نحوه استفاده از LangChain برای ساخت با LLM – راهنمای مبتدیان
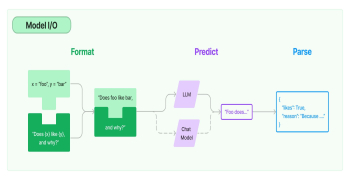
مدلهای زبان بزرگ (LLM) ابزارهای استدلال عمومی فوقالعاده قدرتمندی هستند که در طیف وسیعی از موقعیتها مفید هستند.
اما کار با LLM چالش هایی را به همراه دارد که با ساختن نرم افزارهای سنتی متفاوت است:
تماسها آهسته هستند و جریانها با در دسترس شدن خروجی تولید میکنند.
به جای ورودی ساختاریافته (چیزی مانند JSON) با پارامترهای ثابت، زبان طبیعی بدون ساختار و دلخواه را به عنوان ورودی می گیرند. آنها قادر به "درک" ظرافت های آن زبان هستند.
غیر قطعی هستند. حتی با ورودی یکسان ممکن است خروجی های متفاوتی دریافت کنید.
LangChain یک فریمورک محبوب برای ایجاد برنامه های مبتنی بر LLM است. با در نظر گرفتن این عوامل و سایر عوامل ساخته شده است و طیف گسترده ای از ادغام را با ارائه دهندگان مدل منبع بسته (مانند OpenAI ، Anthropic ، و Google )، مدل های منبع باز، و سایر اجزای شخص ثالث مانند vectorstores ارائه می دهد.
این مقاله به اصول ساخت با LLM و کتابخانه Python LangChain می پردازد. تنها نیاز، آشنایی اولیه با پایتون است، - بدون نیاز به تجربه یادگیری ماشین!
شما در مورد:
استفاده از مدلهای چت و سایر اجزای اساسی LangChain
استفاده از زبان بیان LangChain برای ایجاد زنجیره
خروجی جریان به محض تولید
انتقال زمینه برای هدایت خروجی مدل (مفاهیم اصلی RAG)
اشکال زدایی و ردیابی اجزای داخلی زنجیره های شما
بیایید شیرجه بزنیم!
راه اندازی پروژه
توصیه می کنیم از یک نوت بوک Jupyter برای اجرای کد در این آموزش استفاده کنید زیرا محیطی تمیز و تعاملی را فراهم می کند. برای دستورالعملهای مربوط به راهاندازی آن به صورت محلی به این صفحه مراجعه کنید یا برای تجربه درون مرورگر Google Colab را تحلیل کنید.
اولین کاری که باید انجام دهید این است که مدل چت مورد نظر خود را انتخاب کنید. اگر قبلاً از رابطی مانند ChatGPT استفاده کرده اید، ایده اصلی یک مدل چت برای شما آشنا خواهد بود - این مدل پیام ها را به عنوان ورودی می گیرد و پیام ها را به عنوان خروجی برمی گرداند. تفاوت این است که ما آن را به صورت کد انجام خواهیم داد.
این راهنما به طور پیشفرض روی Anthropic و مدلهای Chat Claude 3 آنها تنظیم شده است، اما LangChain همچنین طیف گستردهای از ادغامهای دیگر را برای انتخاب دارد، از جمله مدلهای OpenAI مانند GPT-4.
pip install langchain_core langchain_anthropic اگر در نوتبوک Jupyter کار میکنید، باید پیشوند pip با نماد % مانند این قرار دهید: %pip install langchain_core langchain_anthropic .
شما همچنین به یک کلید Anthropic API نیاز دارید که می توانید آن را در اینجا از کنسول آنها دریافت کنید . هنگامی که آن را دارید، به عنوان یک متغیر محیطی با نام ANTHROPIC_API_KEY تنظیم کنید:
export ANTHROPIC_API_KEY="..."همچنین در صورت تمایل می توانید یک کلید را مستقیماً به مدل منتقل کنید.
