چگونه با پایتون یک Job Board Scraper بسازیم

اگر می خواهید بیاموزید که چگونه در بازار کار در حال تحول با از بین بردن سایت های آگهی کار مانند Indeed.com حرکت کنید، این راهنما برای شما مناسب است.
Job Scraper چیست؟
در عصر دیجیتال، ابزارهایی به نام Job Board Scraper (یا فقط Job Scrapers) برای افرادی که به دنبال خودکارسازی فرآیند جمعآوری دادهها از وبسایتهای هیئت شغلی هستند ضروری شدهاند.
تابلوهای شغلی پلتفرم های آنلاینی هستند که فرصت های شغلی بسیاری را از بخش های مختلف به نمایش می گذارند. برخی از نمونه های محبوب عبارتند از Indeed.com و ZipRecruiter.com. این تابلوها نبض بازار کار هستند که منعکس کننده روندهای شغلی فعلی، نیازهای شرکت و مهارت های مورد تقاضا هستند.
هدف اصلی Job Scraper جمعآوری دقیق جزئیاتی مانند عناوین شغلی، توضیحات، نام شرکت، مکانها و گاهی اوقات دادههای حقوق و دستمزد از فهرستهای این سایتها است. این اطلاعات یک هدف دوگانه را دنبال می کند: با ارائه یک نمای کلی از بازار به کارجویان در جستجوی شغل کمک می کند و تحلیلگران همچنین می توانند از آن برای ردیابی روندهای شغلی و پویایی بازار استفاده کنند.
آنچه در اینجا خواهید آموخت
این آموزش از زبان برنامه نویسی پایتون، محبوب ترین و همه کاره ترین ابزار برای کارهای خراش دادن وب استفاده می کند. اکوسیستم غنی کتابخانههای پایتون، مانند BeautifulSoup و Scrapy، آن را به انتخابی ایدهآل برای توسعه Job Scrapers کارآمد و مؤثر تبدیل میکند.
اگر در پایتون تازه کار هستید، میتوانید دوره مقدماتی پایتون در مورد مهارت هایپراسکل را تحلیل کنید، جایی که من به عنوان یک متخصص در آن مشارکت میکنم.
در پایان این راهنما، شما برای ساختن Job Scraper خود مجهز خواهید شد و درک عمیق تری از چشم انداز جستجوی کار و نحوه پیمایش آن با استفاده از بینش های مبتنی بر داده خواهید داشت.
چه شما یک جوینده کار باشید که به دنبال کسب برتری در جستجوی شغل خود هستید، یک تحلیلگر داده که روندهای بازار کار را ردیابی می کند، یا یک توسعه دهنده علاقه مند به جنبه های فنی اسکراپینگ وب، این آموزش دانش و مهارت های ارزشمندی را ارائه می دهد.
چارچوب های پایتون خوب برای کار
چندین چارچوب و کتابخانه پایتون وجود دارد که می توانید از آنها برای خراش دادن جزئیات کار از وب سایت فهرست مشاغل استفاده کنید. آنها هستند:
سوپ زیبا
خراشیده
سلنیوم
پیپتیر
ما از Pyppeteer برای این مقاله استفاده خواهیم کرد زیرا دارای مزایای کلیدی نسبت به کتابخانه های دیگر است. اگر هنوز نام Pyppeteer را نشنیده اید، این پورت پایتون فریم ورک محبوب Puppeteer است. می توانید اطلاعات بیشتری در مورد Puppeteer از وب سایت رسمی کسب کنید.
Pyppeteer اکثر قابلیت های Puppeteer را دارد و برای برنامه نویسان Python نوشته شده است. در اینجا برخی از مفیدترین ویژگی های آن آورده شده است:
Pyppeteer یک مرورگر واقعی را کنترل می کند. بسیاری از وب سایت ها از ورود روبات ها به وب سایت های خود جلوگیری می کنند. از آنجایی که Pyppeteer از یک مرورگر واقعی استفاده میکند، میتوانید از بسیاری از مسدود کردنهای مشابه جلوگیری کنید.
با Pyppeteer میتوانید بهطور برنامهنویسی اقدامات کاربر مانند کلیکها، ارسالهای فرم و ورودیهای صفحهکلید را تقلید کنید. همانطور که در این مقاله انجام خواهیم داد، این امکان پیمایش در جریان های پیچیده کاربر را فراهم می کند.
