چگونه مقیاس خودکار و تعادل بار در معماری نرم افزار کار می کند
در حالی که مقیاس خودکار و تعادل بار دو تکنیک مجزا در مدیریت معماری نرم افزار هستند، اغلب به طور همزمان اجرا می شوند. در معماری نرم افزاری، یکی به ندرت بدون دیگری وجود دارد، زیرا آنها مکمل یکدیگر هستند تا تغییرات غیرقابل پیش بینی در تقاضا را مدیریت کنند.
این مقاله توضیح میدهد که مقیاس خودکار و تعادل بار چگونه کار میکنند و چرا باید آنها را در طراحیهای خود در نظر بگیرید. همچنین معماریهای نمونهای را تحلیل میکند که مقیاس خودکار و متعادلسازی بار را در عمل نشان میدهند.
فهرست مطالب
مقیاس خودکار توضیح داده شده است
چرا از Auto Scaling استفاده کنید
مقیاس خودکار توضیح داده شده است
مقیاس خودکار، همانطور که از نام آن پیداست، به سادگی راهی برای مقیاس خودکار نمونه های محاسباتی شما است. با اکثر ارائه دهندگان ابری مانند AWS، GCP و Azure، سیاست های مقیاس بندی را انتخاب می کنید که نحوه گفت ن یا حذف نمونه ها را مشخص می کند.
خطمشیهای مقیاسبندی صرفاً قوانینی هستند که میگویند بر اساس معیارهای از پیش تعریفشده، چقدر باید تعداد نمونهها را افزایش یا کاهش دهید.
سیاست های مقیاس بندی می توانند پویا باشند، برای مثال، با گفت ن نمونه های جدید بر اساس استفاده از CPU از نمونه های موجود. خطمشیهای مقیاسبندی همچنین میتوانند بر اساس یک زمانبندی باشد، که بر اساس زمانهای خاصی از روز یا هفته است که تقاضای بالاتر یا کمتری را پیشبینی میکنید.
مقیاس بندی پویا
مقیاس بندی پویا برای زمانی که نوسانات زیادی در تقاضا در زمان های نامعلوم و غیرقابل پیش بینی وجود دارد ایده آل است. شما می دانید که ممکن است یک افزایش ناگهانی یا کاهش تقاضا در نمونه های شما وجود داشته باشد، فقط نمی دانید چه زمانی.
با استفاده از تشبیه رستوران، به مثالی فکر کنید که یک سرآشپز کار تبدیل سفارشات به غذا را انجام می دهد. اگر فقط سه سرآشپز دارید و در طول روز یا هفته نوسانات زیادی در تقاضا ندارید، جای نگرانی نیست.
اما اگر رستوران شما فروش بیشتری داشت که بیش از پیش بینی شده بود، یا یک مهمانی بزرگ از گردشگران به طور ناگهانی وارد رستوران شدند، چگونه با آن کنار می آمدید؟ اگر بتوانید سرآشپزهای بیشتری را فوراً در صورت نیاز اضافه کنید چه؟
مقیاس خودکار پویا اینگونه عمل می کند. مقیاسبندی پویا باعث میشود سرآشپزها بهطور خودجوش در آشپزخانه ظاهر شوند، آماده تبدیل سفارشها به وعدههای غذایی خوشمزه، بر اساس معیار از پیش تعریفشدهای که میتوانید برای اندازهگیری میزان کار بیش از حد سرآشپزها انتخاب کنید – یعنی چقدر برای انجام سفارشهای فعلی تلاش میکنند.
به یاد داشته باشید که این سیاست های مقیاس بندی صرفاً قوانین هستند. این قوانین می توانند بسیار ساده باشند، مانند:
اگر استفاده از CPU بیش از 50٪ باشد، یک نمونه دیگر اضافه کنید. اگر استفاده از CPU کمتر از 50٪ باشد، یک نمونه را حذف کنید.
این قوانین همچنین می توانند پیچیده تر باشند.