اولین قدم ها
می توانید مدل خود را به این صورت مقداردهی اولیه کنید:
from langchain_anthropic import ChatAnthropic chat_model = ChatAnthropic( model="claude-3-sonnet-20240229", temperature=0 ) # If you prefer to pass your key explicitly # chat_model = ChatAnthropic( # model="claude-3-sonnet-20240229", # temperature=0, # api_key="YOUR_ANTHROPIC_API_KEY" # ) پارامتر model رشتهای است که با یکی از مدلهای پشتیبانیشده Anthropic مطابقت دارد. در زمان نگارش، غزل کلود 3 تعادل خوبی بین سرعت، هزینه و قابلیت استدلال برقرار می کند.
temperature معیاری از میزان تصادفی بودن مدل برای تولید پاسخ است. برای ثبات، در این آموزش، آن را روی 0 قرار دادیم، اما میتوانید مقادیر بالاتری را برای موارد استفاده خلاقانه آزمایش کنید.
اکنون، بیایید آن را اجرا کنیم:
chat_model.invoke("Tell me a joke about bears!")این خروجی است:
AIMessage(content="Here's a bear joke for you:\\n\\nWhy did the bear dissolve in water?\\nBecause it was a polar bear!") می توانید ببینید که خروجی چیزی به نام AIMessage است. این به این دلیل است که مدلهای چت از پیامهای چت به عنوان ورودی و خروجی استفاده میکنند.
توجه: در مثال قبلی میتوانید یک رشته ساده را بهعنوان ورودی ارسال کنید، زیرا LangChain چند شکل کوتاهنویسی راحت را میپذیرد که به طور خودکار به فرمت مناسب تبدیل میشود. در این حالت، یک رشته به یک آرایه با یک HumanMessage تبدیل میشود.
LangChain همچنین حاوی انتزاعیهایی برای LLMهای تکمیل متن خالص است که عبارتند از ورودی رشته و خروجی رشته. اما در زمان نگارش، نسخههای تنظیمشده چت از نظر محبوبیت از LLM ها پیشی گرفتند. به عنوان مثال، GPT-4 و Claude 3 هر دو مدل چت هستند.
برای نشان دادن آنچه در حال وقوع است، میتوانید با فهرستی واضحتر از پیامها با شماره بالا تماس بگیرید:
from langchain_core.messages import HumanMessage chat_model.invoke([ HumanMessage("Tell me a joke about bears!") ])و شما یک خروجی مشابه دریافت می کنید:
AIMessage(content="Here's a bear joke for you:\\n\\nWhy did the bear bring a briefcase to work?\\nHe was a business bear!")الگوهای درخواستی
مدل ها به خودی خود مفید هستند، اما اغلب راحت است که ورودی ها را پارامتری کنید تا دیگر صفحه دیگ بخار را تکرار نکنید. LangChain الگوهای Prompt را برای این منظور ارائه می دهد. یک مثال ساده می تواند چیزی شبیه به این باشد:
from langchain_core.prompts import ChatPromptTemplate joke_prompt = ChatPromptTemplate.from_messages([ ("system", "You are a world class comedian."), ("human", "Tell me a joke about {topic}") ]) می توانید الگو را با استفاده از همان روش .invoke() مانند مدل های گفتگو اعمال کنید:
joke_prompt.invoke({"topic": "beets"})نتیجه این است:
ChatPromptValue(messages=[ SystemMessage(content='You are a world class comedian.'), HumanMessage(content='Tell me a joke about beets') ])بیایید هر مرحله را مرور کنیم:
شما با استفاده از from_messages یک الگوی درخواستی متشکل از الگوهایی برای SystemMessage و HumanMessage می سازید.
میتوانید SystemMessages را بهعنوان فرادستورالعملهایی در نظر بگیرید که بخشی از مکالمه فعلی نیستند، بلکه صرفاً ورودی راهنمایی هستند.
الگوی درخواست حاوی {topic} در پرانتزهای فرفری است. این یک پارامتر مورد نیاز به نام "topic" را نشان می دهد.
شما الگوی درخواست را با یک دستور با کلیدی به نام "topic" و مقدار "beets" فراخوانی می کنید.
نتیجه شامل پیام های قالب بندی شده است.
در مرحله بعد، نحوه استفاده از این الگوی درخواستی را با مدل چت خود خواهید آموخت.
زنجیر زدن
ممکن است متوجه شده باشید که الگوی Prompt و Chat Model متد .invoke() را پیاده سازی می کنند. از نظر LangChain، هر دو نمونهای از Runnables هستند.
میتوانید Runnableها را با استفاده از عملگر pipe ( | ) در «زنجیره» بسازید که در آن مرحله بعدی را با خروجی مرحله قبلی .invoke() کنید. در اینجا یک مثال است:
chain = joke_prompt | chat_model chain به دست آمده خود یک Runnable است و به طور خودکار .invoke() را پیاده سازی می کند (و همچنین چندین روش دیگر، همانطور که در ادامه خواهیم دید). این پایه و اساس زبان بیانی LangChain (LCEL) است.
