نحوه کار با پایگاه های داده SQL در Go – روش ها و مثال های مختلف
زبان های برنامه نویسی مختلف روش های خاص خود را برای کار با پایگاه های داده رابطه ای و SQL دارند. Ruby on Rails دارای رکورد فعال است، پایتون دارای SQLAlchemy ، Typescript دارای Drizzle و غیره است.
Go یک زبان با کتابخانه استاندارد کاملاً متنوع است که شامل بسته معروف پایگاه داده/sql است. و کتابخانه ها و راه حل های خود را برای کار با SQL دارد که با نیازها، اولویت ها و تیم های مختلف مطابقت دارد.
در این مقاله، پرکاربردترین بستههای Go را که به شما امکان کار با SQL را میدهند، تحلیل و مقایسه میکنیم. ما به چند نمونه عملی و همچنین مزایا و معایب آن نگاه خواهیم کرد. همچنین به طور خلاصه به موضوع مهاجرت پایگاه داده و نحوه مدیریت آنها در Go می پردازیم.
اگر قبلاً با Go، SQL و پایگاههای داده رابطهای (مهم نیست کدام یک) تجربه داشته باشید، بیشترین بهره را از این مقاله خواهید برد.
فهرست مطالب
کد Go از SQL با استفاده از sqlc تولید شد
طرحواره نمایشی
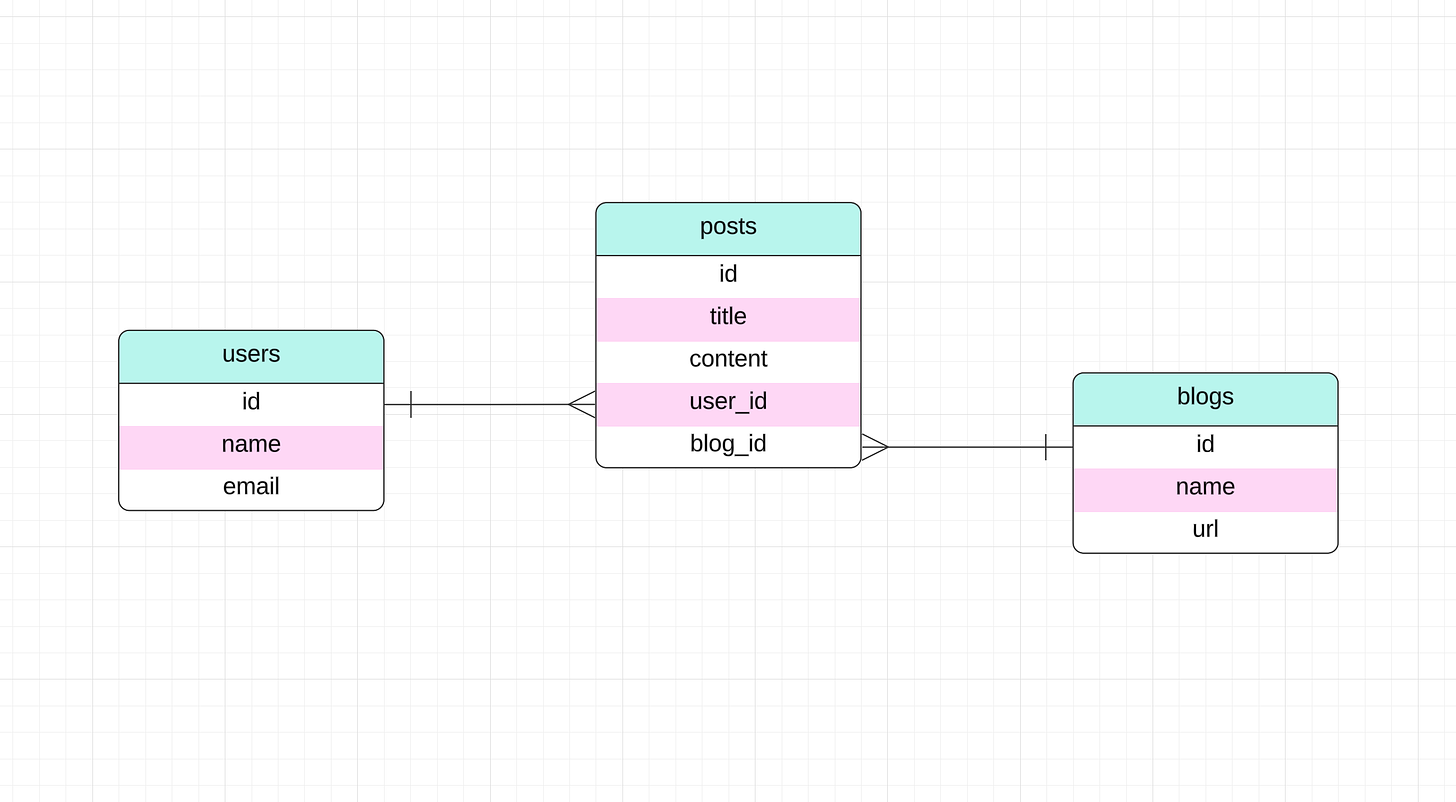
برای این مقاله، از یک طرحواره ساده با سه جدول استفاده میکنیم: کاربران ، پستها و وبلاگها . برای سادگی، ما از SQLite به عنوان موتور پایگاه داده خود استفاده خواهیم کرد. اما اگر میخواهید موتور پایگاه داده دیگری را انتخاب کنید، مشکلی نیست، زیرا همه کتابخانههایی که ما در حال تحلیل آن خواهیم بود از چندین گویش SQL پشتیبانی میکنند.