از آنجا که Pyppeteer یک مرورگر کامل را اجرا می کند، ذاتاً از ویژگی های وب مدرن مانند انتخابگرهای CSS، XPath و WebSockets پشتیبانی می کند. اگرچه ما فقط به برخی از این ویژگی های مدرن برای این مقاله نیاز داریم، اما بهتر است خراش دادن با چنین ابزاری را یاد بگیرید، زیرا احتمالاً هنگام انجام کارهای خراش دادن پیچیده تر به آن ویژگی ها نیاز خواهید داشت.
در اینجا چیزی است که ما پوشش خواهیم داد:
پیش نیازها
تنها پیش نیاز این آموزش نصب پایتون بر روی دستگاه شم است. اگر همچنان نیاز به انجام این کار دارید، پایتون را از وبسایت رسمی نصب کنید و آماده ادامه مقاله هستید.
چگونه با Pyppeteer شروع کنیم
یک محیط مجازی ایجاد کنید
قبل از شروع با Pyppeteer، اجازه دهید یک محیط مجازی برای این پروژه ایجاد کنیم.
python -m venv envاین دستور یک پوشه جدید به نام env در فهرست پروژه شما ایجاد می کند که حاوی یک نصب جداگانه پایتون است.
باید محیط مجازی را فعال کنید. در ویندوز با استفاده از دستور زیر می توانید محیط را فعال کنید:
.\env\Scripts\activateدر MacOS و Linux، باید این کار را با استفاده از دستور زیر انجام دهید:
source env/bin/activatePyppeteer را نصب کنید
با محیط مجازی فعال، می توانیم Pyppeteer را با استفاده از pip، مدیر بسته، نصب کنیم. وقتی پایتون را نصب میکنید، Pip قبلاً نصب شده است.
pip install pyppeteerپس از اجرای دستور بالا، پیپ Pyppeteer و وابستگی های آن را دانلود و نصب می کند.
به یاد داشته باشید که Pyppeteer نسخه اخیر Chromium سازگار با نسخه API مورد استفاده خود را دانلود خواهد کرد.
فرض کنید قبلاً یک نصب محلی Chrome/Chromium دارید و میخواهید Pyppeteer از آن استفاده کند. در این صورت، میتوانید متغیر محیطی PYPPETEER_CHROMIUM_REVISION را قبل از نصب Pyppeteer روی یک رشته خالی تنظیم کنید. با این کار Pyppeteer از دانلود Chromium جلوگیری می کند.
export PYPPETEER_CHROMIUM_REVISION="" pip install pyppeteerبا این حال، تنظیم متغیرهای محیطی در ویندوز متفاوت است. برای این کار باید از دستور زیر استفاده کنید:
set PYPPETEER_CHROMIUM_REVISION= pip install pyppeteerنحوه استخراج فهرست مشاغل با Pyppeteer
داده های هدف را در تابلوهای شغلی شناسایی کنید
قبل از نوشتن کد اسکرپینگ، وب سایتی را که قصد دارید خراش دهید را تحلیل کنید.
از وب سایت های هیئت شغلی مانند Indeed.com و ZipRecruiter.com دیدن کنید. عناصر صفحه را که در آن جزئیات کار نمایش داده می شود، تحلیل کنید (روی صفحه کلیک راست کرده و در اکثر مرورگرها "Inspect" را انتخاب کنید). به ساختار HTML و نام کلاس عناصر حاوی عناوین شغلی، توضیحات، نام شرکت، مکانها و سایر اطلاعات مرتبط توجه داشته باشید.
