، فرآیند تجزیه متن به کلمات یا نشانهها، تجزیه و تحلیل و کمیسازی را آسانتر میکند. همچنین، حذف کلمات توقف متداول و استفاده از ریشه (stemming) که کلمات را به شکل ریشه ای کاهش می دهد، به تمرکز بر معنی دارترین عناصر متن کمک می کند.
پیش پردازش متن برای برداری
پیش پردازش داده های متنی یک مرحله اساسی در آماده سازی داده ها برای تجزیه و تحلیل در زمینه پردازش زبان طبیعی (NLP) است. این شامل تمیز کردن و استاندارد کردن داده ها برای اطمینان از سازگاری است. این شامل حذف کاراکترهای نامربوط، تصحیح غلطهای املایی و استاندارد کردن قالبهای متن است.
به عنوان مثال، می توانید از توابع دستکاری رشته در پایتون برای حذف کاراکترهای خاص و عبارات منظم برای تصحیح اشتباهات تایپی رایج استفاده کنید.
Tokenization یکی دیگر از مراحل مهم در پیش پردازش داده های متنی است. این شامل شکستن متن به کلمات یا نشانه های جداگانه است که تجزیه و تحلیل و کمیت کردن آن را آسان تر می کند.
در پایتون می توانید از کتابخانه های مختلفی مانند NLTK یا spaCy برای توکن کردن داده های متنی استفاده کنید. به عنوان مثال، NLTK تابع word_tokenize() را ارائه می دهد که متن را به کلمات تقسیم می کند.
حذف کلمات توقف و استفاده از پایه نیز از مراحل مهم در پیش پردازش متن هستند.
کلمات توقف کلماتی هستند که معمولاً استفاده می شوند که معنای زیادی ندارند، مانند "the"، "and" یا " است. " حذف این کلمات به تمرکز بر معنی دارترین عناصر متن کمک می کند.
ریشه کردن کلمات را به شکل ریشه ای کاهش می دهد، که می تواند به درک ماهیت کلمه کمک کند. کتابخانههایی مانند NLTK فهرست های توقف کلمات و الگوریتمهای پایه، مانند الگوریتم ریشه پورتر را ارائه میکنند.
برای پیاده سازی این مراحل پیش پردازش در پایتون، می توانید از کتابخانه ها و توابع مختلف استفاده کنید. به عنوان مثال، NLTK توابعی را برای حذف کلمات توقف و اعمال ریشه ارائه می دهد. در اینجا یک قطعه کد نمونه است:
# Importing necessary modules from NLTK for text preprocessing. import nltk import re from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer from nltk.tokenize import word_tokenize # Downloading NLTK resources necessary for text processing. nltk.download('punkt') nltk.download('wordnet') nltk.download('stopwords')مقدمه ای بر CountVetorizer
CountVetorizer یک ابزار قدرتمند در زمینه پردازش زبان طبیعی (NLP) است که داده های متنی را به ماتریسی از تعداد نشانه ها تبدیل می کند. این یک راه ساده اما موثر برای تجزیه و تحلیل متن با شمارش فراوانی هر کلمه در متن ارائه می دهد. این رویکرد به ویژه برای وظایف اساسی NLP مفید است و به طور گسترده در یادگیری ماشین و علم داده استفاده می شود.
برای درک نحوه عملکرد CountVetorizer، بیایید به ریاضیات پشت آن بپردازیم. الگوریتم با ایجاد یک فرهنگ لغت از تمام کلمات منحصر به فرد موجود در متن آغاز می شود. سپس وقوع هر کلمه را در هر سند شمارش می کند و در نتیجه نمایش ماتریسی از داده های متنی ایجاد می شود. این ماتریس فرکانس هر کلمه را می گیرد و امکان تجزیه و تحلیل و مقایسه بیشتر را فراهم می کند.
در مقایسه با سایر تکنیکهای برداری متن مانند TF-IDF، CountVetorizer تنها بر فرکانسهای کلمات تمرکز میکند و آن را سادهتر و سادهتر میکند. این سادگی برای کارهای اساسی NLP مفید است و پایه محکمی برای تجزیه و تحلیل بیشتر فراهم می کند.
برای پیاده سازی CountVetorizer در پایتون، می توانید مراحل زیر را دنبال کنید:
# Importing CountVectorizer from scikit-learn to convert text documents to a matrix of token counts. from sklearn.feature_extraction.text import CountVectorizer # Installing scikit-learn if not already installed. pip install scikit-learn # Initializing CountVectorizer with a limit on the maximum number of features and excluding common English stop words. cv = CountVectorizer(max_features=10000, stop_words='english') # Fitting the CountVectorizer to the cleaned tags and transforming the text data into a numerical array. vector = cv.fit_transform(new_data['tags_clean'].values.astype('U')).toarray() در این قطعه کد، کلاس CountVetorizer را از کتابخانه sklearn وارد می کنیم. سپس یک نمونه از CountVetorizer ایجاد می کنیم و آن را در داده های متنی قرار می دهیم. در نهایت، داده های متنی را با استفاده از روش transform() به یک ماتریس فرکانس کلمه تبدیل می کنیم.
برای بهینه سازی CountVetorizer برای نیازهای خاص خود، سفارشی کردن پارامترهای آن مهم است. برای مثال، میتوانید پارامتر max_features برای محدود کردن تعداد آپشن های ماتریس تنظیم کنید، یا از پارامتر ngram_range برای در نظر گرفتن عبارات چند کلمه استفاده کنید. همچنین می توانید یک فهرست سفارشی از stop_words برای حذف کلمات رایج که ممکن است معنی زیادی نداشته باشند ارائه دهید.
شایان ذکر است که در حالی که CountVetorizer یک ابزار قدرتمند است، ایجاد تعادل بین دقت و کارایی بسیار مهم است. برای مجموعه دادههای بزرگ، اجرای شیوههایی مانند کاهش ابعاد و بهروزرسانیهای منظم واژهنامه میتواند عملکرد را بهینه کند.
نحوه پیاده سازی CountVetorizer در پایتون
پیاده سازی CountVetorizer در پایتون یک فرآیند ساده است. ابتدا کلاس CountVetorizer را از کتابخانه sklearn وارد کنید. سپس، یک نمونه از CountVectorizer، مانند cv = CountVectorizer() ایجاد کنید. سپس، CountVetorizer را با استفاده از متد fit_transform() که داده ها را به یک ماتریس فرکانس کلمه تبدیل می کند، به داده های متنی خود برسانید.
در اینجا یک نمونه کد کد آمده است:
# Initializing CountVectorizer with a limit on the maximum number of features and excluding common English stop words. cv = CountVectorizer(max_features=10000, stop_words='english') # Fitting the CountVectorizer to the cleaned tags and transforming the text data into a numerical array. vector = cv.fit_transform(new_data['tags_clean'].values.astype('U')).toarray()هنگام سفارشی سازی CountVetorizer برای داده های فیلم، تنظیم پارامترها را برای ثبت جنبه های منحصر به فرد توضیحات فیلم در نظر بگیرید.
برای مثال، میتوانید پارامتر max_features را برای محدود کردن تعداد آپشن های ماتریس تنظیم کنید یا از پارامتر ngram_range برای تجزیه و تحلیل عبارات چند کلمه استفاده کنید. همچنین، ارائه یک فهرست سفارشی از stop_words میتواند کلماتی که معمولاً استفاده میشوند را حذف کند که ممکن است معنای زیادی نداشته باشند.
یافتن تعادل مناسب بین دقت و کارایی در بردارسازی بسیار مهم است. برای مجموعه دادههای فیلم بزرگ، اعمالی مانند کاهش ابعاد و بهروزرسانیهای منظم واژهنامه را در نظر بگیرید. این شیوهها عملکرد CountVetorizer را بهینه میکنند و یک سیستم توصیه پاسخگو را تضمین میکنند.