در اینجا طرح پایگاه داده ما در SQL است:
CREATE TABLE users ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL , email TEXT NOT NULL UNIQUE ); CREATE TABLE blogs ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL , url TEXT NOT NULL UNIQUE ); CREATE TABLE posts ( id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT NOT NULL , content TEXT NOT NULL , user_id INTEGER NOT NULL , blog_id INTEGER NOT NULL , FOREIGN KEY (user_id) REFERENCES users ( id ) ON DELETE CASCADE , FOREIGN KEY (blog_id) REFERENCES blogs ( id ) ON DELETE CASCADE );و در اینجا نمودار Entity-Relationship (ERD) آن است:
 از سه جدول را نمایش می دهد: کاربران، پست ها و وبلاگ ها" width="1456" height="802" loading="lazy">
از سه جدول را نمایش می دهد: کاربران، پست ها و وبلاگ ها" width="1456" height="802" loading="lazy">
SQL خام و پایگاه داده/sql
بیایید تصور کنیم که برنامه شما باید عمل زیر را انجام دهد:
کاربرانی را که حداقل دو مقاله ارسال کرده اند، به همراه تعداد کل پست هایی که منتشر کرده اند، پیدا کنید.
در SQL خالص، می توانید آن را به پرس و جو زیر ترجمه کنید:
SELECT u.name, COUNT (p.id) AS post_count FROM users AS u JOIN posts AS p ON u.id = p.user_id GROUP BY u.id HAVING post_count >= 2 ;توضیح مختصری در مورد این پرس و جو: ما به کاربران و جداول پست میپیوندیم، سپس توسط user_id گروه بندی میکنیم. بند HAVING نتایج را فیلتر می کند تا فقط کاربرانی را شامل شود که حداقل 2 پست ارسال کرده اند و COUNT تعداد پست ها را جمع می کند.
همانطور که در بالا ذکر شد، Go یک بسته داخلی به نام پایگاه داده/sql با ابزارهای لازم برای کار با پایگاه های داده SQL ارائه می دهد. با در نظر گرفتن سادگی توسعه داده شده است، اما از تمام عملکردهای لازم مانند تراکنش ها، پرس و جوهای پارامتری، مدیریت استخر اتصال و غیره پشتیبانی می کند.
تا زمانی که در نوشتن پرس و جوهای خود و رسیدگی به خطاها و نتایج راحت هستید، این یک گزینه عالی است. و برخی می گویند که این بهترین گزینه است، زیرا هیچ منطق پنهانی وجود ندارد و همیشه می توانید پرس و جو را کپی کنید و آن را با EXPLAIN تجزیه و تحلیل کنید.
در اینجا نحوه دریافت نتایج جستجوی بالا در کد Go با استفاده از پایگاه داده/sql آمده است (بعضی از بخشها مانند اتصال حذف شدهاند):
type userStats struct { UserName sql.NullString PostCount sql.NullInt64 } func getUsersStats (conn *sql.DB, minPosts int ) ([]userStats, error) { query := `SELECT u.name, COUNT(p.id) AS post_count FROM users AS u JOIN posts AS p ON u.id = p.user_id GROUP BY u.id HAVING post_count >= ?;` rows, err := conn.Query(query, minPosts) if err != nil { return nil , err } defer rows.Close() users := []userStats{} for rows.Next() { var user userStats if err := rows.Scan(&user.UserName, &user.PostCount); err != nil { return nil , err } users = append (users, user) } if err := rows.Err(); err != nil { return nil , err } return users, nil }در این کد ما:
از کوئری خام SQL با یک پارامتر بی نام استفاده کنید و مقدار این پارامتر را در conn.Query() ارسال کنید.