در این مقاله، نحوه خراشیدن Indeed.com را یاد خواهید گرفت. به Indeed.com بروید و صفحه اصلی زیر را مشاهده خواهید کرد:
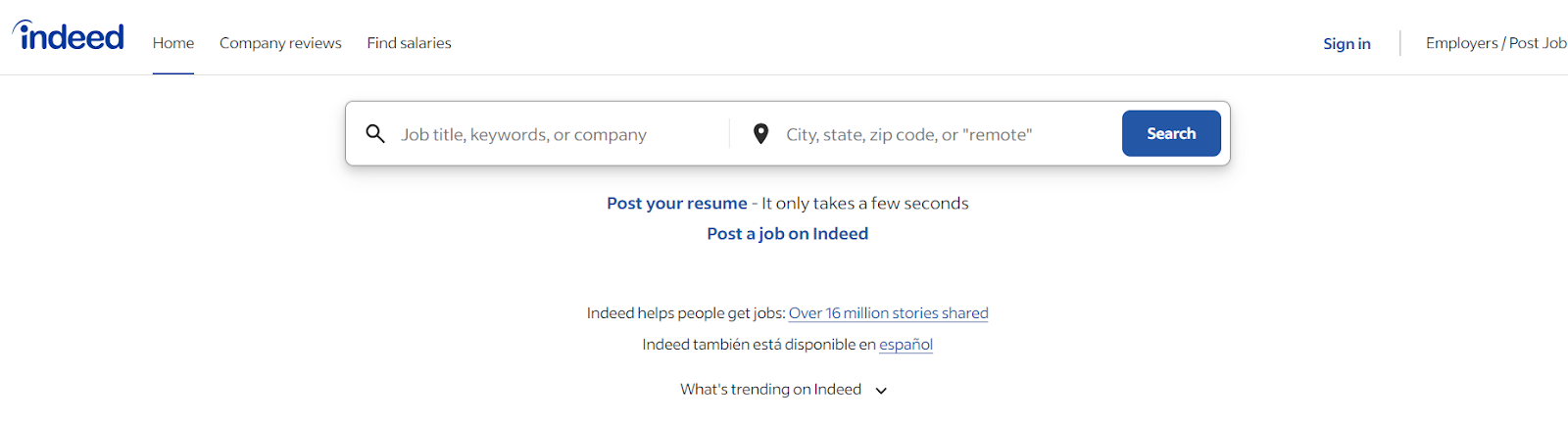
دارای دکمه جستجو با دو فیلد ورودی است. می توانید عنوان شغل را در قسمت ورودی اول و کشور را در قسمت ورودی دوم تایپ کنید.
بیایید برای عنوان شغل "مهندس نرم افزار" و برای کشور "USA" را تایپ کنیم، سپس روی "جستجو" کلیک کنیم. سپس به صفحه جدیدی هدایت خواهید شد که شامل تمام مشاغل مربوط به مهندسان نرم افزار در ایالات متحده است. اکنون میتوانیم جزئیات کار را از این صفحه هدایتشده حذف کنیم.
پس ، چه مراحلی برای خودکارسازی این فرآیند وجود دارد؟
یک نمونه مرورگر را باز کنید.
به Indeed.com بروید.
"مهندس نرم افزار" را به اولین فیلد ورودی اضافه کنید.
"USA" را به قسمت ورودی دوم اضافه کنید.
روی دکمه "جستجو" کلیک کنید.
برای انجام مراحل 3 و 4، باید صفحه وب را تحلیل کنیم و مقادیر ویژگی منحصر به فرد آن عناصر HTML را پیدا کنیم.
هنگام تحلیل کد منبع HTML صفحه، متوجه خواهید شد که شناسه فیلد ورودی عنوان شغل "text-input-what" و شناسه فیلد ورودی دوم، جایی که مکان را وارد می کنید، "Text-input" است. -جایی که."
پس از کلیک بر روی "جستجو"، به صفحه جدیدی هدایت می شویم.
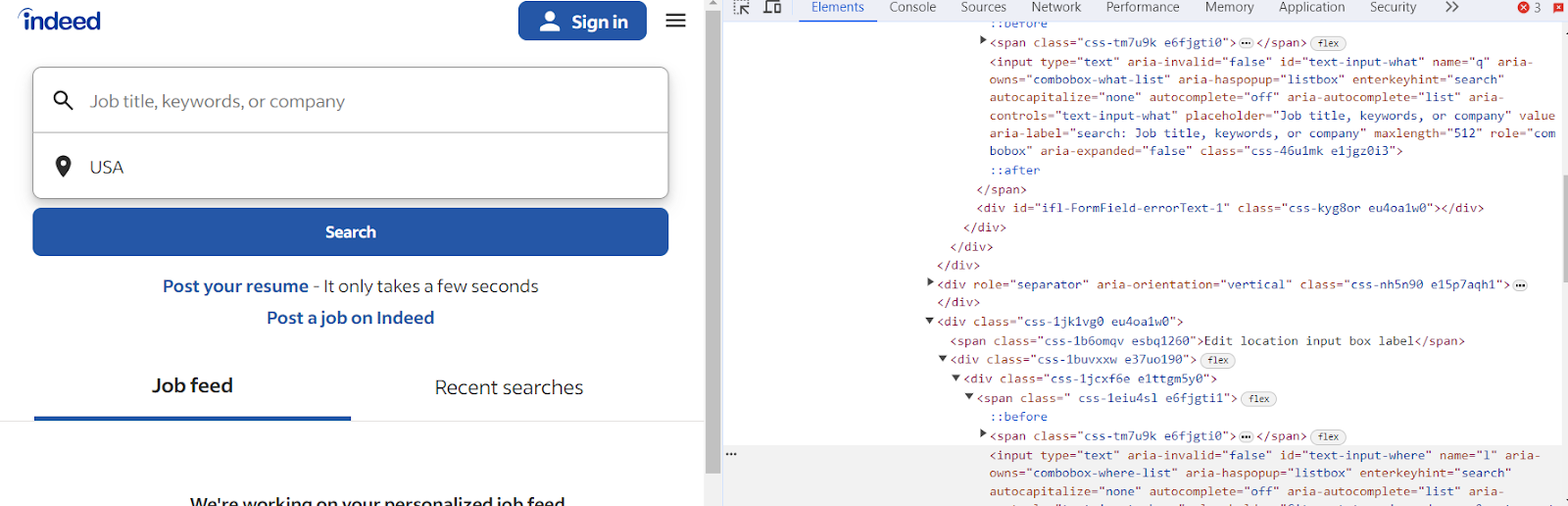
در این صفحه، هدف ما استخراج جزئیاتی مانند عنوان شغل، نام شرکت و محل کار است. تحلیل دقیق کد HTML موارد زیر را نشان می دهد:
عناوین شغلی درون تگ های h2 که دارای کلاس jobTitle هستند محصور می شوند.