CountVetorizer در سیستم توصیه فیلم
CountVectorizer نقش مهمی در تبدیل توضیحات فیلم به یک قالب قابل تحلیل عددی دارد.
به عنوان مثال، اگر شرح فیلمی مانند "یک ماجراجویی حماسی در فضا" داشته باشیم، CountVetorizer ابتدا این جمله را به کلمات جداگانه ["An"، "epic"، "adventure"، "in"، "space"] تبدیل می کند. سپس، کلمات توقف متداول (در این مورد، "An" و "in") را که سهم قابل توجهی در معنای کلی ندارند حذف می کند. در نهایت، وقوع کلمات معنی دار باقی مانده را شمارش می کند.
این فرآیند یک متن را به یک بردار عددی تبدیل می کند و آن را برای الگوریتم های ریاضی قابل دسترس می کند.
مرحله بعدی شامل استفاده از داده های برداری شده برای ایجاد یک ماتریس شباهت است. این ماتریس برای شناسایی فیلم هایی که شبیه یکدیگر هستند حیاتی است.
به عنوان مثال، اگر مجموعه داده ما حاوی توضیحات برداری از فیلم های A و B باشد، از متریک شباهت کسینوس برای محاسبه امتیاز شباهت بین آنها استفاده می شود. این امتیاز بر اساس بردارهای توصیفی، میزان شباهت محتویات دو فیلم را مشخص می کند.
رویکرد ساختار یافته CountVetorizer امکان مقایسه عینی و دقیق محتوای فیلم را فراهم می کند.
به عنوان مثال، اگر کاربری از «مرد آهنی» لذت میبرد، سیستم میتواند فیلمهای دیگری با مضامین مشابه را با مقایسه توصیفات بردار آنها پیدا کند. این منجر به توصیه های دقیق تر و شخصی تر می شود.
فرض کنید «مرد آهنی» به صورت [0، 1، 2] و فیلم دیگری «انتقامجویان» به صورت [1، 1، 1] بردار شده است، امتیاز شباهت محاسبهشده به تعیین میزان نزدیکی «انتقامجویان» به «انتقامجویان» کمک میکند. مرد آهنی» از نظر محتوا.
این مثالها کاربرد عملی CountVetorizer و شباهت کسینوس را در افزایش عملکرد یک سیستم توصیه فیلم نشان میدهند. آنها انتقال از متن خام به فرمت های برداری و نحوه استفاده از این بردارها برای یافتن فیلم های مشابه را نشان می دهند و درک جامعی از فرآیندهای اساسی ارائه می دهند.

یادگیری ماشین برای توصیه
درک نقاط قوت و تفاوت های ظریف هر رویکرد، کلید طراحی یک سیستم توصیه است که واقعاً به کاربران شما پاسخ می دهد.
فیلترینگ مبتنی بر محتوا: قدرت توصیه های هدفمند
توصیههای "ساخته شده برای شما": این روش در تطبیق ترجیحات شناخته شده کاربر با فیلمهایی که دارای آپشن های اصلی مشابه هستند، برتری دارد. تجزیه و تحلیل ژانر، بازیگران، کارگردان، مضامین طرح، و حتی لمس سبک از توضیحات فیلم به شما امکان می دهد توصیه های بسیار هدفمندی پیدا کنید.
اکتشافات جدید، راه شما: جواهرات پنهان را کشف کنید. اگر عاشق داستانگویی بصری یا طنز بینظیر یک فیلم اخیر بودید، الگوریتمهای مبتنی بر محتوا میتوانند فیلمهای کمتر شناخته شدهای را ارائه دهند که دارای این ویژگیها هستند. این حتی باهوش ترین فیلمسازان را نیز خوشحال می کند.
مشکلات بالقوه: اتکای بیش از حد می تواند به توصیه های قابل پیش بینی منجر شود. با این تکنیک ها به طور فعال این را کاهش دهید:
توصیههای متنوع: عمداً فیلمهایی را از ژانرهایی که کاربر اخیراً کاوش نکرده است توصیه کنید.
ویژگی های اکتشافی: به کاربران اجازه می دهد تا تعادل بین ارتباط و تازگی را کنترل کنند. شاید آنها یک روز علاقه مندی های آشنا و روز دیگر اکتشافات غیرمنتظره می خواهند.
بازخورد صریح: به کاربران اجازه دهید توصیهها را بهعنوان «جایگاه» یا «سبک من نیست» پرچمگذاری کنند تا درک سیستم از سلیقه منحصربهفردشان اصلاح شود.
فیلتر مشارکتی: توصیه هایی با الهام از جامعه شما
بهرهگیری از خرد جمعی: به رتبهبندیهای جمعآوری شده و عادات مشاهده کاربران با سلیقههای مشابه ضربه بزنید. این استراتژی قدرت اکتشاف سرسام آور را باز می کند - مثل این است که جامعه ای از تماشاگران فیلم متخصص شما را راهنمایی می کنند.
پویا و سازگار: توصیه ها به طور طبیعی در کنار ترجیحات کاربران شما تکامل می یابند. این سازگاری آنها را درگیر نگه می دارد، و همیشه احساس می کنند که سیستم آنها را "دریافت" می کند.
غلبه بر چالش ها:
«شروع سرد»: برای فیلمهای جدید یا کاربران بدون سابقه، فیلتر مبتنی بر محتوا نقطه شروعی است. همچنین می توانید کاربران جدید را تشویق کنید تا اولویت های اولیه را هنگام ثبت نام ارائه دهند.
مقیاس پذیری: مجموعه داده های بزرگ نیازمند الگوریتم های تخصصی هستند. گزینه هایی مانند فاکتورسازی ماتریس را برای مدیریت کارآمد داده های پراکنده کاوش کنید.
سیستم های ترکیبی: بهترین های هر دو جهان
ترکیب برنده: به طور یکپارچه این تکنیک ها را برای حداکثر شخصی سازی و امکان شگفتی های لذت بخش ترکیب کنید. این رویکرد تجربه کاربری را در جلو و مرکز قرار می دهد.
پیاده سازی استراتژیک: با یک سیستم قوی مبتنی بر محتوا برای ارزش فوری، حتی با داده های کاربر محدود، شروع کنید. با رشد پایگاه کاربر و منابع محاسباتی خود، فیلتر مشارکتی را اضافه کنید.
تنظیم دقیق برای موفقیت: این معیارهای موفقیت را رصد کنید:
دقت: آیا توصیهها به طور مداوم به نتیجه میرسند؟
تنوع: آیا سیستم از کبوتر کردن کاربران جلوگیری می کند؟
رضایت کاربر: بازخورد مستقیم (نظرسنجی، داده های تعامل) نشان می دهد که چه چیزی واقعاً کار می کند.
بردن آن به سطح بعدی: ملاحظات پیشرفته
فراتر از رتبهبندیها: بازخورد ضمنی مانند:
زمان تماشا: آیا فیلم را تمام کردند؟ دوباره تماشای قطعات؟
الگوهای پیمایش: مواردی را که جستجو میکنند، روی آن میروند یا به فهرستهای تماشا اضافه میکنند.
تعامل: نظرات، اشتراکگذاری - به ویژه برای محتوای جدید بدون رتبهبندی مفید است.
توصیه های آگاه به زمینه: سیستم خود را بیش از حد مرتبط کنید:
1. زمان مهم است: یک کمدی خوش قلب ممکن است برای شب های هفته عالی باشد، اما یک درام جذاب برای تماشای آخر هفته بهتر است.
2. همسان سازی خلق و خوی: در صورتی که کاربر خسته به نظر می رسد، چیز خوشایندی را پیشنهاد کنید، یا اگر او ضعیف به نظر می رسد یک کلاسیک آرامش بخش ارائه دهید.
