موتور جستجوی مبتنی بر هوش مصنوعی با پایگاه داده برداری Milvus در Vultr

پایگاه داده های برداری معمولاً برای ذخیره جاسازی های برداری برای کارهایی مانند جستجوی شباهت برای ایجاد سیستم های توصیه و پاسخ به سؤال استفاده می شود. Milvus یکی از پایگاههای داده منبع باز است که جاسازیها را به شکل دادههای برداری ذخیره میکند، زیرا دارای آپشن های نمایهسازی مانند نزدیکترین همسایهها (ANN) است که نتایج سریع و دقیق را ممکن میسازد.
در این مقاله، مراحل نحوه استفاده از مجموعه داده HuggingFace، ایجاد جاسازی از مجموعه داده، و تقسیم مجموعه داده به دو نیمه (تست و آموزش) را نشان خواهیم داد. همچنین یاد خواهید گرفت که چگونه با ایجاد یک مجموعه، همه جاسازی های ایجاد شده را در پایگاه داده Milvus مستقر ذخیره کنید، سپس با دادن یک سوال و ایجاد مشابه ترین پاسخ ها، عملیات جستجو را انجام دهید.
استقرار سرور در Vultr
ثبت نام کنید و وارد پورتال مشتریان Vultr شوید.
به صفحه محصولات بروید.
از منوی کناری، Compute را انتخاب کنید. 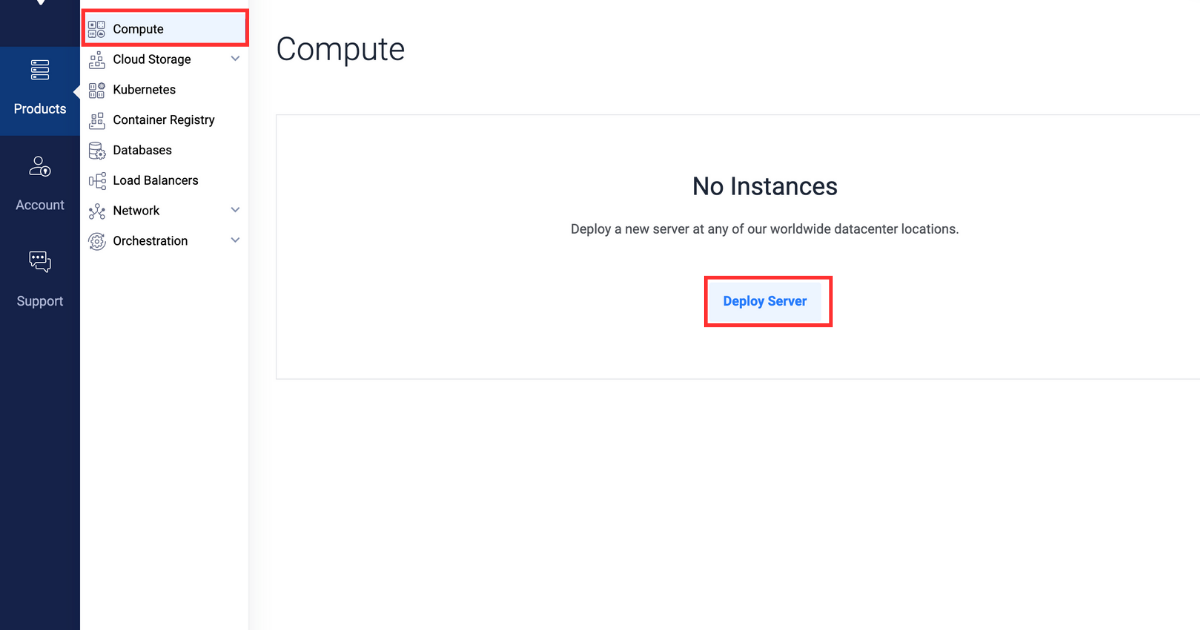
روی دکمه Deploy Server در مرکز کلیک کنید.
Cloud GPU را به عنوان نوع سرور انتخاب کنید.
A100 را به عنوان نوع GPU انتخاب کنید.
در بخش "موقعیت سرور" منطقه مورد نظر خود را انتخاب کنید.
