نحوه استفاده از هوش مصنوعی برای خودکارسازی تست واحد با TestGen-LLM و Cover-Agent
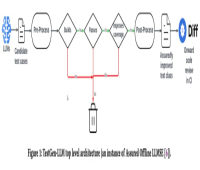
نوشتن تستهای واحد واضح و کارآمد که واقعاً در طول فرآیند توسعه نرمافزار کار میکنند، مهم است. تستهای واحد، عناصر کد را جدا میکنند و تایید میکنند که آنها همانطور که در نظر گرفته شده است کار میکنند.
تستهای واحد مؤثر نه تنها خطاها را تشخیص میدهند، بلکه به شما کمک میکنند مطمئن شوید که کد شما قابل نگهداری است و قابل اعتماد است. اما برای ایجاد دستی مجموعه گسترده ای از تست های واحد نیاز به زمان و منابع است.
برخی از پیشرفتهای اخیر در هوش مصنوعی وجود دارد که به خودکارسازی فرآیندهای توسعه تست واحد کمک میکند. در ماه فوریه، محققان متا مقالهای در مورد بهبود تست واحد خودکار با استفاده از مدلهای زبان بزرگ منتشر کردند. این یک روش نوآورانه برای خودکارسازی تست واحد معرفی کرد.
تحقیقات آنها بر روی ابزار جدیدی به نام TestGen-LLM متمرکز است که امکان استفاده از LLM ها را برای تجزیه و تحلیل تست های واحد موجود و بهبود آنها برای افزایش پوشش کد تحلیل می کند.
اگرچه کد TestGen-LLM منتشر نشد، من در این مقاله یک جایگزین منبع باز با الهام از تحقیقات آنها معرفی خواهم کرد. شما یاد خواهید گرفت که چگونه مجموعه های آزمایشی را تولید می کند، چرا از بسیاری از LLM ها بهتر است، و از کجا می توانید این فناوری را به دست آورید و شروع به آزمایش آن کنید.
فهرست مطالب
پیاده سازی منبع باز (Cover-Agent)
نحوه استفاده از Cover-Agent
چگونه می توانید به این فناوری کمک کنید؟
متا TestGen-LLM
TestGen-LLM متا با استفاده از قدرت مدلهای زبان بزرگ (LLM) با کار وقتگیر نوشتن آزمون واحد مقابله میکند. LLMهای همه منظوره مانند Gemini یا ChatGPT ممکن است با حوزه خاص کد تست واحد، نحو آزمایش، و تولید تست هایی که ارزش اضافه نمی کنند، مشکل داشته باشند. اما TestGen-LLM به طور خاص برای آزمایش واحد طراحی شده است.
این تخصص به آن اجازه میدهد تا پیچیدگیهای ساختار کد و منطق تست را درک کند، که منجر به مجموعههای تست هدفمندتر و تولید تستهایی میشود که در واقع ارزش گفت ه و پوشش کد را افزایش میدهند.
TestGen-LLM قادر به ارزیابی تست های واحد و شناسایی زمینه های بهبود است. این امر از طریق درک الگوهای آزمایش رایج که با آنها آموزش دیده است به دست می آورد. اما تولید آزمایش به تنهایی برای پوشش کد مناسب کافی نیست.
محققان متا برای اطمینان از اثربخشی تستهایی که مینویسد، تدابیر امنیتی را در TestGen-LLM پیادهسازی کردند. این محافظ ها که به آنها filters گفته می شود، به عنوان مکانیزم کنترل کیفیت عمل می کنند. آنها پیشنهاداتی را حذف می کنند که:
کامپایل نمی کند
به طور مداوم شکست بخورد یا
در واقع پوشش کد را بهبود نمیبخشد (پیشنهاداتی که قبلاً توسط آزمایشهای دیگر پوشش داده شدهاند).