3. مبتنی بر مکان: نسخههای جدید پخش شده در تئاتر محلی خود را برجسته کنید.
تعالی داده ها: بنیادی برای توصیه های دقیق
انتخاب مجموعه داده: منابع معتبر مانند TMDb و Kaggle را برای دادههای جامع فیلم در اولویت قرار دهید. برای دستیابی به شخصیسازی عمیقتر، مجموعه دادههای اضافی را که شامل تعاملات کاربر (رتبهبندی، بررسی)، سیگنالهای اجتماعی یا دریافت انتقادی خارجی است، کاوش کنید.
یکپارچگی داده: تلاش قابل توجهی را به تمیز کردن و پیش پردازش اختصاص دهید. از پانداها برای دستکاری و اعتبارسنجی داده ها استفاده کنید. برای جلوگیری از تعصب مدل و اطمینان از صحت توصیه، مقادیر گمشده، نقاط دورافتاده و ناسازگاری ها را به صورت استراتژیک تحلیل کنید.
مهندسی ویژگی: برای غنیسازی توصیههای خود، این ویژگیها را در نظر بگیرید:
1. تاریخ انتشار: نسخه های اخیر، کلاسیک یا دوره های خاص را هدف قرار دهید.
2. بازیگران، خدمه، تولید: توسل به علایق خاص و ترجیحات سبکی.
3. جوایز و نامزدها: ممکن است نشان دهنده ارزش تولید بالاتر یا تحسین منتقدان باشد.
انتخاب الگوریتم و بهینه سازی برای عملکرد پیشرفته
استراتژی را با اهداف همسو کنید: فیلتر مبتنی بر محتوا برای شخصیسازی اولیه ایدهآل است، اما با افزایش دادهها و منابع محاسباتی، رویکردهای ترکیبی را در نظر بگیرید. فیلتر کردن مشارکتی میتواند سرندیپیتی و مقیاسپذیری را باز کند.
پالایش تکراری: تکنیک های متنوع تجزیه و تحلیل متن (مدل سازی موضوع، تحلیل احساسات) را برای کشف ترجیحات پنهان کاوش کنید. به طور مداوم آزمایش کنید، معیارهای کلیدی را دنبال کنید، و پیکربندی های الگوریتم را بهینه کنید تا کیفیت توصیه ها را در طول زمان بهبود بخشید.
معیارهای مهم: بر دقت (توصیهها چقدر مرتبط هستند) و یادآوری (آیا سیستم پیشنهادهای متنوعی ارائه میدهد؟) تمرکز کنید. برای مجموعه داده های بزرگ، سود تجمعی با تخفیف عادی (NDCG) را در نظر بگیرید تا توانایی مدل خود را برای رتبه بندی مرتبط ترین گزینه ها در بالا اندازه گیری کنید.
مقیاس بندی موفقیت: به طور فعال در مورد فاکتورسازی ماتریس و الگوریتم های مبتنی بر نمودار برای عملکرد کارآمد با مجموعه داده های وسیع و روابط پیچیده کاربر و فیلم تحقیق کنید.
برای تعامل و وفاداری، تجربه کاربر را در اولویت قرار دهید
متعادل کردن قدرت با قابلیت استفاده: در حالی که Streamlit برای نمونه سازی موثر است، Flask یا Django را برای برنامه های کاربردی وب کامل در نظر بگیرید. این چارچوبها انعطافپذیری را برای آپشن های ی مانند حسابهای کاربری، فیلترینگ پیشرفته و فهرستهای پیگیری مداوم ارائه میدهند.
جذابیت بصری: روی طراحی جذاب بصری سرمایه گذاری کنید. پوسترهای فیلم، تریلرها (از طریق ادغام های API)، و چرخ و فلک های بصری را برای تعامل و کشف کاربر ترکیب کنید.
حلقه های بازخورد: سیستم های رتبه بندی قوی و مکانیسم های بازخورد کیفی را پیاده سازی کنید. این داده ها را تجزیه و تحلیل کنید تا زمینه های بهبود را مشخص کنید، تصمیم گیری کاربر را درک کنید، و به طور مداوم فرآیند توصیه خود را اصلاح کنید.
راهنمای تخصصی: استراتژیهایی برای اصلاح آینده
سازگاری در زمان واقعی: یادگیری تقویتی را برای تنظیم پویا توصیه ها بر اساس بازخورد فوری کاربر (کلیک ها، زمان تماشا و غیره) کاوش کنید.
توصیههای آگاه از زمینه: برای پیشنهادات سفارشیتر، موقعیت کاربر، خلق و خوی استنباطشده یا زمینه اجتماعی (انفرادی در مقابل تماشای گروهی) را فاکتور کنید.
هوش مصنوعی مسئول: به طور فعال به ملاحظات اخلاقی در سیستم های توصیه توجه کنید. معیارهای انصاف تحقیق ، تکنیک های کاهش تعصب و ارتباط شفاف با کاربران در مورد استفاده از داده ها.
سیستم های در حال تحول
مدل های یادگیری ماشین که به طور مداوم سازگار می شوند ، برای این دامنه پویا ایده آل هستند. این رویکردها را در نظر بگیرید:
یادگیری تقویت: سیستمهایی که با آزمایش و خطا یاد می گیرند ، بر اساس واکنش فوری کاربر تنظیم می شوند.
مدل های حساس به زمان: ترجیحات اخیر اغلب از مدل های قدیمی تر در دنیای فیلم بالاتر است.
نکته تخصصی: ارزیابی مداوم ابرقدرت شماست! A/B رویکردهای مختلف را تست ، نظارت بر معیارها و بازخورد کیفی کاربر را برای ساخت یک سیستم واقعاً استثنایی انجام دهید.

انتخاب چارچوب
الگوریتم مناسب قلب یک سیستم توصیه است که واقعاً کاربران شما را درک می کند. بیایید تفاوت های ظریف هر رویکرد را تحلیل کنیم ، چه موقع آنها را با هم ترکیب کنیم و تکنیک های پیشرفته ای را برای رسیدن به سیستم خود به سطح بعدی.
فیلتر مبتنی بر محتوا: قدرت "درست مثل این"
توصیه های هدفمند: این روش هنگامی که شما نیاز به مطابقت با موارد دلخواه شناخته شده کاربر را با فیلم هایی که ویژگی های اصلی مشابه آن را دارند - می درخشد - ژانر ، بازیگران ، کارگردان ، سبک بصری ، حتی عناصر یا مضامین خاص.
فراتر از آشکار: از تجزیه و تحلیل متن پیشرفته برای کشف اتصالات غیر منتظره استفاده کنید. شاید یک کاربر به طور مداوم از کمدی های تاریک لذت ببرد. به دنبال درام های عجیب و غریب باشید که همان طنز و شخصیت های پیچیده را به اشتراک می گذارند.
Code in Action: Countveectorizer Python توضیحات فیلم را به داده های عددی تبدیل می کند ، در حالی که شباهت کازین میزان هم ترازی فیلم ها را تعیین می کند. با وزن گیری TF-IDF آزمایش کنید یا برای نمایش های حتی غنی تر ، تعبیه های کلمه را کشف کنید.
سناریوهای ایده آل:
کاربران جدید بدون سابقه مشاهده گسترده.
یافتن فیلم های طاقچه در خارج از جریان اصلی.
هنگامی که توصیه های قابل توضیح ارزشمند هستند (می توانید نشان دهید که چرا یک فیلم پیشنهاد شده است).
فیلتر مشارکتی: توصیه هایی که از جامعه شما الهام گرفته شده است
استفاده از خرد جمعی: الگوهای موجود در کاربران را با سلیقه مشابه تجزیه و تحلیل می کند و به شما امکان می دهد آنچه را که دیگران مانند آنها از آن لذت بردند ، توصیه کنید. این مانند داشتن شبکه ای از تماشای فیلم های متخصص است که پیشنهادات شخصی را ارائه می دهند.