برای مثال، با AWS و GCP، میتوانید یک معیار ردیابی هدف را تنظیم کنید که عملکرد CPU گروه مقیاسبندی شما را نظارت میکند و نمونههایی را اضافه یا حذف میکند تا میانگین استفاده از CPU تقریباً با تنظیمات دلخواه شما مطابقت داشته باشد.
برای مثال، اگر مشخص کنید که میخواهید میانگین استفاده از CPU در گروه مقیاسبندی شما 60 درصد باشد، نمونههایی در صورت لزوم اضافه یا حذف میشوند تا تقریباً به آن هدف برسند.
استفاده از CPU برای راهاندازی یک اقدام مقیاسپذیری یکی از محبوبترین الگوها است. اما استفاده از CPU تنها معیاری نیست که می توانید برای مقیاس بندی استفاده کنید. از برخی جهات، استفاده از استفاده از CPU در واقع می تواند غیربهینه باشد، به خصوص اگر می خواهید مقیاس پذیری بیشتری داشته باشید.
اگر بتوانید معیار دیگری را ردیابی کنید که افزایش استفاده از CPU را پیشبینی میکند، پس لازم نیست قبل از شروع یک اقدام مقیاسپذیری منتظر افزایش اجتنابناپذیر استفاده از CPU نمونههای خود باشید؟
به عنوان مثال، با GCP، اگر یک متعادل کننده بار HTTP در جلوی نمونه های خود دارید، می توانید مقیاس خود را به گونه ای پیکربندی کنید که بر اساس تعداد درخواست هایی که به متعادل کننده بار شما وارد می شود، راه اندازی شود. به طور مشابه با AWS، اگر یک صف SQS در جلوی نمونه های خود دارید، می توانید بر اساس تعداد پیام های موجود در صف مقیاس بندی کنید.
در هر دوی این مثالها، چیز دیگری افزایش احتمالی استفاده از CPU در آینده را پیشبینی میکند، پس تنظیم یک اقدام مقیاسپذیری که بر اساس آن راهاندازی شود، راهی برای ایجاد مقیاسپذیری پاسخگوتر است.
برای بازگرداندن قیاس رستوران ما، این مانند این است که وقتی یک صف بزرگ در خارج از رستوران دیدید، سرآشپزهای بیشتری را به آشپزخانه دعوت کنید. این روشی پاسخگوتر برای مقابله با افزایش ناگهانی تقاضا در مقایسه با انتظار تا زمانی که سرآشپزهای شما غرق سفارش شوند، است.
مقیاس بندی برنامه ریزی شده
مقیاس بندی برنامه ریزی شده برای زمانی که نوسانات زیادی در تقاضا در زمان های مشخص وجود دارد ایده آل است.
با استفاده مجدد از قیاس رستوران، خط مشی مقیاس بندی شما می تواند بر اساس یک برنامه زمان بندی باشد. پس ، برای مثال، اگر میدانید عصرها و آخر هفتهها شلوغتر از صبحها و روزهای هفته هستند، خطمشی مقیاسبندی شما تضمین میکند که سرآشپزهای بیشتری در دورههایی با تقاضای بالاتر وجود دارد.
با AWS و GCP، میتوانید یک خطمشی مقیاسبندی زمانبندی شده برای گفت ن یا حذف نمونهها در زمانهای خاص تنظیم کنید.
چرا از مقیاس خودکار استفاده کنیم؟
مقیاس خودکار مشکل قدیمی برنامه ریزی ظرفیت را حل می کند. تلاش برای پیشبینی دقیق اینکه چقدر محاسبات در آینده مورد نیاز خواهد بود، مملو از خطا است. ظرفیت خیلی کم است و وب سایت شما در دوره های پر تقاضا از کار می افتد و برای شما هزینه و شهرت دارد. ظرفیت بسیار زیاد است و شما برای نمونه های استفاده نشده هزینه می کنید.