TestGen-LLM چگونه کار می کند؟
TestGen-LLM از رویکردی به نام "مهندسی نرم افزار مبتنی بر LLM مطمئن" (Assured LLMSE) استفاده می کند. TestGen-LLM به سادگی یک کلاس آزمایشی موجود را با موارد تست اضافی تقویت می کند، همه موارد تست موجود را حفظ می کند و در نتیجه تضمین می کند که هیچ رگرسیونی وجود نخواهد داشت.

TestGen-LLM مجموعهای از تستها را تولید میکند، سپس تستهایی را که اجرا نمیشوند فیلتر میکند و تستهایی را که موفق نمیشوند حذف میکند. در نهایت، مواردی را که پوشش کد را افزایش نمیدهند کنار میگذارد.
پس از استفاده از TestGen-LLM برای خودکارسازی یک مجموعه آزمایشی، متا از یک بازبین انسانی برای قبول یا رد تستهایی استفاده کرد که در آن تستهای تولید شده در بهترین موارد گزارش شده، ضریب پذیرش 73 درصد داشتند.
طبق این مقاله، TestGen-LLM در هر اجرا یک آزمایش واحد تولید میکند که سپس به مجموعه آزمایشی موجود که قبلاً توسط یک توسعهدهنده نوشته شده بود، اضافه میشود. اما لزوماً تست هایی را برای هر مجموعه آزمایشی ایجاد نمی کند.
اثربخشی TestGen-LLM در تست a-thons داخلی متا نشان داده شد. در اینجا، از این ابزار برای تجزیه و تحلیل مجموعه های آزمایشی موجود و پیشنهاد بهبود استفاده شد. نتایج امیدوارکننده بود:
75% از موارد تست TestGen-LLM به درستی ساخته شدهاند، 57% بهطور قابلاعتماد رد شدهاند و 25% پوشش را افزایش دادهاند. در طول آزمایشهای متا و فیسبوک متا، 11.5 درصد از تمام کلاسهایی را که در آن اعمال شد، بهبود بخشید و 73 درصد از توصیههای آن برای استقرار تولید توسط مهندسان نرمافزار متا پذیرفته شد.»
همچنین، توصیههای TestGen-LLM توسط توسعهدهندگانی که در test-a-thons شرکت کردند، مفید و مرتبط تلقی شدند.
پیاده سازی منبع باز (Cover-Agent)
تحقیقات TestGen-LLM از Meta پتانسیل زیادی برای تغییر تست واحد و تولید تست خودکار دارد. این ابزار احتمالاً به بهبود پوشش کد و سرعت بخشیدن به ایجاد آزمون با استفاده از LLMهایی که مخصوصاً در مورد کد آموزش دیده اند کمک می کند. اما این فناوری برای استفاده برای هر کسی در دسترس نیست، زیرا کد TestGen-LLM منتشر نشده است.
توسعه دهندگانی که به این فناوری علاقه مند شده اند احتمالاً از نبود کد در دسترس عموم ناامید شده اند. از این گذشته، مطالعه TestGen-LLM متا نگاهی اجمالی به آینده از آنچه تست خودکار می تواند باشد ارائه می دهد.
بسیار جذاب است که بتوانیم در عملکردهای داخلی جدیدترین فناوری غوطه ور شویم، رویه های تصمیم گیری آن را درک کنیم و شاید حتی به شکل گیری تکامل آن کمک کنیم. اما در حالی که عدم وجود کد متا یک مانع است، یک پیاده سازی منبع باز به نام Cover-Agent وجود دارد که می تواند به عنوان یک جایگزین مفید عمل کند.
CodiumAI's Cover-Agent اولین پیادهسازی منبع باز ابزار تست خودکار مبتنی بر TestGen-LLM است. با الهام از تحقیقات متا، Cover-Agent اکنون در خط مقدم پیشرفتها در آزمایش واحد مبتنی بر هوش مصنوعی منبع باز قرار دارد.