روی ردیف های برگشتی تکرار کنید و هر ردیف را به صورت دستی در ساختار userStats که در بالا تعریف شده است اسکن کنید. توجه داشته باشید که ساختار از انواع sql.Null* برای مدیریت صحیح مقادیر nullable استفاده می کند.
باید به صورت دستی خطاهای احتمالی را تحلیل کنیم و ردیف ها را ببندیم تا منابع آزاد شوند.
جوانب مثبت:
انتزاع/پیچیدگی اضافی اضافه نشده است. اشکال زدایی پرس و جوهای خام SQL آسان است.
عمل کرد. بسته پایگاه داده/sql کاملاً کارآمد است.
یک انتزاع به اندازه کافی خوب از باطن های مختلف پایگاه داده ارائه می دهد.
معایب:
کد کمی پیچیده می شود زیرا نیاز به اسکن هر ردیف، تعریف انواع مناسب و رسیدگی به خطاها وجود دارد.
بدون ایمنی نوع کامپایل.
منبع کامل این مقاله را می توانید در این مخزن Github بیابید.
SQL خام و sqlx
حال بیایید نگاهی به برخی بسته های خارجی که در انجمن Go محبوب هستند بیندازیم.
اگر قبلاً با پایگاه داده/sql آشنا هستید و سادگی آن را دوست دارید، ممکن است از کار با sqlx لذت ببرید. این در بالای کتابخانه استاندارد ساخته شده است و فقط ویژگی های آن را گسترش می دهد.
ادغام پایگاه های کد موجود با استفاده از پایگاه داده/sql با sqlx بسیار آسان است، زیرا اینترفیس های زیرین مانند sql.DB، sql.Tx و غیره را دست نخورده می گذارد.
ویژگی های اصلی sqlx عبارتند از:
پارامترهای نامگذاری شده
اسکن ردیف آسان تر به ساختار با پشتیبانی ساختار تعبیه شده.
با استفاده از متدهای Get() و Select() جداسازی بهتر بین سطرهای منفرد و چندگانه.
امکان اتصال تکه ای از مقادیر به عنوان یک پارامتر واحد به یک کوئری IN.
در اینجا نحوه دریافت نتایج جستجوی بالا با استفاده از sqlx آمده است:
type userStats struct { UserName string `db:"name"` PostCount string `db:"post_count"` } func getUsersStats (conn *sqlx.DB, minPosts int ) ([]userStats, error) { users := []userStats{} query := `SELECT u.name, COUNT(p.id) AS post_count FROM users AS u JOIN posts AS p ON u.id = p.user_id GROUP BY u.id HAVING post_count >= ?;` if err := conn.Select(&users, query, minPosts); err != nil { return nil , err } return users, nil } در این کد از متد Select() استفاده می کنیم که اسکن سطرها را انجام می دهد. همچنین ردیف ها را به طور خودکار می بندد تا مجبور نباشیم با آن کار کنیم.
کد بسیار کوتاهتر از نسخه پایگاه داده/sql است، اما می تواند برخی از جزئیات پیاده سازی را از ما پنهان کند. به عنوان مثال، توجه داشته باشید که Select کل مجموعه را به یکباره در حافظه بارگذاری می کند.
جوانب مثبت:
تفاوت چندانی با پایگاه داده/sql ندارد. اشکال زدایی پرس و جوهای خام SQL هنوز آسان است.
مجموعه ای از ویژگی های عالی برای کاهش پرحرفی کد.
معایب:
همانند پایگاه داده/sql
ORM ها
نگاشت شی رابطه ای (ORM) تکنیکی است (بعضی آن را الگوی طراحی می نامند) برای دسترسی به پایگاه داده رابطه ای با کار با اشیا بدون نیاز به ساخت عبارات پیچیده SQL. در زبان های شی گرا بسیار محبوب است - Ruby on Rails دارای رکورد فعال است، پایتون دارای SQLAlchemy ، Typescript دارای Drizzle و غیره است.
و Go GORM دارد. به طور خلاصه، به شما امکان می دهد پرس و جوها را به عنوان کد Go با فراخوانی روش های مختلف بر روی اشیاء بنویسید، که سپس به کوئری های SQL ترجمه می شوند. اما نه تنها این، بلکه دارای ویژگی های دیگری مانند مهاجرت پایگاه داده، حل کننده های پایگاه داده و موارد دیگر است.
ممکن است در ابتدا نیاز به صرف کمی زمان برای تنظیم مدلهای GORM داشته باشید، اما بعداً میتواند مقدار زیادی از کدهای دیگ بخار را کاهش دهد.