پویا و سازگار: این رویکرد به طور طبیعی با ترجیحات کاربر تکامل می یابد و توصیه ها را تازه و مرتبط نگه می دارد.
غلبه بر چالش ها:
شروع سرد: فیلتر کردن مبتنی بر محتوا ، شکاف کاربران یا فیلم های جدید را ایجاد می کند. همچنین می توانید کاربران را تشویق کنید تا ترجیحات اولیه را در حین ثبت نام ارائه دهند.
مقیاس پذیری: برای مجموعه داده های عظیم ، تکنیک های تخصصی مانند فاکتورسازی ماتریس یا الگوریتم های مبتنی بر نمودار عملکرد را بهینه می کنند.
مثال کد: K-Nearest همسایگان Python (KNN) "همسایگان" را با سلیقه مشابه مشخص می کنند ، در حالی که کتابخانه ها مانند تعجب الگوریتم های فیلتر مشترک مشترک را ارائه می دهند.
سیستم های ترکیبی: باز کردن تمام پتانسیل ها
همجوشی استراتژیک: یکپارچه این تکنیک ها را برای به حداکثر رساندن شخصی سازی و پتانسیل شگفتی های لذت بخش مخلوط کنید. این رویکرد تجربه کاربر را جلو و مرکز قرار می دهد.
پالایش تکراری: برای ارزش فوری ، حتی با داده های کاربر محدود ، با یک سیستم مبتنی بر محتوای قوی شروع کنید. به تدریج با رشد مجموعه داده های خود و منابع محاسباتی خود را در فیلتر مشترک قرار دهید.
معیارهایی که مهم هستند: نظارت کنید که چگونه توصیه ها با سلیقه های صریح کاربر (دقت) مطابقت دارد و در عین حال شگفتی های خوش آمدید (Serendipity و تنوع) را نیز معرفی می کند.
ملاحظات پیشرفته: پالایش ، سازگاری ، اکسل
فراتر از رتبه بندی های صریح: بازخورد ضمنی:
زمان و نرخ تکمیل را تماشا کنید
الگوهای جستجو و عناوین بیش از حد
نامزدی (بررسی ، سهام ، فهرست های نگهبان) - به ویژه برای محتوا بدون رتبه بندی گسترده ارزشمند است.
زمینه پادشاه است: توصیه های خیاط بر اساس:
زمان روز/هفته (سبکی در مقابل همهجانبه)
مکان (تأکید بر نسخه های جدید محلی)
استنباط روحیه (پیشنهادات خوش بین در مقابل کلاسیک های آرامش بخش)
Embrace Change: از یادگیری تقویت برای سیستمهایی که از طریق آزمایش و خطا بهبود می یابند استفاده کنید یا مدلهای آگاهانه ای را اجرا کنید که ترجیحات اخیر را به شدت وزن می کنند.
آگاهی از تعصب: مجموعه داده های خود را برای تعصبات احتمالی (محبوبیت ، نمایندگی جنسیت و غیره) ارزیابی کنید و استراتژی هایی را برای کاهش آنها برای یک پیشنهاد دهنده واقعاً فراگیر اجرا کنید.
نکته تخصصی: آزمایش مداوم مهم است! A/B رویکردهای مختلف را آزمایش کنید ، معیارهای متنوع را پیگیری کنید و به طور فعال به دنبال بازخورد کاربر برای ساختن یک سیستم استثنایی باشید که اعتماد و وفاداری را تقویت می کند.

تقسیم داده ها: آموزش ، آزمایش و اعتبار سنجی
تقسیم داده ها سلاح مخفی شما برای اطمینان از دقیق بودن و سازگاری با دنیای همیشه در حال تغییر ترجیحات فیلم است.
بیایید به ظرافت های این فرآیند و استراتژی هایی برای انتقال سیستم خود به سطح بعدی بپردازیم.
مرحله 1 - تنظیم: قدرت پایتون
داده های خود را بارگیری کنید: import pandas as pd و movies = pd.read_csv('movies.csv') .
به مجموعه داده های خود شیرجه بزنید: دستوراتی مانند movies.head(10) ، movies.info() و movies.describe() درک کاملی از مجموعه داده خود ارائه می دهید. به مقادیر مفقود شده ، دور افتاده ها ، ناسازگاری های احتمالی و تعادل کلی کلاس ها (ژانرها ، دوره های آزادی و غیره) توجه کنید. این بینش ها تصمیمات بعدی را راهنمایی می کنند.
تبدیل داده ها: داده های عددی را برای سازگاری با الگوریتم های یادگیری ماشین اطمینان حاصل کنید. زمینه های متن (توضیحات ، تحلیل ها) ممکن است تکنیک هایی مانند Countvectorizer یا TF-IDF را برای تبدیل آنها به قالب های قابل استفاده ضروری کند.
مرحله 2 - تقسیم و فتح: قلب قابلیت اطمینان
از بیش از حد جلوگیری کنید: مدلی که داده های آموزش را خیلی خوب می آموزد ، در مواجهه با کاربران یا فیلم های جدید مفید نخواهد بود. تقسیم الگوی شما را مجبور می کند تا الگوهای کلی را که به دنیای واقعی ترجمه می شود ، بیاموزد.
Gold Standard: یک مجموعه آزمایش دقیق و دقیق ، که در طول آموزش مشاهده نشده است ، قابل اطمینان ترین معیار شما در صحت توصیه در سناریوهای واقع گرایانه است.
تکرار و بهبود: مجموعه اعتبار سنجی زمین بازی شم است. آزمایش با الگوریتم ها ، تجزیه و تحلیل تأثیر ویژگی های مختلف و Hyperparameters با تنظیم دقیق برای بهترین عمل کرد. برای اطمینان از پیشرفت های موجود در داده های غیب ، هر بار دوباره ارزیابی کنید.
مرحله 3: کد در عمل
from sklearn.model_selection import train_test_split ابزار Go-to شم است. این عوامل را هنگام تصمیم گیری در مورد درصد در نظر بگیرید:
اندازه مجموعه داده ها: با مجموعه داده های عظیم ، مجموعه های آزمایش کوچکتر ممکن است کافی باشد.
پیچیدگی: مدل های پیچیده ممکن است از مجموعه اعتبار سنجی بزرگتر برای تنظیم بهینه بهره مند شوند.
مرحله 4: استراتژی های پیشرفته برای مشکلات پیچیده
نمونه گیری طبقه بندی شده: تعادل مجموعه داده اصلی خود را در هر تقسیم حفظ کنید. اگر قصد دارید توصیه های دقیقی را برای مقوله های حتی کمتر نماینده (ژانرهای طاقچه ، فیلم های کلاسیک و غیره) ارائه دهید ، این امر بسیار مهم است.
اعتبار سنجی متقاطع K: ایده آل برای مجموعه داده های محدود. این تضمین می کند که هر نقطه داده برای آموزش و اعتبار سنجی در چندین تکرار استفاده می شود و ارزیابی قوی تری از پتانسیل مدل شما ارائه می دهد.
تقسیم سری زمان: اگر تجزیه و تحلیل روندهای مشاهده در طول زمان (احتمالاً کاربران به تماشای انواع مختلفی از فیلم ها در آخر هفته در مقابل روزهای هفته) بسیار مهم هستند. این امر به جلوگیری از "پیش بینی" به طور تصادفی گذشته بر اساس داده های آینده کمک می کند ، که به کاربران شما خدمت نمی کند. .
معیارهای ارزیابی: دقت به تنهایی به اندازه کافی دقت ، فراخوان ، نمرات F1 یا حتی معیارهای خاص تجاری را در نظر نمی گیرد (آیا توصیه ای منجر به مشاهده کامل شد؟ تکرار مشتریان؟). اینها یک ارزیابی جامع از سیستم شما ارائه می دهند.