در بخش «سیستم عامل»، Vultr GPU Stack را به عنوان سیستم عامل انتخاب کنید. 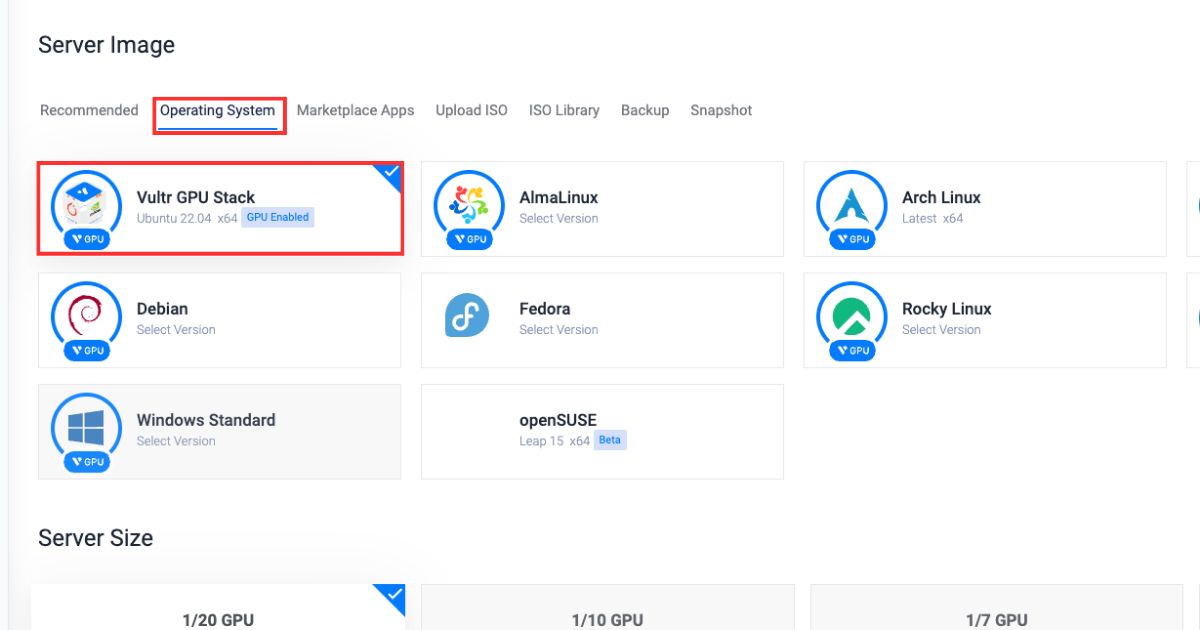 Vultr GPU Stack برای سادهسازی فرآیند ساخت پروژههای هوش مصنوعی (AI) و یادگیری ماشین (ML) با ارائه مجموعهای از نرمافزارهای از پیش نصبشده از جمله NVIDIA CUDA Toolkit، NVIDIA cuDNN، TensorFlow، PyTorch و غیره طراحی شده است.
Vultr GPU Stack برای سادهسازی فرآیند ساخت پروژههای هوش مصنوعی (AI) و یادگیری ماشین (ML) با ارائه مجموعهای از نرمافزارهای از پیش نصبشده از جمله NVIDIA CUDA Toolkit، NVIDIA cuDNN، TensorFlow، PyTorch و غیره طراحی شده است.
در قسمت “Server Size” گزینه 80 GB را انتخاب کنید.
در بخش « آپشن های اضافی» هر ویژگی دیگری را که لازم است انتخاب کنید.
روی دکمه Deploy Now در گوشه سمت راست پایین کلیک کنید.
به صفحه محصولات بروید.
از منوی کناری، Kubernetes را انتخاب کنید.
روی دکمه Add Cluster در مرکز کلیک کنید.
نام خوشه ای را تایپ کنید.
در بخش "Cluster Location" منطقه مورد نظر خود را انتخاب کنید.
یک برچسب برای مجموعه کلاستر تایپ کنید.
تعداد گره ها را به 5 افزایش دهید.
روی دکمه Deploy Now در گوشه سمت راست پایین کلیک کنید.
آماده سازی سرور
نصب پکیج های مورد نیاز
پس از راهاندازی یک سرور Vultr و یک خوشه Vultr Kubernetes همانطور که قبلاً توضیح داده شد، این بخش شما را از طریق نصب بستههای وابستگی پایتون لازم برای ساخت پایگاه داده Milvus و وارد کردن ماژولهای لازم در کنسول پایتون راهنمایی میکند.