طرح و مثال پرس و جو ساده ما ممکن است برای تجسم نقاط قوت و ضعف GORM بهترین نباشد، اما باید برای نشان دادن نحوه اجرای یک پرس و جو مشابه و اسکن نتایج کافی باشد:
type User struct { gorm.Model ID int Name string Posts []Post } type Post struct { gorm.Model ID int UserID int } type userStats struct { Name string Count int `gorm:"column:post_count"` } func getUsersStats (conn *gorm.DB, minPosts int ) ([]userStats, error) { var users []userStats err := conn.Model(&User{}). Select( "name" , "COUNT(p.id) AS post_count" ). Joins( "JOIN posts AS p ON users.id = p.user_id" ). Group( "users.id" ). Having( "post_count >= ?" , minPosts). Find(&users).Error return users, err }پرس و جوی SQL تولید شده توسط gorm تقریباً همان چیزی است که به صورت دستی در نوع پایگاه داده/sql نوشتیم.
برای خلاصه کردن کد بالا:
ما مدل های User و Post خود را اعلام کردیم و آن را با ساختار پیش فرض gorm.Model گسترش دادیم. بعداً میتوانیم از این دو مدل برای ساخت هر کوئری که میخواهیم با استفاده از متدهای gorm استفاده کنیم.
ما همچنین userStats نوع نتیجه کوچک خود را تعریف کردیم
ما از متدهایی مانند Select() ، Joins() ، Group() و Having() برای تولید کوئری مورد نظر خود استفاده کردیم.
با چنین مثال ساده ای، دیدن مسائل بالقوه دشوار است - همه چیز درست به نظر می رسد. اما وقتی پروژه شما پیچیدهتر میشود، قطعاً با مشکلاتی در آن مواجه خواهید شد. فقط به سوالات StackOverflow که با go-gorm مشخص شده اند نگاه کنید.
خوب است در مورد استفاده از ORM ها در سیستم های حیاتی عملکرد یا جاهایی که نیاز به کنترل مستقیم بر تعاملات پایگاه داده دارید، مراقب باشید. این به این دلیل است که gorm از بازتاب زیادی استفاده میکند و میتواند سربار اضافه کند و گاهی اوقات آنچه را که در سطح پایگاه داده اتفاق میافتد مبهم کند. هر پروژه ای که در آن عملکرد در یک لایه بزرگ دیگر پیچیده شود، خطر افزایش پیچیدگی کلی را دارد.
جوانب مثبت:
انتزاع از باطن های مختلف پایگاه داده.
مجموعه ویژگی های بزرگ: مهاجرت ها، قلاب ها، حل کننده های پایگاه داده و موارد دیگر.
مقدار کمی از کدنویسی خسته کننده را ذخیره می کند.
معایب:
لایه دیگری از پیچیدگی و سربار. اشکال زدایی پرس و جوهای خام SQL سخت است.
اشکالات عملکرد ممکن است برای برخی از برنامه های کاربردی حیاتی کارآمد نباشد.
راه اندازی اولیه ممکن است به مدتی برای پیکربندی همه مدل ها نیاز داشته باشد.
کد Go را از SQL با استفاده از sqlc تولید کرد
این به خوبی ما را به یک رویکرد منحصر به فرد دیگر برای تولید کد Go از کوئری های SQL با استفاده از sqlc می رساند. با sqlc، طرح و پرس و جوهای SQL خود را می نویسید، سپس از یک ابزار CLI برای تولید کد Go از آن استفاده می کنید و سپس از کد تولید شده برای تعامل با پایگاه های داده استفاده می کنید.
این تضمین می کند که پرس و جوهای شما از نظر نحوی صحیح و ایمن هستند. برای کسانی که نوشتن SQL را ترجیح می دهند، اما به دنبال راهی کارآمد برای ادغام آن در برنامه Go هستند، ایده آل است.
sqlc برای تولید کد باید طرح و پرس و جوهای پایگاه داده شما را بشناسد، پس نیاز به تنظیمات اولیه دارد. می توانیم طرح و پرس و جوی خود را در بالا به فایل های schema.sql و query.sql اضافه کنیم. سپس با استفاده از کانفیگ زیر می توانیم کد Go را تولید کنیم:
version: "2" sql: - engine: "sqlite" queries: "query.sql" schema: "schema.sql" gen: go: package: "main" out: "."همچنین باید کوئری خود را در query.sql نامگذاری کنیم و پارامترها را علامت گذاری کنیم:
-- name: GetUsersStats :many SELECT u.name, COUNT (p.id) AS post_count FROM users AS u JOIN posts AS p ON u.id = p.user_id GROUP BY u.id HAVING post_count >= ?; پس از اجرای sqlc generate ، میتوانیم از انواع و توابع تولید شده زیر استفاده کنیم که کد ما را از نظر نوع ایمن و کاملاً کوتاه میسازد.