مرحله 5: حفظ ، تکرار و مقیاس
صرفه جویی در پیشرفت مدل خود: سریال سازی ( import pickle ) به شما امکان می دهد تا مدل را بعداً برای استقرار ، اضافه کردن داده های جدید یا ترکیب بازخورد بدون شروع از ابتدا بارگیری کنید.
آینده تغییر است: با سیستم خود به عنوان استاتیک رفتار نکنید. ارزیابی مجدد تقسیمات به طور دوره ای توصیه های شما را تازه نگه می دارد. این امر به ویژه با رشد پایه کاربر و تغییر روند فیلم صادق است.
نکته متخصص: تصمیمات تقسیم داده باید با اهداف سیستم شما هماهنگ باشد. با هدف توصیه های برتر 5 شخص بالا ، رویکرد متفاوتی از پیش بینی اینکه کاربر به طور گسترده ای از یک فیلم دوست داشته باشد یا دوست ندارد ، می طلبد. بگذارید این استراتژی شما را راهنمایی کند!

Walkthrough of the Python Code
ایجاد یک سیستم توصیه فیلم یک پروژه جذاب است که ترکیبی از دستکاری داده ها ، یادگیری ماشین و طراحی رابط کاربری است.
در این بخش ، شما را از طریق این فرایند گام به گام ، بر اساس هر آنچه که تاکنون آموخته اید راهنمایی می کنم. ما از اصول اولیه دستیابی به داده ها با پایتون شروع خواهیم کرد.
برای این پروژه ، ما از کتابخانه Pandas برای دستکاری و تجزیه و تحلیل داده ها استفاده خواهیم کرد. این کتابخانه برای برخورد با مجموعه داده های بزرگ به روشی انعطاف پذیر و شهودی ضروری است.
بیایید با تنظیم محیط خود و تهیه مجموعه داده خود شروع کنیم.
مرحله 1: محیط را تنظیم کنید
اول ، ما باید اطمینان حاصل کنیم که تمام ابزارها و کتابخانه های لازم را نصب کرده ایم. ما برای دستکاری داده ها به طور گسترده از پاندا استفاده خواهیم کرد. در اینجا نحوه شروع کار آورده شده است:
# Import the pandas library for data manipulation and analysis import pandas as pd # Install pandas library using pip (Python package installer) %pip install pandas # Note: The second import statement is redundant if you've already installed and imported pandas once. If that's the case, you can omit it.مرحله 2: مجموعه داده ها را وارد کنید
قبل از اینکه بتوانید مجموعه داده را وارد کنید ، مطمئن شوید که آن را از لینک ارائه شده در Kaggle بارگیری کرده اید: فیلم های TMDB دارای رتبه برتر - 10K Dataset . این مجموعه داده منبع غنی از اطلاعات در مورد فیلم ها است و به عنوان پایه و اساس سیستم توصیه ما خدمت می کند.
پس از تهیه مجموعه داده ، آن را در یک Pandas Dataframe بارگذاری کنید. با فرض اینکه مجموعه داده در یک پرونده CSV قرار دارد ، می توانید از کد زیر استفاده کنید:
# Load the dataset into a pandas DataFrame movies = pd.read_csv('path/to/your/downloaded/movies.csv') 'path/to/your/downloaded/movies.csv' را با مسیر فایل واقعی مجموعه داده بارگیری شده در سیستم خود جایگزین کنید.
مرحله 3: مجموعه داده ها را درک کنید
برای درک اطلاعاتی که با آنها کار می کنیم ، بیایید نام ستون ها را در DataFrame خود بازرسی کنیم. این به ما کمک می کند تا مشخص کنیم کدام ستون به سیستم توصیه ما مربوط می شود.
# Get the names of columns in the DataFrame print(movies.columns)مرحله 4: ویژگی های مربوطه را انتخاب کنید
برای سیستم توصیه فیلم ما ، ما روی چند ویژگی اصلی تمرکز خواهیم کرد: id ، title ، overview و genre . در اینجا به همین دلیل است که ما این ویژگی ها را انتخاب می کنیم:
شناسه : برای شناسایی منحصر به فرد هر فیلم در مجموعه داده های ما ضروری است.
عنوان : به کاربران امکان می دهد فیلم ها را با نام خود جستجو و شناسایی کنند.
نمای کلی : شرح مختصری از طرح فیلم را ارائه می دهد ، که برای درک محتوای و موضوع آن بسیار مهم است.
ژانر : به طبقه بندی فیلم ها در انواع مختلف کمک می کند و توصیه های مبتنی بر ژانر و شخصی سازی را فعال می کند.
با تمرکز روی این ویژگی ها ، می توانیم از محتوای روایت و اطلاعات ژانر فیلم ها برای یافتن شباهت ها و ارائه توصیه ها استفاده کنیم. بیایید این ستون ها را انتخاب کنیم و بقیه را رها کنیم:
# Select and retain only specified columns ('id', 'title', 'overview', 'genre') from the DataFrame movies = movies[['id', 'title', 'overview', 'genre']]این مرحله مجموعه داده های ما را ساده می کند و فقط اطلاعاتی را که برای ساختن سیستم توصیه خود نیاز داریم ، به ما می دهد.
مرحله 5: نمای کلی و ژانر را با هم ترکیب کنید
ترکیب ستون های "نمای کلی" و "ژانر" یک بردار ویژگی بین المللی تر ایجاد می کند ، و به طور قابل توجهی توانایی سیستم در توصیه فیلم هایی را که از نزدیک با ترجیحات کاربر مطابقت دارند ، بهبود می بخشد. این ترکیب به ما امکان می دهد تا از توضیحات متنی و دسته بندی های ژانر استفاده کنیم و مجموعه داده ها را با زمینه بیشتر برای هر فیلم غنی سازی کنیم.
# Add a new column 'tags' by concatenating 'overview' and 'genre' columns movies['tags'] = movies['overview'] + movies['genre']مرحله ششم: مجموعه داده ها را ساده کنید
اکنون که ما یک ستون "برچسب ها" تلفیقی داریم که جوهر محتوای و ژانر هر فیلم را ضبط می کند ، می توانیم با از بین بردن ستون های "نمای کلی" و "ژانر" که اکنون مجدداً مورد استفاده قرار می گیرد ، مجموعه داده های خود را بیشتر ساده کنیم. این ما را با یک مجموعه داده ساده متمرکز بر روی مفیدترین ویژگی ها برای سیستم توصیه ما قرار می دهد.
# Create a new DataFrame 'new_data' by dropping the 'overview' and 'genre' columns from 'movies' new_data = movies.drop(columns=['overview', 'genre'])مرحله 7: داده های متن را برای یادگیری ماشین آماده کنید
برای استفاده از الگوریتم های یادگیری ماشین برای سیستم توصیه خود ، باید داده های متنی خود را به یک فرمت عددی تبدیل کنیم.
اینجاست که CountVectorizer به بازی می رسد. این متن را در ستون "برچسب ها" ما به یک ماتریس پراکنده از شمارش نشانه ها تبدیل می کند ، و به طور مؤثر کلمات را به بردارها تبدیل می کند.
اما قبل از اینکه بتوانیم CountVectorizer استفاده کنیم ، تمیز کردن داده های متن برای بهبود کیفیت بردارهای ما بسیار مهم است. این به طور معمول شامل پایین آمدن متن ، از بین بردن نگارشی و استفاده از ساقه یا لیماتیزاسیون برای کاهش کلمات به شکل پایه یا ریشه آنها است.