وابستگی های مورد نیاز را نصب کنید
pip install transformers datasets pymilvus torchدر اینجا چیزی است که هر بسته نشان می دهد:
transformers : دسترسی را فراهم می کند و اجازه می دهد تا با مدل های LLM از پیش آموزش دیده برای کارهایی مانند طبقه بندی و تولید متن کار کنید.
datasets : دسترسی را فراهم می کند و اجازه می دهد تا روی مجموعه داده های آماده برای استفاده برای وظایف NLP کار کنید.
pymilvus : کلاینت پایتون برای Milvus که امکان جستجوی شباهت برداری، ذخیره سازی و مدیریت مجموعه های بزرگی از بردارها را فراهم می کند.
torch : کتابخانه یادگیری ماشینی که برای آموزش و ساخت مدل های یادگیری عمیق استفاده می شود.
به کنسول پایتون دسترسی پیدا کنید
python3ماژول های مورد نیاز را وارد کنید
from pymilvus import connections , FieldSchema , CollectionSchema , DataType , Collection , utility from datasets import load_dataset_builder , load_dataset , Dataset from transformers import AutoTokenizer , AutoModel from torch import clamp , sumدر اینجا چیزی است که هر بسته نشان می دهد:
ماژول های pymilvus :
connections : عملکردهایی را برای مدیریت ارتباطات با پایگاه داده Milvus ارائه می دهد.
FieldSchema : طرح واره فیلدها را در پایگاه داده Milvus تعریف می کند.
CollectionSchema : طرح واره مجموعه را تعریف می کند.
DataType : انواع داده ای را که می توان در مجموعه Milvus استفاده کرد را برمی شمارد.
Collection : قابلیت تعامل با مجموعه های Milvus را برای ایجاد، درج و جستجوی بردارها فراهم می کند.
utility : توابع پیش پردازش داده و بهینه سازی پرس و جو را برای کار با Milvus فراهم می کند
ماژول های datasets :
load_dataset_builder : شیء مجموعه داده را برای دسترسی به اطلاعات پایگاه داده و ابرداده آن بارگیری و برمی گرداند.
load_dataset : یک مجموعه داده را از سازنده مجموعه داده بارگیری می کند و شی مجموعه داده را برای دسترسی به داده برمی گرداند.
Dataset : یک مجموعه داده را نشان می دهد که دسترسی به عملیات مربوط به داده را فراهم می کند.
ماژول های transformers :
AutoTokenizer : مدل های توکن سازی از قبل آموزش دیده را برای وظایف NLP بارگیری می کند.
AutoModel : یک کلاس بارگذاری مدل برای بارگیری خودکار مدل های از پیش آموزش دیده برای وظایف NLP است.
ماژول های torch :
clamp : توابعی را برای محدود کردن مقادیر تانسور از نظر عنصر ارائه می دهد.
sum : مجموع عناصر تانسور را در ابعاد مشخص محاسبه می کند.
ساخت یک معماری پرسش و پاسخ
در این بخش، نحوه ایجاد یک مجموعه، درج داده ها در مجموعه و انجام عملیات جستجو را با ارائه یک ورودی در قالب پرسش و پاسخ خواهید آموخت.
پارامترها را اعلام کنید، مطمئن شوید که EXTERNAL_IP_ADDRESS با مقدار واقعی جایگزین کنید.
DATASET = 'squad' MODEL = 'bert-base-uncased' TOKENIZATION_BATCH_SIZE = 1000 INFERENCE_BATCH_SIZE = 64 INSERT_RATIO = .001 COLLECTION_NAME = 'huggingface_db' DIMENSION = 768 LIMIT = 10 MILVUS_HOST = "EXTERNAL_IP_ADDRESS" MILVUS_PORT = "19530"در اینجا چیزی است که هر پارامتر نشان می دهد:
DATASET : مجموعه داده Huggingface را برای استفاده برای جستجوی پاسخ ها تعریف می کند.
MODEL : ترانسفورماتور مورد استفاده برای ایجاد تعبیه ها را تعریف می کند.
TOKENIZATION_BATCH_SIZE : تعیین می کند که چند متن به طور همزمان در طول توکن سازی پردازش می شوند و با استفاده از موازی سازی به افزایش سرعت توکن سازی کمک می کند.
INFERENCE_BATCH_SIZE : اندازه دسته را برای پیشبینیها تنظیم میکند که بر کارایی وظایف طبقهبندی متن تأثیر میگذارد. هنگام استفاده از یک GPU کوچکتر، می توانید اندازه دسته را به 32 یا 18 کاهش دهید.