نام شرکت ها در داخل یک span تو در تو در یک div با ویژگی data-testid= "company-name" قرار دارند.
مکان ها را می توان در یک span و در داخل یک div یافت، اما این یکی دارای ویژگی data-testid= "text-location" است.
با این درک، بیایید به نوشتن کد خود ادامه دهیم.
نحوه نوشتن کد اسکرپینگ
در Pyppeteer می توانیم از خطوط کد زیر برای اجرای مراحل ذکر شده در بالا استفاده کنیم.
ابتدا نمونه مرورگر را اجرا کنید.
browser = await launch(headless=False) page = await browser.newPage()سپس به indeed.com بروید.
await page.goto('https://www.indeed.com')صبر کنید تا عناصر فیلد ورودی بارگیری شوند. این مرحله بسیار مهم است زیرا کد اغلب سریعتر از بارگذاری صفحه اجرا می شود.
await page.waitForSelector('#text-input-what') await page.waitForSelector('#text-input-where')در ورودی عنوان شغلی "مهندس نرم افزار" و در ورودی مکان "USA" را تایپ کنید.
await page.type('#text-input-what', 'Software Engineer') await page.type('#text-input-where', 'USA')روی دکمه جستجو کلیک کنید.
await page.click('button[type="submit"]')صبر کنید تا صفحه بعدی بارگذاری شود
await page.waitForNavigation()عنوان شغل، نام شرکت و محل کار را استخراج کنید و اطلاعات را چاپ کنید.
job_listings = await page.querySelectorAll('.resultContent') for job in job_listings: # Extract the job title title_element = await job.querySelector('h2.jobTitle span[title]') title = await page.evaluate('(element) => element.textContent', title_element) # Extract the company name company_element = await job.querySelector('div.company_location [data-testid="company-name"]') company = await page.evaluate('(element) => element.textContent', company_element) # Extract the location location_element = await job.querySelector('div.company_location [data-testid="text-location"]') location = await page.evaluate('(element) => element.textContent', location_element) print({'title': title, 'company': company, 'location': location})مرورگر را ببندید.
await browser.close() هنگامی که کد کامل را جمع آوری کردیم، کدی را که در زیر می بینید دریافت می کنیم. async و await کلمات کلیدی هستند که در برنامه نویسی ناهمزمان استفاده می شوند. اگر می خواهید در مورد آن بیشتر بدانید، می توانید این مقاله را بخوانید . برنامه نویسی ناهمزمان برای کارآمدتر کردن خراش دادن مفید است.
import asyncio from pyppeteer import launch async def scrape_indeed(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('https://www.indeed.com') await page.waitForSelector('#text-input-what') await page.waitForSelector('#text-input-where') await page.type('#text-input-what', 'Software Engineer') await page.type('#text-input-where', 'USA') await page.click('button[type="submit"]') await page.waitForNavigation() job_listings = await page.querySelectorAll('.resultContent') for job in job_listings: # Extract the job title title_element = await job.querySelector('h2.jobTitle span[title]') title = await page.evaluate('(element) => element.textContent', title_element) # Extract the company name company_element = await job.querySelector('div.company_location [data-testid="company-name"]') company = await page.evaluate('(element) => element.textContent', company_element) # Extract the location location_element = await job.querySelector('div.company_location [data-testid="text-location"]') location = await page.evaluate('(element) => element.textContent', location_element) print({'title': title, 'company': company, 'location': location}) await browser.close() # Run the coroutine if __name__ == '__main__': asyncio.run(scrape_indeed())همانطور که با هر خط از این کد آشنا می شوید، می توانید آن را به روش های مختلف آزمایش کنید. به عنوان مثال، میتوانید شهرها و عناوین شغلی مختلف را برای دستیابی به نتایج متنوع اضافه کنید.