برنامه ریزی ظرفیت اساساً یک مشکل پیش بینی است. و انسان ها در پیش بینی دقیق آینده عالی نیستند. قبل از اینکه ارائه دهندگان ابری مانند AWS، GCP و Azure وجود داشته باشند، شرکت ها باید ظرفیت خود را بر اساس تقاضای مورد انتظار آینده برنامه ریزی می کردند. این فرآیند برنامه ریزی اغلب فقط حدس و گمان پنهان بود. شما مجبور بودید برای سرورها هزینه اولیه پرداخت کنید و امیدوار باشید که به میزان قابل توجهی تعداد سرورهای مورد نیاز خود را کمتر یا بیش از حد تخمین زده باشید.
مشکل پیشبینی به این دلیل به وجود میآید که ما ایمان اشتباهی به اندازهگیری دقیق آینده نامعلوم داریم. انسان ها برای مدت طولانی پیش بینی های نادرست می کنند. تا سال 600 قبل از میلاد، فیلسوف یونانی تالس آنقدر به شمردن ستارگان علاقه داشت که مدام در چاله های جاده می افتاد.
برخی چیزها اساساً ناشناخته هستند، و این اشکالی ندارد. مقیاسبندی خودکار نیاز به پیشبینی دقیق تقاضای آینده را از بین میبرد زیرا میتوانید بهطور خودکار تعداد نمونههایی را که بر اساس خطمشی مقیاسبندی خود دارید، افزایش یا کاهش دهید.
با استفاده از مقیاس خودکار، می توانید انعطاف پذیری معماری خود را بهبود بخشیده و هزینه ها را کاهش دهید. این دو دلیل اصلی برای استفاده از مقیاس خودکار در طراحی های خود هستند.
تاب آوری را بهبود بخشید
امکان افزایش خودکار و فوری تعداد نمونهها در پاسخ به تقاضای رو به رشد، احتمال اینکه نمونههای شما تحت بار بیش از حد و در معرض خطر عملکرد ضعیف قرار بگیرند را کاهش میدهد. این انعطاف پذیری معماری شما را بهبود می بخشد.
با این حال، مقیاس خودکار فقط در مورد مقیاس بندی نیست. همچنین می توان از آن برای حفظ تعداد مجموعه ای از نمونه ها استفاده کرد. این یک راه عالی برای ایجاد معماری های خود درمانی است.
با AWS، میتوانید حداقل، حداکثر و تعداد مورد نظر خود را از نمونههای محاسباتی، بدون هیچ گونه سیاست مقیاسبندی تنظیم کنید. AWS به سادگی تلاش می کند تا تعداد مورد نظر از نمونه های مشخص شده توسط شما را حفظ کند. پس اگر حداقل، حداکثر و مطلوب همه را برابر یک قرار دهید، AWS یک نمونه را برای شما حفظ می کند. اگر این نمونه ناموفق باشد، نمونه دیگری به طور خودکار برای جایگزینی نمونه ناموفق ایجاد می شود تا ظرفیت مورد نظر شما بازیابی شود.
این یک راه ارزان و آسان برای اطمینان از در دسترس بودن بالا بدون داشتن نمونه های متعدد در مناطق مختلف در دسترس است.
توانایی ایجاد معماری های خود درمانی یک استدلال واقعا قوی برای تقریبا همیشه قرار دادن نمونه های شما در یک گروه مقیاس خودکار است. AWS و GCP از زمان نوشتن این مقاله، امتیاز استفاده از مقیاس خودکار را از شما دریافت نمی کنند. شما فقط برای زیرساخت زیربنایی که برای پشتیبانی از نمونه های شما ایجاد شده است، پرداخت می کنید.
پس ، حتی اگر نیازی به مقیاسبندی نمونهها بر اساس تقاضای آنها وجود نداشته باشد، داشتن نمونهها در یک گروه مقیاسبندی خودکار یک راه ارزان و آسان برای ایجاد یک معماری خود درمانی است.