چرا LLM های متمرکز بر تست خاص ضروری هستند؟
از آنجایی که اکثر LLM ها (مانند ChatGPT و Gemini) قادر به تولید آزمایش هستند، پس چرا با یک فناوری جدید زحمت بکشیم؟
خب، Cover-Agent و TestGen-LLM ایجاد شدند تا گام بعدی در تکامل تست واحد کارآمد باشند. هدف آنها اجتناب از مشکلات رایجی است که توسعه دهندگان هنگام ایجاد آزمایش با LLM ها مانند:
توهم LLM
تولید تست هایی که ارزش گفت ه ای ندارند
تولید تست هایی که برخی از قسمت های کد را حذف می کند و در نتیجه پوشش کد پایینی دارد
برای غلبه بر چنین چالشهایی (مخصوصاً برای آزمونهای واحد رگرسیون)، محققان TestGen-LLM معیارهای زیر را ارائه کردند که آزمونهای تولید شده قبل از پذیرش آزمون باید آنها را رعایت کنند:
آیا تست تولید شده به درستی کامپایل و اجرا می شود؟
آیا آزمون پوشش کد را افزایش می دهد؟
آیا ارزش گفت ه دارد؟
آیا نیازهای اضافی را که ممکن است داشته باشیم برآورده می کند؟
اینها سؤالات و مسائل اساسی هستند که آزمون ایجاد شده باید قبل از ارتقای فناوری موجود آن را حل کند. Cover-Agent تست هایی را ارائه می دهد که به این سؤالات به طور شگفت انگیزی پاسخ می دهد.
Cover-Agent چگونه کار می کند؟
Cover-Agent بخشی از مجموعه گستردهتری از ابزارهای کمکی است که برای خودکارسازی ایجاد تستهای واحد برای پروژههای نرمافزاری طراحی شدهاند. با استفاده از مدل AI Generative TestGen-LLM، هدف آن سادهسازی و تسریع فرآیند آزمایش و تضمین توسعه نرمافزار با کیفیت بالا است.
این سیستم از چندین جزء تشکیل شده است:
Test Runner : دستور یا اسکریپت ها را برای اجرای مجموعه آزمایشی و تولید گزارش های پوشش کد اجرا می کند.
Coverage Parser: تأیید میکند که پوشش کد با اضافه شدن تستها افزایش مییابد و اطمینان حاصل میکند که تستهای جدید به اثربخشی کلی آزمون کمک میکنند.
Prompt Builder: دادههای لازم را از پایگاه کد جمعآوری میکند و درخواست ارسال به مدل زبان بزرگ (LLM) را میسازد.
تماسگیرنده هوش مصنوعی: با LLM تعامل میکند تا آزمایشهایی را بر اساس درخواست ارائه شده ایجاد کند.
این مؤلفهها با TestGen-LLM کار میکنند تا تنها آزمایشهایی را تولید کنند که تضمینشده برای بهبود پایه کد موجود هستند.
نحوه استفاده از Cover-Agent
الزامات
قبل از شروع استفاده از Cover-Agent باید شرایط زیر را داشته باشید:
OPENAI_API_KEY در متغیرهای محیطی شما تنظیم شده است که برای فراخوانی OpenAI API لازم است.
ابزار پوشش کد: گزارش پوشش کد Cobertura XML برای عملکرد صحیح ابزار مورد نیاز است. به عنوان مثال، در پایتون می توانید از pytest-cov. هنگام اجرای Pytest گزینه --cov-report=xml را اضافه کنید.
نصب و راه اندازی
اگر Cover-Agent را مستقیماً از مخزن اجرا می کنید، به موارد زیر نیز نیاز دارید:
پایتون روی سیستم شما نصب شده است.
شعر نصب شده برای مدیریت وابستگی های بسته پایتون. می توانید دستورالعمل نصب شعر را در اینجا بیابید.
زمان اجرا مستقل
می توانید Cover-Agent را به عنوان یک بسته پایتون پیپ نصب کنید یا آن را به عنوان یک فایل اجرایی مستقل اجرا کنید.