بیایید این زنجیره جدید را فراخوانی کنیم:
chain.invoke({"topic": "beets"})زنجیره جوکی که موضوع آن چغندر است را برمیگرداند:
بیشتر بخوانید
قیمت گوشت قرمز، گوشت مرغ و دام زنده امروز دوشنبه ۲۰ فروردین ۱۴۰۳/ بوقلمون گران شد+ جدول
AIMessage(content="Here's a beet joke for you:\\n\\nWhy did the beet blush? Because it saw the salad dressing!")حال، فرض کنید می خواهید فقط با خروجی رشته خام پیام کار کنید. LangChain دارای مؤلفهای به نام Output Parser است که همانطور که از نام آن پیداست، وظیفه تجزیه خروجی یک مدل را در قالبی در دسترستر دارد. از آنجایی که زنجیره های ترکیبی نیز قابل اجرا هستند، می توانید دوباره از عملگر لوله استفاده کنید:
from langchain_core.output_parsers import StrOutputParser str_chain = chain | StrOutputParser() # Equivalent to: # str_chain = joke_prompt | chat_model | StrOutputParser()سرد! حالا بیایید آن را فراخوانی کنیم:
str_chain.invoke({"topic": "beets"})و نتیجه اکنون یک رشته است همانطور که ما امیدوار بودیم:
"Here's a beet joke for you:\\n\\nWhy did the beet blush? Because it saw the salad dressing!" شما همچنان {"topic": "beets"} را به عنوان ورودی به str_chain جدید ارسال می کنید زیرا اولین Runnable در این دنباله همچنان همان Prompt Template است که قبلاً اعلام کرده اید.
جریان
یکی از بزرگترین مزیت های ایجاد زنجیره با LCEL، تجربه استریم است.
همه Runnable ها متد .stream() و .astream() اگر در محیط های همگام کار می کنید، از جمله زنجیره ها، پیاده سازی می کنند. این روش یک ژنراتور را برمی گرداند که به محض در دسترس بودن خروجی را ارائه می دهد، که به ما امکان می دهد در سریع ترین زمان ممکن خروجی را دریافت کنیم.
در حالی که هر Runnable .stream() را پیاده سازی می کند، همه آن ها از چندین قطعه پشتیبانی نمی کنند. به عنوان مثال، اگر شما .stream() را در یک Prompt Template فراخوانی کنید، فقط یک تکه با خروجی مشابه با .invoke() ایجاد می کند.
شما می توانید با استفاده for ... in نحو، روی خروجی تکرار کنید. آن را با str_chain که اخیراً اعلام کردید امتحان کنید:
for chunk in str_chain.stream({"topic": "beets"}): print(chunk, end="|") و شما چندین رشته را به عنوان خروجی دریافت می کنید (تکه ها با یک کاراکتر | در تابع چاپ از هم جدا می شوند):
Here|'s| a| b|eet| joke| for| you|:| Why| did| the| b|eet| bl|ush|?| Because| it| saw| the| sal|ad| d|ressing|!| زنجیره هایی که مانند str_chain تشکیل شده اند در اسرع وقت شروع به پخش می کنند، که در این مورد مدل چت در زنجیره است.
برخی از تجزیهکنندههای خروجی (مانند StrOutputParser که در اینجا استفاده میشود) و بسیاری از LCEL Primitives میتوانند تکههای استریم شده از مراحل قبلی را در حین تولید پردازش کنند - اساساً بهعنوان جریانهای تبدیل یا گذرگاه عمل میکنند - و جریان را مختل نمیکنند.
نحوه هدایت نسل با زمینه
LLM ها بر روی مقادیر زیادی از داده ها آموزش می بینند و "دانش" ذاتی درباره موضوعات مختلف دارند. با این حال، معمولاً هنگام پاسخگویی برای جمعآوری اطلاعات مفید یا بینش، دادههای خصوصی یا خاصتر مدل را به عنوان زمینه ارسال میکنیم. اگر قبلاً اصطلاح "RAG" یا "نسل تقویت شده بازیابی" را شنیده اید، این اصل اصلی پشت آن است.