کاهش هزینه
نمونه های قبلی در مورد افزایش تعداد نمونه ها برای پاسخگویی به تقاضای بالاتر بود. اما به همان اندازه مهم توانایی کاهش مقیاس در دورههای تقاضای کمتر است.
مقیاس خودکار به شما امکان می دهد این کار را با استفاده از سیاست های مقیاس بندی زمان بندی شده یا پویا انجام دهید. این یک راه عالی برای اطمینان از این است که شما برای بیش از آنچه نیاز دارید پرداخت نمی کنید.
تعادل بار توضیح داده شده است
متعادل کننده بار اتصالات مشتریان را می پذیرد و درخواست ها را در بین نمونه های هدف توزیع می کند. توزیع درخواست ها معمولاً روی لایه 7 (لایه کاربردی) یا لایه 4 (لایه حمل و نقل) انجام می شود. این لایه ها یک مدل نظری هستند که شبکه های کامپیوتری را در 7 لایه سازماندهی می کند وبه مدل OSI معروف است.
من در اینجا به جزئیات زیاد مدل OSI نمی پردازم، اما در حال حاضر، آنچه مهم است بدانید این است که اکثر بار متعادل کننده ها می توانند روی لایه کاربردی یا لایه انتقال کار کنند. این بدان معناست که آنها با پروتکل های لایه 7 مانند HTTP(S) یا پروتکل های لایه 4 مانند TCP، UDP، SMTP، SSH کار می کنند.
مثالی که در این بخش ارائه میشود، تنها به لایههای ۷ متعادلکننده بار برنامههای محبوبتر که با HTTP/HTTPS کار میکنند، میپردازد.
در حالی که جزئیات پیاده سازی سطح پایین و موارد استفاده بین بار متعادل کننده های لایه 7 و لایه 4 متفاوت است، اصول یکسان باقی می مانند. متعادل کننده بار برای توزیع ترافیک ورودی در تعدادی از نمونه های هدف استفاده می شود
توزیع درخواستها در بین نمونههای هدف معمولاً از یک الگوریتم دور روبین استفاده میکند که در آن درخواستها به صورت متوالی برای هر نمونه ارسال میشوند. پس ، درخواست شماره 1 به نمونه شماره 1 می رود، درخواست شماره 2 به نمونه شماره 2، درخواست شماره 3 به نمونه شماره 3، درخواست شماره 4 مجدداً به نمونه شماره 1 می آید و غیره.
در حالی که سایر الگوریتمهای متعادلسازی وجود دارد، الگوریتم گرد رابین محبوبترین الگوریتمی است که توسط اکثر ارائهدهندگان ابر برای متعادلسازی بار استفاده میشود.

نمودار بالا یک تصویر منطقی از نحوه کار متعادل کننده بار است. فقط یک بار متعادل کننده را نشان می دهد که طراحی چندان انعطاف پذیری نیست. این انتزاع منطقی به راحتی قابل توضیح است، اما دقیق نیست.
در پشت صحنه، چندین گره متعادل کننده بار در هر زیر شبکه در یک منطقه در دسترس مستقر می شوند. متعادل کننده بار با یک رکورد DNS ایجاد می شود که به تمام گره های متعادل کننده بار الاستیک ایجاد شده اشاره می کند - یعنی این رکورد DNS واحد در تمام آدرس های IP گره های واقعی مستقر شده است. همه درخواست های دریافتی به طور مساوی در تمام گره های متعادل کننده بار توزیع می شوند و گره های متعادل کننده بار به نوبه خود درخواست ها را به طور مساوی بین نمونه های هدف توزیع می کنند. به این ترتیب شما حتی یک نقطه شکست نخواهید داشت.
نمایش واقعی تر، هرچند پیچیده تر، از نحوه عملکرد متعادل کننده های بار در زیر نشان داده شده است. در این مثال، درخواستها به هر یک از گرههای متعادلکننده بار که در سه زیرشبکه مستقر شدهاند میآیند و سپس به طور مساوی در بین نمونههای هدف توزیع میشوند.