پایتون پیپ
برای نصب مستقیم بسته Python Pip از طریق GitHub، دستور زیر را اجرا کنید:
pip install git+https://github.com/Codium-ai/cover-agent.gitدودویی
میتوانید باینری را بدون هیچ گونه محیط پایتون نصب شده روی سیستم خود اجرا کنید (به عنوان مثال، در یک ظرف Docker که حاوی پایتون نیست). با رفتن به صفحه انتشار پروژه می توانید نسخه را برای سیستم خود دانلود کنید.
راه اندازی مخزن
برای نصب تمام وابستگی ها و اجرای پروژه از منبع، دستور زیر را اجرا کنید:
poetry installاجرای کد
پس از دانلود فایل اجرایی یا نصب بسته Pip، اکنون می توانید Cover-Agent را برای تولید و اعتبارسنجی تست های واحد اجرا کنید.
با استفاده از دستور زیر آن را از خط فرمان اجرا کنید:
cover-agent \ --source-file-path "path_to_source_file" \ --test-file-path "path_to_test_file" \ --code-coverage-report-path "path_to_coverage_report.xml" \ --test-command "test_command_to_run" \ --test-command-dir "directory_to_run_test_command/" \ --coverage-type "type_of_coverage_report" \ --desired-coverage "desired_coverage_between_0_and_100" \ --max-iterations "max_number_of_llm_iterations" \ --included-files "<optional_list_of_files_to_include>"می توانید از پروژه های نمونه در این مخزن برای اجرای این کد به عنوان آزمایش استفاده کنید.
آرگومان های فرمان
source-file-path: مسیر فایل حاوی توابع یا بلوک کدی که قصد داریم برای آن تست کنیم.
test-file-path: مسیر فایلی که در آن تست ها توسط نماینده نوشته می شود. بهتر است یک اسکلت از این فایل با حداقل یک تست و دستورات import لازم ایجاد کنید.
code-coverage-report-path: مسیری که گزارش پوشش کد در آن ذخیره می شود.
test-command: دستور اجرای تست ها (به عنوان مثال pytest).
test-command-dir : دایرکتوری که دستور تست باید در آن اجرا شود. برای جلوگیری از مشکلات مربوط به واردات نسبی، آن را روی ریشه یا محل فایل اصلی خود تنظیم کنید.
coverage-type: نوع پوشش مورد استفاده. Cobertura پیش فرض خوبی است.
مطلوب-پوشش: هدف پوشش. بالاتر بهتر است، اگرچه 100٪ اغلب غیرعملی است.
max-iterations: تعداد دفعاتی که عامل باید دوباره برای تولید کد آزمایشی تلاش کند. تکرارهای بیشتر ممکن است منجر به استفاده بالاتر از توکن OpenAI شود.
اضافی-دستورالعملها: از نوشته شدن کد به روشی خاص درخواست میکند. به عنوان مثال، در اینجا مشخص می کنیم که کد باید برای کار در یک کلاس آزمایشی فرمت شود.
با اجرای دستور، عامل شروع به نوشتن و تکرار روی تست ها می کند.
نحوه استفاده از Cover-Agent
وقت آن است که Cover-Agent را آزمایش کنید. ما از یک برنامه ساده calculator.py برای مقایسه پوشش کد برای آزمایش دستی و خودکار استفاده خواهیم کرد.
تست دستی
def add(a, b): return a + b def subtract(a, b): return a - b def multiply(a, b): return a * b def divide(a, b): if b == 0: raise ValueError("Cannot divide by zero") return a / bاین test_calculator.py است که در پوشه تست قرار داده شده است.