در حالی که سریع ذکر می کند که دوباره یک تابع clean_text را به ستون "Tags" معرفی می کند ، به نظر می رسد که ما هنوز چنین عملکردی را تعریف نکرده ایم. با فرض اینکه ما تابعی برای تمیز کردن متن خود داریم ، به نظر می رسد چیزی شبیه به این:
# Assuming 'clean_text' is a function that cleans the text data new_data['tags_clean'] = new_data['tags'].apply(clean_text)بیایید با وکتور کردن داده های "برچسب های" تمیز خود ادامه دهیم:
# Import CountVectorizer from scikit-learn for text vectorization from sklearn.feature_extraction.text import CountVectorizer # Note: Ensure that scikit-learn is installed. If not, use pip to install it. # pip install scikit-learn # Initialize CountVectorizer cv = CountVectorizer(max_features=5000, stop_words='english') # Vectorize the cleaned 'tags' text vectorized_data = cv.fit_transform(new_data['tags_clean']).toarray() در این قطعه کد ، max_features=5000 تعداد ویژگی ها (یعنی کلمات متمایز) را به 5000 برتر محدود می کند ، که به مدیریت پیچیدگی محاسباتی کمک می کند. مشخص کردن stop_words='english' کلمات مشترک انگلیسی را حذف می کند که بعید است به منحصر به فرد بودن توضیحات فیلم کمک کنند.
مرحله 8: شباهت كسین را محاسبه كنید
با توضیحات فیلم ما به بردارهای عددی تبدیل شده است ، مرحله بحرانی بعدی محاسبه شباهت كسین بین این بردارها است.
این اندازه گیری به ما این امکان را می دهد تا تعیین کنیم که هر دو فیلم بر اساس محتوای آنها چقدر مشابه هستند. یک نمره شباهت در 1 به این معنی است که فیلم ها بسیار مشابه هستند ، در حالی که نمره 0 نشانگر شباهت نیست.
وارد کردن کتابخانه و محاسبه شباهت
# Import cosine_similarity from scikit-learn for computing similarity between vectors from sklearn.metrics.pairwise import cosine_similarity # Calculate the cosine similarity between vectors similarity = cosine_similarity(vectorized_data) در اینجا ، عملکرد cosine_similarity مجموعه ای از بردارها (برچسب های فیلم بردار ما) را به عنوان ورودی می گیرد و ماتریس نمرات شباهت را بین همه جفت فیلم ها برمی گرداند.
آزمایش با یک فیلم خاص
برای درک نحوه عملکرد سیستم توصیه ما در عمل ، بیایید عناوین فیلم هایی را که بیشتر شبیه به یک فیلم خاص در مجموعه داده های ما است ، پیدا و چاپ کنیم. ما از فیلم اول به عنوان نمونه استفاده خواهیم کرد:
# Calculate similarity scores for the third movie with all other movies, sort them, and store the result distance = sorted(list(enumerate(similarity[4])), reverse=True, key=lambda vector: vector[1]) # Print the titles of the first five movies most similar to the third movie for i in distance[0:5]: print(new_data.iloc[i[0]].title)یک عملکرد توصیه را تعریف کنید
برای اینکه سیستم ما کاربر پسند باشد ، منطق پیدا کردن فیلم های مشابه را در یک عملکرد قرار می دهیم. این عملکرد عنوان فیلم را به عنوان ورودی می گیرد و عناوین 5 فیلم برتر مشابه را چاپ می کند:
# Define a function to recommend the top 5 similar movies for a given movie title def recommend(movies): # Find the index of the given movie in the DataFrame index = new_data[new_data['title'] == movies].index[0] # Calculate similarity scores, sort them, and print titles of the top 5 similar movies distance = sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector: vector[1]) for i in distance[1:6]: # start from 1 to skip the movie itself print(new_data.iloc[i[0]].title) # Example usage recommend("Iron Man") توجه: مثال ارائه شده از "Iron Man" به عنوان یک مکان نگهدارنده استفاده می کند. آن را با یک عنوان واقعی فیلم از مجموعه داده خود جایگزین کنید تا عملکرد آن را آزمایش کنید.
مرحله 9: ماتریس DataFrame و شباهت را سریال کنید
برای صرفه جویی در پیشرفت ما و به راحتی به اشتراک گذاری یا به اشتراک گذاشتن سیستم توصیه خود ، ما مجموعه داده های تمیز شده و ماتریس شباهت را با استفاده از ماژول pickle سریال می کنیم:
import pickle # Serialize and save the 'new_data' DataFrame and 'similarity' matrix to files pickle.dump(new_data, open('movies_list.pkl', 'wb')) pickle.dump(similarity, open('similarity.pkl', 'wb')) # Fixed typo: should use 'wb' for writing # Optionally, deserialize to verify # movies_list = pickle.load(open('movies_list.pkl', 'rb')) # similarity_loaded = pickle.load(open('similarity.pkl', 'rb'))محیط را تأیید کنید
بالاخره ، برای درک اینکه پرونده های سریالی ما در کجا ذخیره می شوند ، یا اگر در محیطی کار می کنید که مسیر پرونده مهم باشد (مانند سرور یا سناریوی استقرار) ، می توانید فهرست کار فعلی را چاپ کنید:
import os # Print the current working directory print(os.getcwd())این نتیجه گیری راهنمای گام به گام در ساخت یک سیستم توصیه فیلم اساسی است. اکنون شما یک سیستم کاربردی دارید که می تواند فیلم ها را بر اساس شباهت در محتوا و ژانر توصیه کند ، با زیرساخت ها برای سریال سازی مدل خود برای استفاده یا استقرار در آینده.
در فصل بعد ، کد کامل پایتون را مشاهده خواهید کرد ، همه در کنار هم قرار می گیرند.

کد کامل Jupyternotebook
# Import the pandas library for data manipulation and analysis import pandas as pd # Install pandas library using pip (Python package installer) %pip install pandas # Import the pandas library again (this line is redundant and can be omitted) import pandas as pd # Load a dataset from a CSV file into a pandas DataFrame movies = pd.read_csv('dataset.csv') # Display the first 10 rows of the DataFrame movies.head(10) # Generate descriptive statistics of the DataFrame movies.describe() # Print a concise summary of the DataFrame (information about columns, data types, non-null values, etc.) movies.info() # Calculate the sum of null (missing) values for each column in the DataFrame movies.isnull().sum() # Get the names of columns in the DataFrame movies.columns # Select and retain only specified columns ('id', 'title', 'overview', 'genre') from the DataFrame movies = movies[['id', 'title', 'overview', 'genre']] # Add a new column 'tags' by concatenating 'overview' and 'genre' columns movies['tags'] = movies['overview'] + movies['genre'] # Create a new DataFrame 'new_data' by dropping the 'overview' and 'genre' columns from 'movies' new_data = movies.drop(columns=['overview', 'genre']) # Import necessary modules from the NLTK library for text processing import nltk import re from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer from nltk.tokenize import word_tokenize # Download NLTK resources for tokenization, lemmatization, and stopwords nltk.download('punkt') nltk.download('wordnet') nltk.download('stopwords') # Define a function for cleaning text data def clean_text(text): # Return an empty string if text is not a string if not isinstance(text, str): return "" # Convert text to lowercase text = text.lower() # Remove punctuation while retaining words and digits text = re.sub(r'[^\\w\\s\\d]', '', text) # Tokenize the text into words words = word_tokenize(text) # Define English stopwords stop_words = set(stopwords.words('english')) # Remove stopwords from the tokenized words words = [word for word in words if word not in stop_words] # Initialize the WordNet