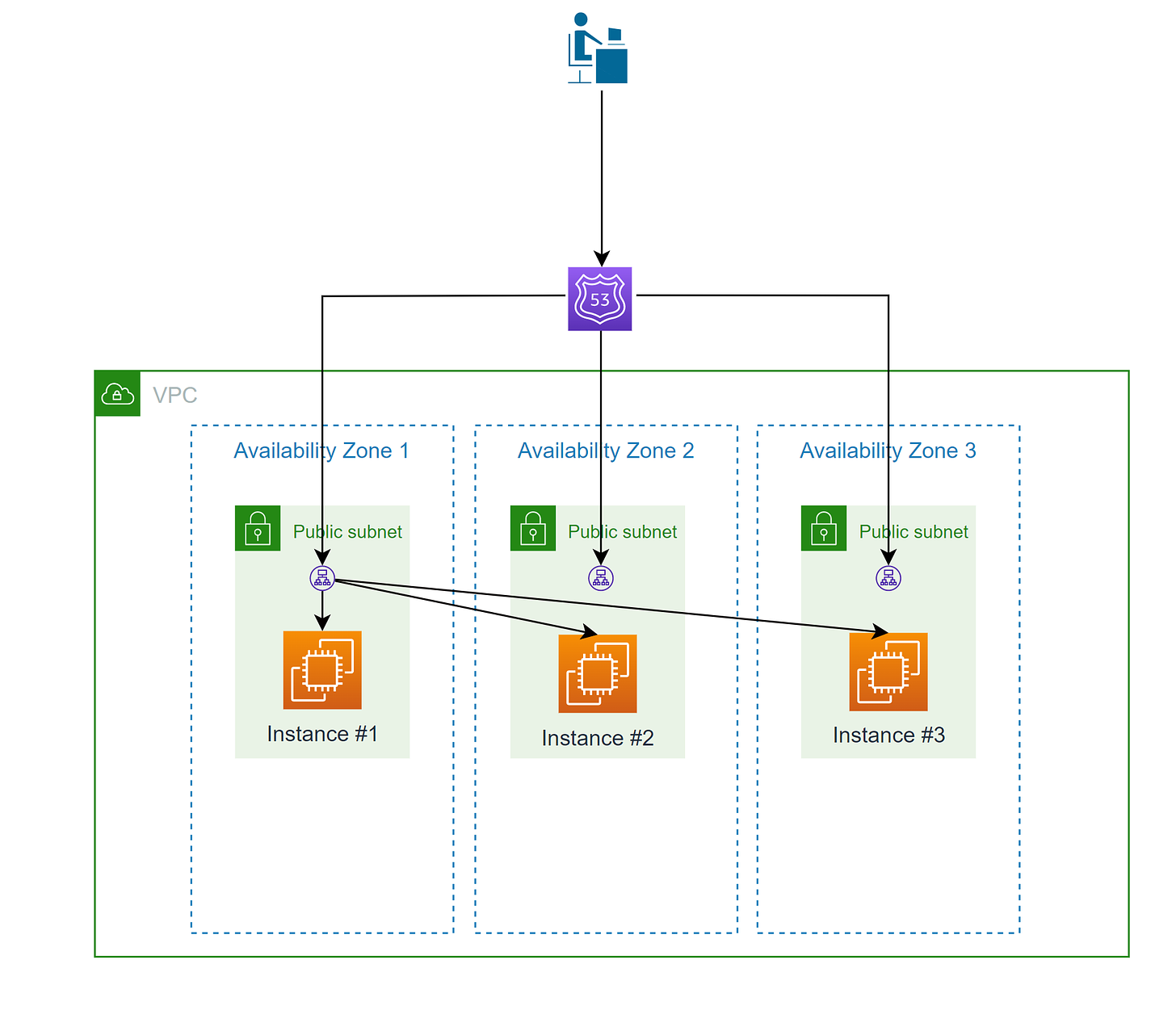
چرا از Load Balancing استفاده کنیم؟
متعادل کننده بار اطمینان حاصل می کند که ترافیک بین نمونه های هدف توزیع شده است. این باعث پخش شدن بار می شود و از بارگیری بیش از حد یک نمونه با تعداد بیش از حد درخواست جلوگیری می کند.