# tests/test_calculator.py from calculator import add, subtract, multiply, divide class TestCalculator: def test_add(self): assert add(2, 3) == 5 برای مشاهده پوشش آزمایشی، باید pytest-cov را نصب کنیم، یک پسوند pytest برای گزارش پوشش که قبلا ذکر شد.
pip install pytest-covتجزیه و تحلیل پوشش را با استفاده از:
pytest --cov=calculatorخروجی نشان می دهد:
Name Stmts Miss Cover ----------------------------------- calculator.py 10 5 50% ----------------------------------- TOTAL 10 5 50%خروجی بالا نشان میدهد که 5 مورد از 10 عبارت موجود در calculator.py اجرا نمیشوند و در نتیجه فقط 50 درصد پوشش کد ایجاد میشود. برای یک پایگاه کد بزرگتر، این به یک مسئله جدی تبدیل می شود و منجر به شکست می شود.
حالا بیایید ببینیم که آیا Cover-agent می تواند بهتر عمل کند یا خیر.
تست خودکار با Cover-Agent
برای راه اندازی Codium's Cover-Agent، این مراحل را دنبال کنید:
ابتدا Cover-Agent را نصب کنید:
pip install git+https://github.com/Codium-ai/cover-agent.gitمطمئن شوید که OPENAI_API_KEY شما در متغیرهای محیطی تنظیم شده است، زیرا برای OpenAI API لازم است.
بعد، دستورات را برای شروع تولید آزمایش در ترمینال بنویسید:
cover-agent \ --source-file-path "calculator.py" \ --test-file-path "tests/test_calculator.py" \ --code-coverage-report-path "coverage.xml" \ --test-command "pytest --cov=. --cov-report=xml --cov-report=term" \ --test-command-dir "./" \ --coverage-type "cobertura" \ --desired-coverage 80 \ --max-iterations 3 \ --openai-model "gpt-4o" \ --additional-instructions "Since I am using a test class, each line of code (including the first line) needs to be prepended with 4 whitespaces. This is extremely important to ensure that every line returned contains that 4 whitespace indent; otherwise, my code will not run." import pytest from calculator import add, subtract, multiply, divide class TestCalculator: def test_add(self): assert(add(2, 3), 5 def test_subtract(self): """ Test subtracting two numbers. """ assert subtract(5, 3) == 2 assert subtract(3, 5) == -2 def test_multiply(self): """ Test multiplying two numbers. """ assert multiply(2, 3) == 6 assert multiply(-2, 3) == -6 assert multiply(2, -3) == -6 assert multiply(-2, -3) == 6 def test_divide(self): """ Test dividing two numbers. """ assert divide(6, 3) == 2 assert divide(-6, 3) == -2 assert divide(6, -3) == -2 assert divide(-6, -3) == 2 def test_divide_by_zero(self): """ Test dividing by zero, should raise ValueError. """ with pytest.raises(ValueError, match="Cannot divide by zero"): divide(5, 0)می بینید که عامل همچنین تست هایی را نوشته است که خطاها را برای موارد لبه تحلیل می کند.
اکنون زمان آن است که دوباره پوشش را آزمایش کنیم:
pytest --cov=calculatorخروجی:
Name Stmts Miss Cover ----------------------------------- calculator.py 10 0 100% ----------------------------------- TOTAL 10 0 100%در این مثال به پوشش کد 100% رسیدیم. برای پایه های کد بزرگتر، روش نسبتاً یکسان است. میتوانید این راهنما را برای تحلیل یک پایه کد بزرگتر بخوانید.
در حالی که Cover-Agent یک گام مهم رو به جلو است، مهم است که توجه داشته باشیم که این فناوری هنوز در مراحل اولیه خود است. ادامه تحقیق و توسعه برای اصلاح بیشتر و پذیرش گستردهتر بسیار مهم است و codiumAI از شما دعوت میکند تا در این ابزار منبع باز مشارکت کنید.
مزایای عامل پوشش منبع باز
ماهیت منبع باز Cover-Agent چندین مزیت را ارائه می دهد که باید به پیشبرد فناوری کمک کند. از جمله آنها عبارتند از:
دسترسپذیری: ماهیت منبع باز آن آزمایشهای آزمایشی مبتنی بر LLM را امکانپذیر میسازد و برای توسعهدهندگان با زمینههای مختلف قابل دسترسی است، این باعث افزایش تعداد کاربران و توسعه فناوری بهتر و برنامههای کاربردی بیشتر میشود.