INSERT_RATIO : بخشی از داده های متنی را که باید به جاسازی تبدیل شوند را کنترل می کند و حجم داده هایی را که قرار است نمایه شوند برای انجام جستجوی برداری مدیریت می کند.
COLLECTION_NAME : نام مجموعه ای را که می خواهید ایجاد کنید تنظیم می کند.
DIMENSION : اندازه جاسازی فردی را که قرار است در مجموعه ذخیره کنید، تنظیم می کند.
LIMIT : تعداد نتایجی را برای جستجو و نمایش در خروجی تنظیم می کند.
MILVUS_HOST : IP خارجی را برای دسترسی به پایگاه داده مستقر شده Milvus تنظیم می کند.
MILVUS_PORT : پورتی را که پایگاه داده Milvus مستقر شده در آن قرار می گیرد را تنظیم می کند.
با استفاده از آدرس IP خارجی و درگاهی که Milvus روی آن قرار دارد، به پایگاه داده خارجی Milvus که مستقر کرده اید، متصل شوید. مطمئن شوید که مقادیر فیلد user و password را با مقادیر مناسب جایگزین کنید. اگر برای اولین بار به پایگاه داده دسترسی دارید، user = root و password = Milvus.
connections . connect ( host = "MILVUS_HOST" , port = "MILVUS_PORT" , user = "USER" , password = "PASSWORD" )ایجاد یک مجموعه
در این بخش، نحوه ایجاد یک مجموعه و تعریف طرحواره آن برای ذخیره سازی مناسب محتوا از مجموعه داده را خواهید آموخت. همچنین نحوه ایجاد نمایه ها و بارگذاری مجموعه را یاد خواهید گرفت.
وجود مجموعه را تحلیل کنید، اگر مجموعه موجود باشد، برای جلوگیری از هرگونه درگیری حذف می شود.
if utility . has_collection ( COLLECTION_NAME ) : utility . drop_collection ( COLLECTION_NAME ) مجموعه ای به نام huggingface_db ایجاد کنید و طرح کلکسیون را تعریف کنید.
fields = [ FieldSchema ( name = 'id' , dtype = DataType . INT64 , is_primary = True , auto_id = True ) , FieldSchema ( name = 'original_question' , dtype = DataType . VARCHAR , max_length = 1000 ) , FieldSchema ( name = 'answer' , dtype = DataType . VARCHAR , max_length = 1000 ) , FieldSchema ( name = 'original_question_embedding' , dtype = DataType . FLOAT_VECTOR , dim = DIMENSION ) ] schema = CollectionSchema ( fields = fields ) collection = Collection ( name = COLLECTION_NAME , schema = schema )فیلدهای زیر برای تعریف طرح واره مجموعه استفاده می شود:
id : فیلد اصلی که تمام ورودی های پایگاه داده باید از آن شناسایی شوند.
original_question : فیلدی است که سوال اصلی در آن ذخیره می شود و قرار است سوالی که پرسیده اید مطابقت داده شود.
answer : فیلدی است که پاسخ هر original_quesition را در خود جای داده است.
original_question_embedding : شامل جاسازیهایی برای هر ورودی در original_question برای انجام جستجوی شباهت با سؤالی که به عنوان ورودی دادهاید.
برای انجام جستجوی شباهت، یک فهرست برای فیلد original_question_embedding ایجاد کنید.
index_params = { 'metric_type' : 'L2' , 'index_type' : "IVF_FLAT" , 'params' : { "nlist" : 1536 } } collection . create_index ( field_name = "original_question_embedding" , index_params = index_params )پس از ایجاد موفقیت آمیز ایندکس فیلد مشخص شده، خروجی زیر نمایش داده می شود:
Status(code=0, message=)مجموعه را بارگیری کنید تا مطمئن شوید که مجموعه برای انجام عملیات جستجو آماده است.
collection . load ( )درج داده ها در مجموعه
در این بخش، شما یاد خواهید گرفت که چگونه مجموعه داده را به مجموعهها تقسیم کنید، تمام سوالات موجود در مجموعه داده را نشانهگذاری کنید، جاسازیهایی ایجاد کنید و آنها را در مجموعه قرار دهید.