متعادل کننده بار نیز یک معماری سست کوپل شده ایجاد می کند. اتصال شل معمولاً به این دلیل است که باعث می شود کاربران مجبور نباشند از نمونه ها آگاه باشند یا نمونه ها نیازی به آگاهی از نمونه های دیگر نداشته باشند.
«آگاه بودن» دقیقاً به چه معناست؟ از آنجایی که درخواستهای کاربر ابتدا به بار متعادل کننده ارسال میشوند، کاربران از نمونههایی که واقعاً به درخواست آنها پاسخ میدهند آگاه نیستند. تمام ارتباطات از طریق متعادل کننده بار انجام می شود، پس تغییر نوع و تعداد نمونه ها بدون اینکه کاربر از آن آگاه باشد آسان می شود. متعادل کننده بار از نمونه های موجود در هدف خود آگاه است پس می تواند درخواست را به تمام موارد مربوطه ارسال کند.
گردآوری آن - تعادل بار و مقیاس خودکار در عمل
نمودار زیر تعادل بار و مقیاس خودکار را نشان می دهد که برای یک برنامه وب سه سطحی متشکل از سطوح وب، برنامه و پایگاه داده استفاده می شود. هر یک از این سطوح دارای نمونه / زیرساخت جداگانه هستند.
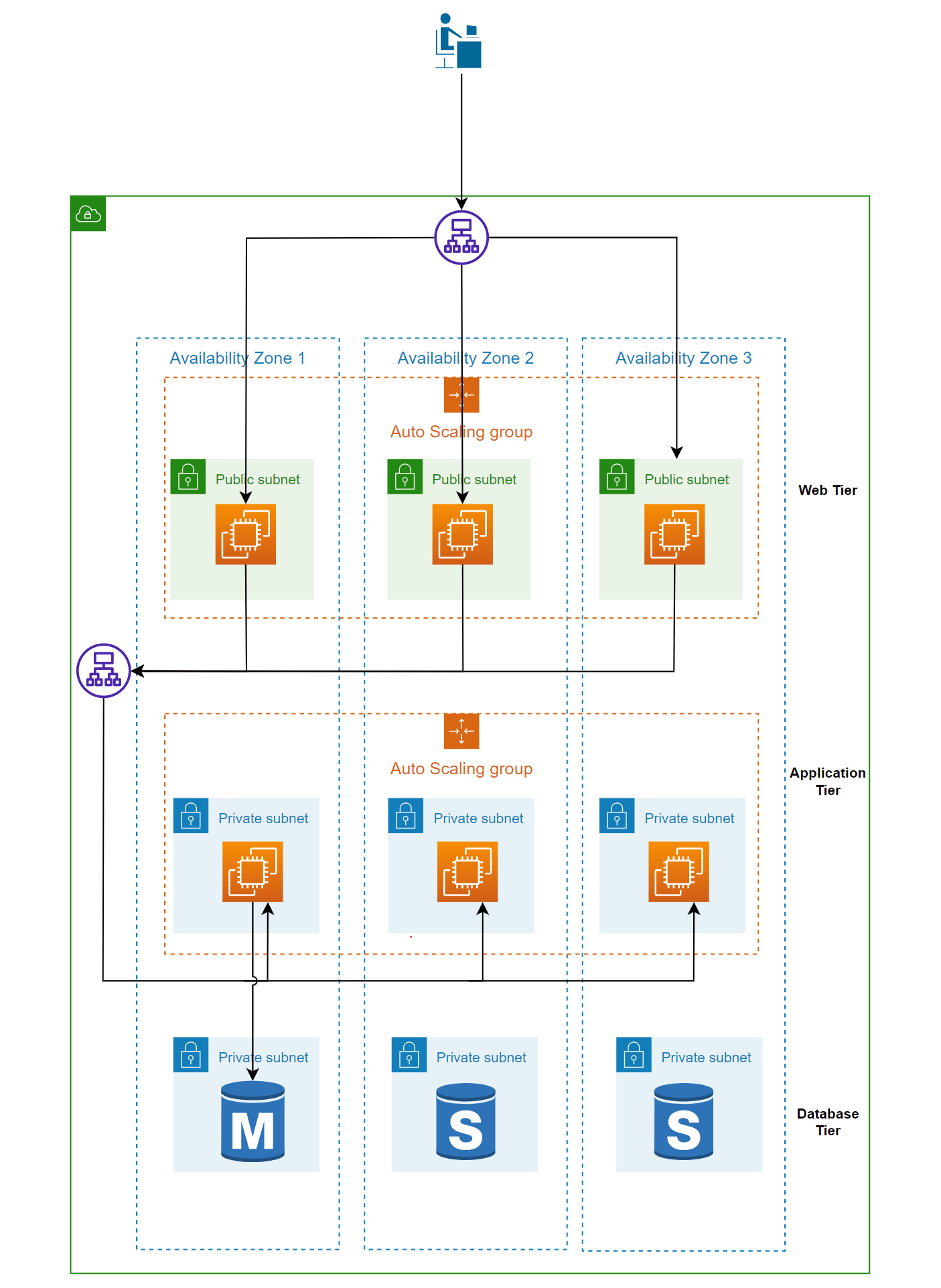
نمونه ها در سطوح وب و برنامه در گروه های مقیاس خودکار جداگانه قرار دارند. همچنین یک متعادل کننده بار بین کاربر و لایه وب و بین لایه وب و لایه برنامه وجود دارد.
با داشتن یک متعادل کننده بار بین کاربر و لایه وب، سطح وب می تواند به طور مستقل مقیاس شود و از ویژگی مقیاس خودکار برای گفت ن یا حذف موارد در صورت نیاز استفاده کند.