lemmatizer lemmatizer = WordNetLemmatizer() # Lemmatize each word words = [lemmatizer.lemmatize(word) for word in words] # Join the words back into a single string text = ' '.join(words) return text # Apply the clean_text function to the 'tags' column of 'new_data' and store the result in 'tags_clean' new_data['tags_clean'] = new_data['tags'].apply(clean_text) # Import CountVectorizer from scikit-learn for text vectorization from sklearn.feature_extraction.text import CountVectorizer # Install scikit-learn library using pip pip install scikit-learn # Reapply the clean_text function to the 'tags' column (this line seems redundant) new_data['tags_clean'] = new_data['tags'].apply(clean_text) # Import train_test_split from scikit-learn for splitting data into training and test sets from sklearn.model_selection import train_test_split # Import CountVectorizer again (redundant import) from sklearn.feature_extraction.text import CountVectorizer # Initialize a CountVectorizer object with a maximum of 10,000 features and English stop words cv = CountVectorizer(max_features=10000, stop_words='english') # Fit the CountVectorizer to the 'tags_clean' column and transform the text data into a numerical vector representation vector = cv.fit_transform(new_data['tags_clean'].values.astype('U')).toarray() # Check the shape of the resulting vector vector.shape # Import cosine_similarity from scikit-learn for computing similarity between vectors from sklearn.metrics.pairwise import cosine_similarity # Calculate the cosine similarity between vectors similarity = cosine_similarity(vector) # Print a concise summary of the 'new_data' DataFrame new_data.info() # Calculate similarity scores for the third movie with all other movies, sort them, and store the result distance = sorted(list(enumerate(similarity[2])), reverse=True, key=lambda vector: vector[1]) # Print the titles of the first five movies most similar to the third movie for i in distance[0:5]: print(new_data.iloc[i[0]].title) # Define a function to recommend the top 5 similar movies for a given movie title def recommend(movies): # Find the index of the given movie in the DataFrame index = new_data[new_data['title'] == movies].index[0] # Calculate similarity scores, sort them, and print titles of the top 5 similar movies distance = sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector: vector[1]) for i in distance[0:5]: print(new_data.iloc[i[0]].title) # Call the recommend function with "Iron Man" as the argument recommend("Iron Man") # Import the pickle module for serializing Python objects import pickle # Serialize the 'new_data' DataFrame and save it to a file pickle.dump(new_data, open('movies_list.pkl', 'wb')) pickle.dump(new_data, open('similarity.pkl', 'wb')) # Deserialize the 'movies_list.pkl' file back into a Python object pickle.load(open('movies_list.pkl', 'rb')) # Import the os module for interacting with the operating system import os # Print the current working directory print(os.getcwd()) 
چالش ها و راه حل ها در توصیه های مبتنی بر یادگیری ماشین
اجرای یادگیری ماشین در توصیه های فیلم ، چالش های متمایز مانند رسیدگی به داده های پراکنده را نشان می دهد ، که در صورت عدم وجود اطلاعات کافی در مورد کاربران یا فیلم ها رخ می دهد.
نمونه بارز این مسئله "شروع سرد" است ، جایی که کاربران یا فیلم های جدید اطلاعات تعامل کمی ندارند. بدون رتبه بندی کافی کاربر یا جزئیات فیلم ، تولید توصیه های دقیق دشوار است.
بیایید راهکارهایی را برای غلبه بر این موانع و ایجاد یک سیستم توصیه سازگار کشف کنیم.
استراتژی های توصیه های "شروع سرد"
محتوا پادشاه است (در ابتدا): تمرکز بر توضیحات دقیق ، برچسب های ژانر ، محبوبیت بازیگران/کارگردان یا حتی ویژگی های بصری مشتق شده (پالت های رنگی ، سبک سینمایی). اجازه دهید سیستم شما فیلم های مشابهی پیدا کند.
قدرت ابرداده: فراتر از شباهت سطح سطح نگاه کنید. آیا همان شرکت تولیدی بازدیدهای مشابهی را منتشر کرد؟ آیا کارگردان به دلیل روحیه خاص یا سبک فیلم سازی شناخته شده است؟
حالت "اکتشاف": بخش کوچکی از توصیه ها را به مواردی با نمرات محبوبیت پایین تر یا حداقل داده های کاربر اختصاص دهید. تزریق برخی از تصادفی محاسبه شده باعث کشف می شود و به مبارزه با اثر "اتاق اکو" کمک می کند.
شفافیت را در آغوش بگیرید: هنگامی که توصیه ها بر اساس داده های محدود بنا شده است به کاربران ارتباط دهید ("ما هنوز هم طعم شما را یاد می گیریم ، اما ممکن است شما بر اساس بازیگران آن لذت ببرید ..."). این باعث ایجاد اعتماد می شود و نامزدی را دعوت می کند.
بهینه سازی و تکامل: بازخورد و آزمایش کاربر مهار
ترکیب نظرات شما به طور مستقیم در توسعه و پالایش سیستم توصیه فیلم شما می تواند به طور قابل توجهی اثربخشی و رضایت شما را تقویت کند.
با ادغام مکانیسم ها برای جمع آوری پاسخ ها و ترجیحات خود ، نیازهای شما دقیق تر برطرف می شود و منجر به توصیه های دقیق تر و مورد استقبال فیلم می شود.
در اینجا به همین دلیل استفاده از بازخورد شما برای افزایش صحت سیستم توصیه فیلم شما بسیار مهم است:
بازخورد مین طلای شماست
بازخورد ارتباط فوری : ویژگی هایی مانند "آیا از این فیلم لذت بردی؟" دکمه ها یا گزینه هایی برای ارزیابی توصیه ها به سیستم اجازه می دهد تا پیشنهادات آینده خود را در زمان واقعی تنظیم کند و باعث می شود آنها با ترجیحات شما هماهنگ تر شوند.
بینش عمیق از طریق نظرسنجی ها : نظرسنجی های کوتاه اختیاری پس از تماشای یک فیلم می تواند بینشی در مورد جنبه های خاص شما دوست داشته یا دوست نداشته باشید (به عنوان مثال پیچیدگی نقشه ، توسعه شخصیت ، ترجیحات ژانر). از این بازخورد دقیق می توان برای تنظیم دقیق الگوریتم های توصیه استفاده کرد.
ردیابی فهرست تماشای : دیدن کدام فیلم هایی که به فهرست های تماشای خود اضافه می کنید یا آنچه را که بعد از توصیه مشاهده می کنید ، بازخورد ضمنی در مورد ترجیحات شما ارائه می دهد ، و به تهیه دقیق تر پیشنهادات آینده کمک می کند.
آزمون A/B برای پیروزی
تعادل در مورد توصیه های اکتشافی SAFE در مقابل : آزمایش A/B استراتژی های مختلف به یافتن تعادل کامل بین توصیه هایی که با ترجیحات شناخته شده شما (انتخاب های "ایمن" از نزدیک) و معرفی شما به محتوای جدید برای گسترش افق خود (انتخاب های اکتشافی) کمک می کند ، کمک می کند. نظارت بر معیارهای نامزدی مانند کلیک ، زمان تماشای و رتبه بندی به سیستم اجازه می دهد تا مشخص کند کدام رویکرد شما را در دراز مدت درگیر و راضی می کند.
از کلاسیک غافل نشوید
دامنه توصیه های فراگیر : یک خطای رایج در سیستم های توصیه بیش از حد روی نسخه های جدید متمرکز است ، که به طور بالقوه در کلاسیک ها یا سنگهای قدیمی تر از دست نمی رود که ممکن است کاملاً مناسب طعم شما باشد. این سیستم با وارد کردن سال انتشار در الگوریتم ها یا صرفه جویی در اسلات های خاص برای فیلم های کلاسیک در ژانرهای مختلف ، این سیستم می تواند شما را با طیف وسیع تری از فیلم هایی که ممکن است دوست داشته باشید آشنا کنید اما هنوز کشف نکرده اید.
ادغام بازخورد شما در یک سیستم توصیه فیلم نه تنها صحت و ارتباط پیشنهادات ارائه شده را بهینه می کند بلکه یک محیط یادگیری پویا را برای سیستم ایجاد می کند. این تضمین می کند که توصیه ها با ترجیحات در حال تغییر شما تکامل می یابد و منجر به یک تجربه جذاب تر و رضایت بخش تر برای شما می شود.