همکاری: توسعه دهندگان می توانند مشارکت داشته باشند، پیشرفت ها را پیشنهاد دهند، ویژگی های جدید را پیشنهاد کنند و مشکلات را گزارش کنند. Cover-Agent به سرعت رشد می کند و به پروژه ای عالی برای توسعه دهندگان تبدیل می شود.
شفافیت: اطلاعات مربوط به عملیات داخلی در دسترس است و این باعث افزایش اعتماد می شود و در نهایت پتانسیل فناوری را افزایش می دهد.
علاوه بر مزایای منبع باز، Cover-Agent مجموعه ای قوی از مزایای خاص خود را در اختیار توسعه دهندگان قرار می دهد:
دسترسی ساده: توسعه دهندگان می توانند به راحتی تست های مبتنی بر LLM را نصب و آزمایش کنند. این امکان کاوش مستقیم و فوری قابلیتهای این فناوری را فراهم میکند و بدون ایجاد اختلال در روند کاری آنها.
سفارشی سازی برای نیازهای خاص: ماهیت منبع باز Cover-Agent به توسعه دهندگان اجازه می دهد تا ابزار را با نیازهای پروژه خاص خود تطبیق دهند. این می تواند شامل اصلاح مدل LLM مورد استفاده، تنظیم داده های آموزشی برای انعکاس بهتر پایگاه کد آنها یا ادغام Cover-Agent با چارچوب های آزمایشی موجود باشد. این سطح سفارشیسازی به توسعهدهندگان این امکان را میدهد تا از قدرت آزمایش مبتنی بر LLM به نحوی استفاده کنند که با نیازهای پروژهشان هماهنگ باشد.
ادغام آسان: به راحتی با VSCode (یک ویرایشگر کد محبوب) ادغام می شود که ادغام با جریان های کاری موجود را آسان می کند. همچنین می توانید به راحتی آن را با تست های کتبی انسانی موجود ادغام کنید.
چگونه می توانید به Cover-Agent کمک کنید؟
کد منبع Cover-Agent از طریق این مخزن GitHub به صورت عمومی در دسترس است. آنها توسعه دهندگان را با هر زمینه ای تشویق می کنند تا محصول خود را آزمایش کنند و برای بهبود و رشد بیشتر این فناوری جدید مشارکت کنند.
نتیجه
ابزارهای بهبود تست مبتنی بر LLM پتانسیل بسیار زیادی برای ایجاد انقلابی در رویکرد توسعه دهندگان به تست واحد دارند. این ابزارها با استفاده از قدرت مدل های زبان بزرگ که به طور خاص بر روی کد آموزش داده شده اند، می توانند ایجاد تست را ساده کنند، پوشش کد را بهبود بخشند و در نهایت کیفیت نرم افزار را افزایش دهند.
در حالی که تحقیقات متا با TestGen-LLM بینش های ارزشمندی را ارائه می دهد، فقدان کد در دسترس عموم مانع پذیرش گسترده تر و توسعه مداوم می شود. خوشبختانه، Cover-Agent یک راه حل به راحتی در دسترس و قابل تنظیم ارائه کرده است. این به توسعه دهندگان این امکان را می دهد تا آزمایش های مبتنی بر LLM را آزمایش کنند و در تکامل آن سهیم باشند.
پتانسیل TestGen-LLM و Cover-Agent بسیار زیاد است و توسعه بیشتر از طریق مشارکت های توسعه دهندگان منجر به ابزاری انقلابی می شود که نسل آزمایش خودکار را برای همیشه متحول می کند.
وبلاگ Cover-Agent برای مطالعه بیشتر
مقاله برای مراحل نصب و موارد استفاده
اگر این را مفید یافتید، در لینکدین و توییتر با من در ارتباط باشید.
برچسبها
|
|




ارسال نظر