مجموعه داده را بارگیری کنید، مجموعه داده را به مجموعه های آموزشی و آزمایشی تقسیم کنید و مجموعه آزمایشی را پردازش کنید تا هر ستون دیگری به جز متن پاسخ حذف شود.
data_dataset = load_dataset ( DATASET , split = 'all' ) data_dataset = data_dataset . train_test_split ( test_size = INSERT_RATIO , seed = 42 ) [ 'test' ] data_dataset = data_dataset . map ( lambda val : { 'answer' : val [ 'answers' ] [ 'text' ] [ 0 ] } , remove_columns = [ 'answers' ] )توکنایزر را راه اندازی کنید.
tokenizer = AutoTokenizer . from_pretrained ( MODEL )تابعی را برای توکن کردن سوالات تعریف کنید.
def tokenize_question ( batch ) : results = tokenizer ( batch [ 'question' ] , add_special_tokens = True , truncation = True , padding = "max_length" , return_attention_mask = True , return_tensors = "pt" ) batch [ 'input_ids' ] = results [ 'input_ids' ] batch [ 'token_type_ids' ] = results [ 'token_type_ids' ] batch [ 'attention_mask' ] = results [ 'attention_mask' ] return batch هر ورودی سؤال را با استفاده از تابع tokenize_question که قبلاً تعریف شده بود، توکن کنید و خروجی را به فرمت سازگار با torch برای مدلهای یادگیری ماشین مبتنی بر PyTorch تنظیم کنید.
data_dataset = data_dataset . map ( tokenize_question , batch_size = TOKENIZATION_BATCH_SIZE , batched = True ) data_dataset . set_format ( 'torch' , columns = [ 'input_ids' , 'token_type_ids' , 'attention_mask' ] , output_all_columns = True ) مدل از پیش آموزش دیده را بارگیری کنید، سوالات توکن شده را ارسال کنید، جاسازی ها را از سوالات ایجاد کنید و آنها را به عنوان question_embeddings در مجموعه داده قرار دهید.
model = AutoModel . from_pretrained ( MODEL ) def embed ( batch ) : sentence_embs = model ( input_ids = batch [ 'input_ids' ] , token_type_ids = batch [ 'token_type_ids' ] , attention_mask = batch [ 'attention_mask' ] ) [ 0 ] input_mask_expanded = batch [ 'attention_mask' ] . unsqueeze ( - 1 ) . expand ( sentence_embs . size ( ) ) . float ( ) batch [ 'question_embedding' ] = sum ( sentence_embs * input_mask_expanded , 1 ) / clamp ( input_mask_expanded . sum ( 1 ) , min = 1e - 9 ) return batch data_dataset = data_dataset . map ( embed , remove_columns = [ 'input_ids' , 'token_type_ids' , 'attention_mask' ] , batched = True , batch_size = INFERENCE_BATCH_SIZE )سوالات را در مجموعه درج کنید.
def insert_function ( batch ) : insertable = [ batch [ 'question' ] , [ x [ : 995 ] + '...' if len ( x ) > 999 else x for x in batch [ 'answer' ] ] , batch [ 'question_embedding' ] . tolist ( ) ] collection . insert ( insertable ) data_dataset . map ( insert_function , batched = True , batch_size = 64 ) collection . flush ( ) Dataset({ features: ['id', 'title', 'context', 'question', 'answer', 'input_ids', 'token_type_ids', 'attention_mask', 'question_embedding'], num_rows: 99 })ایجاد پاسخ
در این بخش، یاد خواهید گرفت که چگونه یک درخواست ارائه دهید، آن را نشانه گذاری و جاسازی کنید تا جستجوی مشابهی را انجام دهید و مرتبط ترین پاسخ ها را ایجاد کنید.
یک مجموعه داده سریع ایجاد کنید، می توانید سؤال را با هر درخواست سفارشی جایگزین کنید و همچنین می توانید تعداد سؤالات هر درخواست را جایگزین کنید.
questions = { 'question' : [ 'When was maths invented?' ] } question_dataset = Dataset . from_dict ( questions )دستور را نشانه گذاری و جاسازی کنید.
question_dataset = question_dataset . map ( tokenize_question , batched = True , batch_size = TOKENIZATION_BATCH_SIZE ) question_dataset . set_format ( 'torch' , columns = [ 'input_ids' , 'token_type_ids' , 'attention_mask' ] , output_all_columns = True ) question_dataset = question_dataset . map ( embed , remove_columns = [ 'input_ids' , 'token_type_ids' , 'attention_mask' ] , batched = True , batch_size = INFERENCE_BATCH_SIZE ) تابع search را تعریف کنید که عملیات جستجو را با استفاده از جاسازی های ایجاد شده قبلی انجام می دهد. اطلاعات بازیابی شده در فهرست ها سازماندهی شده و به عنوان فرهنگ لغت برگردانده می شود.