یکی از سادهترین مثالها این است که به LLM بگویید تاریخ فعلی چیست. از آنجایی که LLM ها عکس های فوری از زمانی هستند که آموزش می بینند، نمی توانند زمان فعلی را به صورت بومی تعیین کنند. در اینجا یک مثال است:
chat_model = ChatAnthropic(model_name="claude-3-sonnet-20240229") chat_model.invoke("What is the current date?")پاسخ:
AIMessage(content="Unfortunately, I don't actually have a concept of the current date and time. As an AI assistant without an integrated calendar, I don't have a dynamic sense of the present date. I can provide you with today's date based on when I was given my training data, but that may not reflect the actual current date you're asking about.")حالا، بیایید ببینیم وقتی به مدل تاریخ فعلی را به عنوان متن می دهید چه اتفاقی می افتد:
from datetime import date prompt = ChatPromptTemplate.from_messages([ ("system", 'You know that the current date is "{current_date}".'), ("human", "{question}") ]) chain = prompt | chat_model | StrOutputParser() chain.invoke({ "question": "What is the current date?", "current_date": date.today() })و می توانید ببینید، مدل تاریخ فعلی را تولید می کند:
"The current date is 2024-04-05."خوب! حالا بیایید یک قدم جلوتر برویم. مدل های زبانی بر روی مقادیر زیادی داده آموزش می بینند، اما همه چیز را نمی دانند. اگر مستقیماً یک سؤال بسیار خاص در مورد یک رستوران محلی از مدل چت بپرسید، چه اتفاقی می افتد:
chat_model.invoke( "What was the Old Ship Saloon's total revenue in Q1 2023?" )مدل به طور بومی پاسخ را نمی داند، یا حتی نمی داند که در مورد کدام یک از بسیاری از سالن های کشتی قدیمی در جهان صحبت می کنیم:
AIMessage(content="I'm sorry, I don't have any specific financial data about the Old Ship Saloon's revenue in Q1 2023. As an AI assistant without access to the saloon's internal records, I don't have information about their future projected revenues. I can only provide responses based on factual information that has been provided to me.")با این حال، اگر بتوانیم به مدل زمینه بیشتری بدهیم، میتوانیم آن را راهنمایی کنیم تا به یک پاسخ خوب برسد:
SOURCE = """ Old Ship Saloon 2023 quarterly revenue numbers: Q1: $174782.38 Q2: $467372.38 Q3: $474773.38 Q4: $389289.23 """ rag_prompt = ChatPromptTemplate.from_messages([ ("system", 'You are a helpful assistant. Use the following context when responding:\n\n{context}.'), ("human", "{question}") ]) rag_chain = rag_prompt | chat_model | StrOutputParser() rag_chain.invoke({ "question": "What was the Old Ship Saloon's total revenue in Q1 2023?", "context": SOURCE }) "According to the provided context, the Old Ship Saloon's revenue in Q1 2023 was $174,782.38."نتیجه به نظر خوب می رسد! توجه داشته باشید که افزایش تولید با زمینه اضافی یک موضوع بسیار عمیق است - در دنیای واقعی، این احتمالاً به شکل یک سند مالی طولانیتر یا بخشی از یک سند بازیابی شده از منبع داده دیگری است. RAG یک تکنیک قدرتمند برای پاسخ دادن به سوالات در مورد مقادیر زیادی از اطلاعات است.
برای کسب اطلاعات بیشتر، میتوانید اسناد نسل گفت ه شده (RAG) LangChain را تحلیل کنید.
اشکال زدایی
از آنجایی که LLM ها غیر قطعی هستند، با پیچیده تر شدن زنجیره های شما، دیدن درونیات آنچه در حال وقوع است، اهمیت بیشتری پیدا می کند.
LangChain یک متد set_debug() دارد که گزارشهای دانهدار بیشتری از داخلیهای زنجیره را برمیگرداند: بیایید آن را با مثال بالا ببینیم:
from langchain.globals import set_debug set_debug(True) from datetime import date prompt = ChatPromptTemplate.from_messages([ ("system", 'You know that the current date is "{current_date}".'), ("human", "{question}") ]) chain = prompt | chat_model | StrOutputParser() chain.invoke({ "question": "What is the current date?", "current_date": date.today() })اطلاعات بسیار بیشتری وجود دارد!