کاربر نیازی ندارد بداند که به کدام نمونه متصل شود زیرا اتصال از طریق متعادل کننده بار است. این اتصال شل در عمل است. همین منطق بین لایه وب و لایه برنامه اعمال می شود. بدون متعادلکننده بار، نمونههای موجود در دو ردیف کاملاً به هم متصل میشوند و مقیاسگذاری را دشوار میکنند.
ردیف پایگاه داده در این مورد یک پایگاه داده RDS با یک گره اصلی و دو گره آماده به کار است. همه خواندن ها و نوشتن ها به گره اصلی می روند و اگر این گره از کار بیفتد، یک failover خودکار به یکی از نمونه های آماده به کار وجود دارد.
مقیاس خودکار تضمین می کند:
انعطافپذیری ، زیرا میتواند بهطور خودکار و فوری تعداد موارد را در پاسخ به تقاضای رو به رشد افزایش دهد. همچنین می تواند خود ترمیم شود، پس حتی اگر نیاز به پوسته پوسته شدن فوری و خودکار بر اساس تغییرات تقاضا را پیش بینی نکنید، خود درمانی تقریباً همیشه مورد نظر است زیرا در دسترس بودن معماری شما را افزایش می دهد.
کنترل هزینه ، از آنجایی که این قابلیت را دارد که تعداد نمونههای مورد استفاده را در دورههای تقاضای کمتر کاهش دهد، میتواند در هزینه شما صرفهجویی کند.
تعادل بار تضمین می کند:
توزیع بار ، زیرا از بارگیری بیش از حد یک گره با درخواست ها جلوگیری می کند
اتصال شل ، زیرا نیاز به آگاهی بین کاربران و نمونهها و بین خود نمونهها را از بین میبرد. این اجازه می دهد تا نمونه ها به طور مستقل مقیاس شوند
با تشکر از شما برای خواندن!
برچسبها
|
|




ارسال نظر