def search ( batch ) : res = collection . search ( batch [ 'question_embedding' ] . tolist ( ) , anns_field = 'original_question_embedding' , param = { } , output_fields = [ 'answer' , 'original_question' ] , limit = LIMIT ) overall_id = [ ] overall_distance = [ ] overall_answer = [ ] overall_original_question = [ ] for hits in res : ids = [ ] distance = [ ] answer = [ ] original_question = [ ] for hit in hits : ids . append ( hit . id ) distance . append ( hit . distance ) answer . append ( hit . entity . get ( 'answer' ) ) original_question . append ( hit . entity . get ( 'original_question' ) ) overall_id . append ( ids ) overall_distance . append ( distance ) overall_answer . append ( answer ) overall_original_question . append ( original_question ) return { 'id' : overall_id , 'distance' : overall_distance , 'answer' : overall_answer , 'original_question' : overall_original_question } عملیات جستجو را با اعمال تابع search تعریف شده قبلی در question_dataset انجام دهید.
question_dataset = question_dataset . map ( search , batched = True , batch_size = 1 ) for x in question_dataset : print ( ) print ( 'Question:' ) print ( x [ 'question' ] ) print ( 'Answer, Distance, Original Question' ) for x in zip ( x [ 'answer' ] , x [ 'distance' ] , x [ 'original_question' ] ) : print ( x ) Question : When was maths invented? Answer , Distance , Original Question ( 'until 1870' , tensor ( 33.3018 ) , 'When did the Papal States exist?' ) ( 'October 1992' , tensor ( 34.8276 ) , 'When were free elections held?' ) ( '1787' , tensor ( 36.0596 ) , 'When was the Tower constructed?' ) ( 'Poland, Bulgaria, the Czech Republic, Slovakia, Hungary, Albania, former East Germany and Cuba' , tensor ( 38.3254 ) , 'Where was Russian schooling mandatory in the 20th century?' ) ( '6,000 years' , tensor ( 41.9444 ) , 'How old did biblical scholars think the Earth was?' ) ( '1992' , tensor ( 42.2079 ) , 'In what year was the Premier League created?' ) ( '1981' , tensor ( 44.7781 ) , "When was ZE's Mutant Disco released?" ) ( 'Medieval Latin' , tensor ( 46.9699 ) , "What was the Latin of Charlemagne's era later known as?" ) ( 'taxation' , tensor ( 49.2372 ) , 'How did Hobson argue to rid the world of imperialism?' ) ( 'light weight, relative unbreakability and low surface noise' , tensor ( 49.5037 ) , "What were advantages of vinyl in the 1930's?" )در خروجی بالا، نزدیکترین 10 پاسخ به ترتیب نزولی برای سؤالی که پرسیده اید همراه با سؤالات اصلی که آن پاسخ ها به آنها تعلق دارند چاپ می شود، خروجی نیز مقادیر تانسور را با هر پاسخ نشان می دهد، مقدار تانسور کمتر به این معنی است که پاسخ دقیق تر است. برای سوالی که پرسیدی
نتیجه
در این مقاله یاد گرفتید که چگونه با استفاده از مجموعه داده HuggingFace و پایگاه داده Milvus یک سیستم پاسخگویی به سوال بسازید. این آموزش شما را از طریق مراحل ایجاد جاسازی از یک مجموعه داده، ذخیره آنها در یک مجموعه و سپس انجام جستجوی شباهت برای یافتن بهترین پاسخ های مناسب برای درخواست با ایجاد جاسازی سؤال ارائه شده و محاسبه تانسورها راهنمایی می کند.
این یک مقاله حمایت شده توسط Vultr است. Vultr بزرگترین پلتفرم محاسبات ابری خصوصی در جهان است. Vultr که مورد علاقه توسعه دهندگان است، با راه حل های Cloud Compute، Cloud GPU، Bare Metal و Cloud Storage انعطاف پذیر، مقیاس پذیر، به بیش از 1.5 میلیون مشتری در 185 کشور خدمات رسانی کرده است. درباره Vultr بیشتر بدانید.
برچسبها
|
|



ارسال نظر