[chain/start] [1:chain:RunnableSequence] Entering Chain run with input: [inputs] [chain/start] [1:chain:RunnableSequence > 2:prompt:ChatPromptTemplate] Entering Prompt run with input: [inputs] [chain/end] [1:chain:RunnableSequence > 2:prompt:ChatPromptTemplate] [1ms] Exiting Prompt run with output: [outputs] [llm/start] [1:chain:RunnableSequence > 3:llm:ChatAnthropic] Entering LLM run with input: { "prompts": [ "System: You know that the current date is \\"2024-04-05\\".\\nHuman: What is the current date?" ] } ... [chain/end] [1:chain:RunnableSequence] [885ms] Exiting Chain run with output: { "output": "The current date you provided is 2024-04-05." }برای اطلاعات بیشتر در مورد اشکال زدایی می توانید این راهنما را ببینید.
همچنین می توانید از متد astream_events() برای برگرداندن این داده ها استفاده کنید. اگر می خواهید از مراحل میانی در منطق برنامه خود استفاده کنید، این کار مفید است. توجه داشته باشید که این یک روش async است و به یک پرچم version اضافی نیاز دارد زیرا هنوز در نسخه بتا است:
# Turn off debug mode for clarity set_debug(False) stream = chain.astream_events({ "question": "What is the current date?", "current_date": date.today() }, version="v1") async for event in stream: print(event) print("-----") {'event': 'on_chain_start', 'run_id': '90785a49-987e-46bf-99ea-d3748d314759', 'name': 'RunnableSequence', 'tags': [], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}}} ----- {'event': 'on_prompt_start', 'name': 'ChatPromptTemplate', 'run_id': '54b1f604-6b2a-48eb-8b4e-c57a66b4c5da', 'tags': ['seq:step:1'], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}}} ----- {'event': 'on_prompt_end', 'name': 'ChatPromptTemplate', 'run_id': '54b1f604-6b2a-48eb-8b4e-c57a66b4c5da', 'tags': ['seq:step:1'], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}, 'output': ChatPromptValue(messages=[SystemMessage(content='You know that the current date is "2024-04-05".'), HumanMessage(content='What is the current date?')])} ----- {'event': 'on_chat_model_start', 'name': 'ChatAnthropic', 'run_id': 'f5caa4c6-1b51-49dd-b304-e9b8e176623a', 'tags': ['seq:step:2'], 'metadata': {}, 'data': {'input': {'messages': [[SystemMessage(content='You know that the current date is "2024-04-05".'), HumanMessage(content='What is the current date?')]]}}} ----- ... {'event': 'on_chain_end', 'name': 'RunnableSequence', 'run_id': '90785a49-987e-46bf-99ea-d3748d314759', 'tags': [], 'metadata': {}, 'data': {'output': 'The current date is 2024-04-05.'}} -----در نهایت، می توانید از یک سرویس خارجی مانند LangSmith برای اضافه کردن ردیابی استفاده کنید. در اینجا یک مثال است:
# Sign up at <https://smith.langchain.com/> # Set environment variables # import os # os.environ["LANGCHAIN_TRACING_V2"] = "true" # os.environ["LANGCHAIN_API_KEY"] = "YOUR_KEY" # os.environ["LANGCHAIN_PROJECT"] = "YOUR_PROJECT" chain.invoke({ "question": "What is the current date?", "current_date": date.today() }) "The current date is 2024-04-05."LangSmith در هر مرحله موارد داخلی را ضبط می کند و نتیجه ای مانند این به شما می دهد.
همچنین میتوانید درخواستها را تغییر دهید و تماسهای مدل را در یک زمین بازی دوباره اجرا کنید. با توجه به ماهیت غیر قطعی LLM ها، شما همچنین می توانید
متشکرم!
شما اکنون اصول اولیه را یاد گرفته اید:
مدل چت LangChain، الگوی درخواست و اجزای تجزیه کننده خروجی
نحوه زنجیر کردن مؤلفه ها با جریان.
استفاده از اطلاعات بیرونی برای هدایت تولید مدل
چگونه قسمت های داخلی زنجیره های خود را اشکال زدایی کنیم.
موارد زیر را برای چند منبع خوب برای ادامه سفر هوش مصنوعی مولد خود تحلیل کنید:
همچنین میتوانید LangChain را در X (توئیتر سابق) @LangChainAI برای آخرین اخبار یا من @Hacubu دنبال کنید.
تشویق مبارک!
برچسبها
|
|



ارسال نظر