func getUsersStats (conn *sql.DB, minPosts int ) ([]GetUsersStatsRow, error) { queries := New(conn) ctx := context.Background() return queries.GetUsersStats(ctx, minPosts) }چیزی که sqlc را خاص می کند این است که شمای پایگاه داده شما را درک می کند و از آن برای اعتبارسنجی SQL که می نویسید استفاده می کند. پس پرس و جوهای SQL شما در مقابل جدول پایگاه داده واقعی اعتبارسنجی می شوند و sqlc اگر مشکلی وجود داشته باشد یک خطای زمان کامپایل به شما می دهد.
جوانب مثبت:
ایمنی را با کد Go ایجاد شده تایپ کنید.
اشکال زدایی کد SQL هنوز آسان است.
مقدار کمی از کدنویسی خسته کننده را ذخیره می کند.
عمل کرد.
معایب:
تنظیمات اولیه برای طرح و پرس و جوهای پایگاه داده.
تجزیه و تحلیل استاتیک کامل نیست. گاهی اوقات شما نیاز دارید که نوع پارامتر را به صراحت تنظیم کنید و غیره.
اگر با دستورات SQL خوب هستید و ترجیح می دهید از کد زیادی برای بیان تعاملات پایگاه داده خود استفاده نکنید، این بسته شم است.
مهاجرت های پایگاه داده
از آنجایی که در اینجا به موضوع پایگاه داده های SQL می پردازیم، اجازه دهید به طور خلاصه نحوه عملکرد انتقال پایگاه داده در Go را تحلیل کنیم. طرح واره پایگاه داده تقریباً همیشه در طول زمان تکامل می یابد و هیچ کس نمی خواهد این تغییرات را به صورت دستی انجام دهد. پس ابزارهایی برای کمک به آن وجود دارد.
هدف اصلی ابزارهای انتقال پایگاه داده این است که اطمینان حاصل شود که همه محیطها طرحواره یکسانی دارند و توسعهدهندگان میتوانند به راحتی تغییرات را اعمال کنند یا آنها را به عقب برگردانند.
در بالا ذکر کردم که اگر پروژه شما از آن به عنوان ORM خود استفاده کند، GORM می تواند مهاجرت ها را نیز انجام دهد. اگر از پایگاه داده/sql، sqlx یا sqlc استفاده می کنید، باید از پروژه های جداگانه برای مدیریت آنها استفاده کنید.
محبوب ترین پروژه ها عبارتند از:
golang-migrate : یکی از معروف ترین ابزارها برای مدیریت مهاجرت پایگاه داده. این برنامه از بسیاری از درایورهای پایگاه داده و منابع مهاجرت پشتیبانی می کند و یک رویکرد ساده و مستقیم برای مدیریت مهاجرت پایگاه داده دارد.
غاز : یکی دیگر از گزینه های محکم هنگام انتخاب ابزار مهاجرت. همچنین از درایورهای اصلی پایگاه داده پشتیبانی می کند. دو مورد از ویژگی های اصلی آن پشتیبانی از مهاجرت های نوشته شده در Go و کنترل بیشتر فرآیند برنامه مهاجرت است.
سپس می توانید این ابزارها را مستقیماً در برنامه خود یا در CI/CD ادغام کنید. اما اجرای صحیح آنها در CI/CD نیاز به تنظیماتی دارد (مثلاً در صورت استقرار در Kubernetes)، و من در مقالههای آیندهام عمیقتر به آن خواهم پرداخت.
نتیجه گیری
بسیاری از بسته های پایگاه داده خوب نوشته، آزمایش شده و پشتیبانی شده برای Go وجود دارد که می تواند به شما در توسعه سریعتر و نوشتن کدهای پاک تر کمک کند. همچنین پایگاه داده/sql بسیار قدرتمندی در کتابخانه استاندارد موجود است که می تواند بیشتر کارهای روزانه شما را انجام دهد.
اما اینکه آیا باید از آن استفاده کنید یا نه بستگی به نیاز شما به عنوان یک توسعه دهنده، ترجیحات و پروژه شما دارد. در این مقاله سعی کردم نقاط قوت و ضعف هر گزینه را برجسته کنم.
می توانید منبع کامل این مقاله را در این مخزن Github بیابید.
من این مقاله را با این میم معروف به پایان می برم:

منابع
مقالات بیشتری را از packagemain.tech کشف کنید
برچسبها
|
|



ارسال نظر