خراش دادن هر سایت دیگری از یک فرآیند مشابه پیروی می کند. تنها کاری که باید انجام دهید این است که عناصر HTML مربوطه و آپشن های منحصر به فرد آنها مربوط به جزئیاتی را که میخواهید استخراج کنید شناسایی کنید و سپس کد را مطابق با آن تنظیم کنید.
مراحل بعدی چیست؟
به عنوان مراحل بعدی، می توانید موارد زیر را انجام دهید:
داده های خراشیده شده را ذخیره کنید
به جای اینکه صرفاً داده های خراشیده شده را چاپ کنید، می توانید آن را در یک فایل CSV یا JSON برای استفاده بعدی ذخیره کنید. می توانید این کار را با قطعه کد زیر انجام دهید که داده ها را در قالب CSV ذخیره می کند.
with open('jobs.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerow(['Title', 'Company', 'Location'])پاکسازی و سازماندهی داده ها
هنگامی که داده های لازم را خراش دادید، تمیز کردن و سازماندهی موثر آنها گام مهم بعدی است.
این فرآیند شامل حذف ورودیهای تکراری برای اطمینان از منحصربهفرد بودن هر فهرست، استانداردسازی عناوین شغلی در قالب استاندارد برای مقایسه آسان، یا فیلتر کردن فهرستهایی است که با معیارهای خاص شما مطابقت ندارند. این مرحله برای ایجاد فهرستی از فرصت های شغلی مناسب و ارزشمند برای کاربران بسیار مهم است.
همچنین، دستهبندی دادهها را در زمینههای مختلف مانند «فهرست شرکت» و «شرکت مرتبط» در نظر بگیرید، که میتواند به ساختار منسجمتر دادهها کمک کند و آنها را برای تجزیه و تحلیل و بازیابی کاربر پسند کند.
یک رابط کاریابی ایجاد کنید
پس از تمیز کردن و سازماندهی داده های خود، زمان تصمیم گیری در مورد چارچوب یا ابزاری برای ارائه فهرست انتخاب شده از فرصت های شغلی است.
خواه یک صفحه وب اصلی را برای نمایش مستقیم فهرست ها انتخاب کنید، یک برنامه وب پیچیده با قابلیت جستجو و فیلتر پیشرفته، یا یک برنامه تلفن همراه برای دسترسی در حال حرکت، نکته کلیدی این است که مطمئن شوید پورتال شغلی شما کاربرپسند است. و در دسترس است.
رابط شما باید به کاربران اجازه دهد تا به راحتی در "فهرست باز شدن شغل" حرکت کنند و فرصت ها را بر اساس دسته بندی هایی مانند عنوان شغل، اندازه شرکت، مکان و سایر معیارهای مرتبط تحلیل کنند.
ملاحظات حقوقی و اخلاقی را در نظر بگیرید
درک مفاهیم حقوقی و اخلاقی خراش دادن وب بسیار مهم است. این شامل احترام به فایل robots.txt هر وبسایتی است که میخرید و به شرایط خدمات آنها پایبند هستید.
روشهای خراش دادن اخلاقی فقط مربوط به انطباق نیست - آنها در مورد اطمینان از این هستند که فعالیتهای خراش دادن شما تأثیر مخربی بر عملکرد وبسایت یا سوءاستفاده ناعادلانه از دادههای ارائهشده ندارد.
همانطور که دادهها را از سایتهای شرکت و پورتالهای شغلی جمعآوری میکنید، همیشه شفافیت و احترام به منبع داده، متعادل کردن جمعآوری دادهها و استانداردهای اخلاقی را در اولویت قرار دهید.
نتیجه
با این مراحل، شما باید یک اسکراپر کار برد با استفاده از Python و Pyppeteer داشته باشید. به یاد داشته باشید، خراش دادن وب به دلیل ماهیت پویای صفحات وب می تواند پیچیده باشد، پس انتظار داشته باشید که با تغییر ساختار وب سایت ها در طول زمان، تنظیمات خود را انجام دهید.
با تشکر از شما برای خواندن! من جس هستم و در Hyperskill متخصص هستم. می توانید دوره مقدماتی پایتون را در این پلتفرم تحلیل کنید.
برچسبها
|
|



ارسال نظر