این استراتژی شما را ، بیننده منفعل ، به یک شرکت کننده فعال در فرآیند درمان تبدیل می کند ، و به طور قابل توجهی اثربخشی کلی سیستم را افزایش می دهد.
بینش Expert: بهترین سیستم ها به طور پیشگیرانه به داده های پراکنده می پردازند. به طور مداوم منابع داده را مجدداً ارزیابی کنید ، به دنبال راه های خلاقانه برای جمع آوری برخی از ترجیحات اولیه کاربر باشید و هرگز فرض نکنید که کار شما انجام شده است.

محدودیت ها و زمینه هایی برای بهبود آینده
در حالی که رویکردی که برای ساختن یک سیستم توصیه ای جامع فیلم بیان شده است قوی و ابتکاری است ، تأیید محدودیت های ذاتی به دلیل محدودیت های داده و اعتماد به داده های TMDB (پایگاه داده فیلم) مهم است.
در اینجا توضیحی واضح تر از این محدودیت ها و تأثیر بالقوه آنها در سیستم توصیه ارائه شده است:
محدودیت های مجموعه داده
ستون ها و عمق محدود : مجموعه داده اصلی ما ، که از TMDB تهیه شده است ، ممکن است وسعت یا عمق ابرداده مورد نیاز برای توصیه های ظریف تر را نداشته باشد. به عنوان مثال ، ممکن است جزئیات اساسی مانند ژانر ، تاریخ انتشار و بازیگران را ارائه دهد اما فاقد محتوای غنی تر مانند تحلیل دقیق کاربر ، زیر مجموعه های خاص یا برچسب های موضوعی است که می تواند باعث افزایش شخصی شود.
مجموعه داده های استاتیک : عکس فوری داده از TMDB یک لحظه خاص در زمان را نشان می دهد. با انتشار فیلم های جدید و تغییر روندهای فرهنگی ، مجموعه داده ها خطرات منسوخ می شوند ، و به طور بالقوه توصیه های کم نظیر نسبت به محتوای قدیمی تر یا کمتر مرتبط و بدون به روزرسانی منظم.
اعتماد به TMDB
کامل بودن و صحت داده ها : در حالی که TMDB یک منبع ارزشمند است ، کامل بودن و صحت داده های آن به مشارکت کاربر بستگی دارد و می تواند متفاوت باشد. این تنوع ممکن است بر قابلیت اطمینان توصیه ها بر اساس این داده ها تأثیر بگذارد ، به خصوص برای فیلم های کمتر محبوب یا جدیدتر.
حلقه بازخورد کاربر محدود : TMDB پایه و اساس کاملی برای درک فیلم ها در دسترس و ویژگی های اساسی آنها فراهم می کند. اما ممکن است طیف کاملی از تعامل و بازخورد کاربر ، مانند تجزیه و تحلیل احساسات ظریف یا الگوهای مشاهده خاص ، که برای پالایش الگوریتم های توصیه بسیار مهم هستند ، ضبط نکند.
استراتژی هایی برای کاهش محدودیت ها
غنی سازی داده ها از منابع متنوع : جبران محدودیت های مجموعه داده TMDB ، شامل منابع داده اضافی بسیار مهم است. جمع آوری رتبه ها و تحلیل از سیستم عامل هایی مانند Kaggle یا Movielens ، بحث های معدن از Reddit یا LetterboxD ، و از جمله داده های جوایز می تواند مجموعه داده را غنی تر کند و نمای گردتری از فیلم ها و ترجیحات بیننده ارائه دهد.
متن پیشرفته و تجزیه و تحلیل بصری : استفاده از تکنیک های پیشرفته NLP برای تجزیه و تحلیل متن عمیق تر و کاوش نشانه های بصری از پوسترهای فیلم یا تریلرها می تواند لایه هایی از درک را فراتر از ابرداده اساسی اضافه کند و به کشف ارتباطات نهفته بین فیلم ها و ترجیحات بیننده کمک می کند.
به روزرسانی های الگوریتم پویا : به طور مرتب به روزرسانی الگوریتم های توصیه برای ادغام منابع جدید داده ها ، بازخورد کاربر و روندهای در حال تحول باعث می شود سیستم با گذشت زمان مرتبط و مؤثر باشد. این شامل پالایش مدلهای فیلتر مشارکتی برای پرداختن به کمبود داده ها و توسعه مدلهای متنی است که منعکس کننده زمینه ها و خلق و خوی های فعلی است.
شناخت محدودیت های تکیه در درجه اول به داده های TMDB و دامنه مجموعه داده فعلی بر اهمیت تلاش های مداوم برای غنی سازی و به روزرسانی مجموعه داده ها و الگوریتم ها تأکید می کند.
با تأیید این چالش ها و به طور فعال به دنبال کاهش آنها از طریق منابع استراتژیک ، تجزیه و تحلیل پیشرفته و تکامل الگوریتم ، سیستم توصیه می تواند به پیشرفت خود ادامه دهد و پیشنهادات فیلم دقیق تر ، شخصی و به موقع را به کاربران ارائه می دهد.
از خواندن شما متشکرم!
همانطور که ما این آموزش را می بندیم ، قدردانی خود را برای وقت شما تمدید می کنم. این سفر سالهای تقطیر دانش حرفه ای و دانشگاهی به این کتابچه راهنما یک تلاش برآورده شده است.
متشکرم که در این تعقیب به من پیوستید ، و من مشتاقانه پیش بینی می کنم شاهد رشد شما در حوزه فناوری باشید.
منابع
اگر علاقه مند به تسلط بر ساختارهای داده هستید ، ساختار داده های Lunartech.ai را به عنوان Mastery Bootcamp تحلیل کنید. این برای کسانی که علاقه مند به AI و Learning Machine هستند ، با تمرکز بر استفاده مؤثر از ساختارهای داده در برنامه نویسی مناسب است.
این برنامه جامع ساختار داده های ضروری ، الگوریتم ها و برنامه نویسی پایتون را در بر می گیرد و شامل مربیگری و پشتیبانی شغلی است.
علاوه بر این ، برای تمرین بیشتر در ساختار داده ها ، این منابع را در وب سایت ما کاوش کنید:
Java Data Structures Mastery - ACE مصاحبه برنامه نویسی : یک کتاب الکترونیکی رایگان برای پیشرفت مهارت های جاوا ، با تمرکز بر ساختارهای داده برای افزایش مصاحبه و مهارت های حرفه ای.
مبانی ساختار داده های جاوا - کاتالیزور برنامه نویسی شما : یک کتاب الکترونیکی رایگان دیگر ، غواصی به Essentials Java ، برنامه نویسی شی گرا و برنامه های هوش مصنوعی.
برای این منابع و اطلاعات بیشتر در مورد Bootcamp به وب سایت ما مراجعه کنید.
درباره نویسنده
Vahe aslanyan در اینجا ، در Nexus علوم کامپیوتر ، علوم داده و هوش مصنوعی. برای دیدن نمونه کارها که گواهی بر دقت و پیشرفت است ، بهVaheaslanyan.com مراجعه کنید. تجربه من شکاف بین توسعه تمام پشته و بهینه سازی محصول هوش مصنوعی را ایجاد می کند که با حل مشکلات به روش های جدید هدایت می شود.
با سابقه ای که شامل راه اندازی یک Bootcamp پیشرو در علوم داده و کار با صنعت متخصصان برتر است ، تمرکز من روی ارتقاء آموزش فنی به استانداردهای جهانی است.
با من ارتباط برقرار کنید:
برای یک تن منابع رایگان در CS ، ML و AI در LinkedIn دنبال کنید
Subscribe to my The Data Science and AI Newsletter
برچسبها
|
|

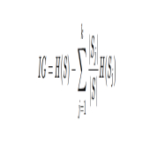


ارسال نظر