مدلهای هوش مصنوعی چگونه فکر میکنند: نقش کلیدی توابع فعالسازی با مثالهای کد

در هوش مصنوعی، یادگیری ماشین پایه و اساس اکثر برنامه های کاربردی انقلابی هوش مصنوعی است. از پردازش زبان گرفته تا تشخیص تصویر، یادگیری ماشینی در همه جا وجود دارد.
یادگیری ماشین بر الگوریتم ها، مدل های آماری و شبکه های عصبی متکی است. و یادگیری عمیق زیرشاخه یادگیری ماشینی است که فقط بر روی شبکه های عصبی متمرکز شده است.
یک بخش کلیدی از هر شبکه عصبی توابع فعال سازی هستند. اما درک دقیق اینکه چرا آنها برای هر سیستم شبکه عصبی ضروری هستند، یک سوال رایج است و پاسخ به آن می تواند دشوار باشد.
این آموزش بر توضیح اینکه چرا عملکردهای فعال سازی دقیقاً ضروری هستند، به روشی ساده با تشبیهات توضیح می دهد.
با درک این موضوع، روند نحوه تفکر مدل های هوش مصنوعی را درک خواهید کرد.
قبل از آن، شبکه های عصبی را در هوش مصنوعی تحلیل خواهیم کرد. ما همچنین متداول ترین توابع فعال سازی را تحلیل خواهیم کرد.
ما همچنین قصد داریم هر خط از یک نمونه کد بسیار ساده PyTorch از یک شبکه عصبی را تجزیه و تحلیل کنیم.
در این مقاله به تحلیل موارد زیر خواهیم پرداخت:
هوش مصنوعی و ظهور یادگیری عمیق
درک توابع فعال سازی: ساده سازی مکانیک شبکه عصبی
قیاس ساده: ضرورت توابع فعال سازی
بدون توابع فعال سازی چه اتفاقی می افتد؟
مثال کد تابع فعال سازی PyTorch
نتیجه گیری: قهرمانان گمنام شبکه های عصبی هوش مصنوعی
این مقاله روشهای ترک تحصیل یا سایر تکنیکهای منظمسازی، بهینهسازی هایپرپارامتر، معماریهای پیچیده مانند CNN، یا تفاوتهای جزئی در انواع نزول گرادیان را پوشش نمیدهد.
من فقط میخواهم نشان دهم که چرا توابع فعالسازی مورد نیاز هستند و وقتی آنها در شبکههای عصبی اعمال نمیشوند چه اتفاقی میافتد.
اگر چیز زیادی در مورد یادگیری عمیق نمی دانید، من شخصاً این دوره آموزشی تصادفی Deep Learning را در کانال YouTube FreeCodeCamp توصیه می کنم:
هوش مصنوعی و ظهور یادگیری عمیق
یادگیری عمیق در هوش مصنوعی چیست؟

یادگیری عمیق زیر شاخه هوش مصنوعی است. از شبکه های عصبی برای پردازش الگوهای پیچیده استفاده می کند، درست مانند استراتژی هایی که یک تیم ورزشی برای برنده شدن در یک مسابقه استفاده می کند.
هرچه شبکه عصبی بزرگتر باشد، توانایی بیشتری برای انجام کارهای عالی دارد - برای مثال ChatGPT، که از پردازش زبان طبیعی برای پاسخ دادن به سوالات و تعامل با کاربران استفاده می کند.
برای درک واقعی اصول اولیه شبکه های عصبی – وجه اشتراک هر مدل هوش مصنوعی که آن را قادر به کار می کند – باید لایه های فعال سازی را درک کنیم.
یادگیری عمیق = آموزش شبکه های عصبی

هسته اصلی یادگیری عمیق، آموزش شبکه های عصبی است.
این بدان معناست که اساساً از داده ها برای بدست آوردن مقادیر مناسب وزن ها استفاده می کنیم تا بتوانیم آنچه را که قصد داریم پیش بینی کنیم.
شبکه های عصبی از نورون هایی ساخته شده اند که در لایه ها سازماندهی شده اند. هر لایه ویژگی های منحصر به فردی را از داده ها استخراج می کند.
این ساختار لایه ای به مدل های یادگیری عمیق اجازه می دهد تا داده های پیچیده را تجزیه و تحلیل و تفسیر کنند.
درک توابع فعال سازی: ساده سازی مکانیک شبکه عصبی
توابع فعال سازی به شبکه های عصبی کمک می کند تا داده های پیچیده را مدیریت کنند. آنها مقدار نورون را بر اساس داده هایی که دریافت می کنند تغییر می دهند.
تقریباً مانند فیلتری است که هر نورون قبل از ارسال مقدار خود به نورون بعدی دارد.
اساساً، توابع فعالسازی جریان اطلاعات شبکههای عصبی را کنترل میکنند - آنها تصمیم میگیرند که کدام داده مرتبط باشد و کدام نه.
این به جلوگیری از ناپدید شدن گرادیان ها کمک می کند تا اطمینان حاصل شود که شبکه به درستی یاد می گیرد.
مشکل شیب ناپدید شدن زمانی اتفاق میافتد که سیگنالهای یادگیری شبکه عصبی برای تغییر مقادیر وزن بسیار ضعیف باشد. این امر یادگیری از داده ها را بسیار دشوار می کند.
تشبیه ساده: چرا توابع فعال سازی ضروری هستند

در یک بازی فوتبال، بازیکنان تصمیم میگیرند که توپ را پاس بدهند، دریبل کنند یا شوت کنند.
این تصمیمات بر اساس وضعیت فعلی بازی است، درست همانطور که نورون ها در یک شبکه عصبی داده ها را پردازش می کنند.
در این حالت، توابع فعال سازی در فرآیند تصمیم گیری به این صورت عمل می کنند.
بدون آنها، نورونها دادهها را بدون هیچ تحلیل انتخابی ارسال میکنند – مانند بازیکنانی که بدون توجه به شرایط بازی، بدون توجه به توپ ضربه میزنند .
به این ترتیب، توابع فعالسازی پیچیدگی را به یک شبکه عصبی وارد میکنند و به آن اجازه میدهند الگوهای پیچیده را یاد بگیرند.
بدون توابع فعال سازی چه اتفاقی می افتد؟

برای درک اینکه بدون عملکردهای فعالسازی چه اتفاقی میافتد، بیایید ابتدا به این فکر کنیم که اگر بازیکنان بدون فکر توپ را در یک مسابقه فوتبال لگد بزنند چه اتفاقی میافتد.
آنها احتمالاً بازی را می بازند زیرا هیچ فرآیند تصمیم گیری به عنوان تیم وجود نخواهد داشت. آن توپ هنوز به جایی می رود - اما بیشتر اوقات به جایی که در نظر گرفته شده است نمی رود.
این شبیه چیزی است که در یک شبکه عصبی بدون توابع فعالسازی اتفاق میافتد: شبکه عصبی پیشبینی خوبی انجام نمیدهد زیرا نورونها فقط دادهها را بهطور تصادفی به یکدیگر ارسال میکردند.
ما هنوز یک پیش بینی داریم. فقط آن چیزی که می خواستیم نیست، یا چیزی که مفید است.
این به طور چشمگیری توانایی تیم فوتبال و شبکه عصبی را محدود می کند.
توضیح شهودی توابع فعال سازی
بیایید اکنون به یک مثال نگاه کنیم تا بتوانید این را به طور مستقیم درک کنید.
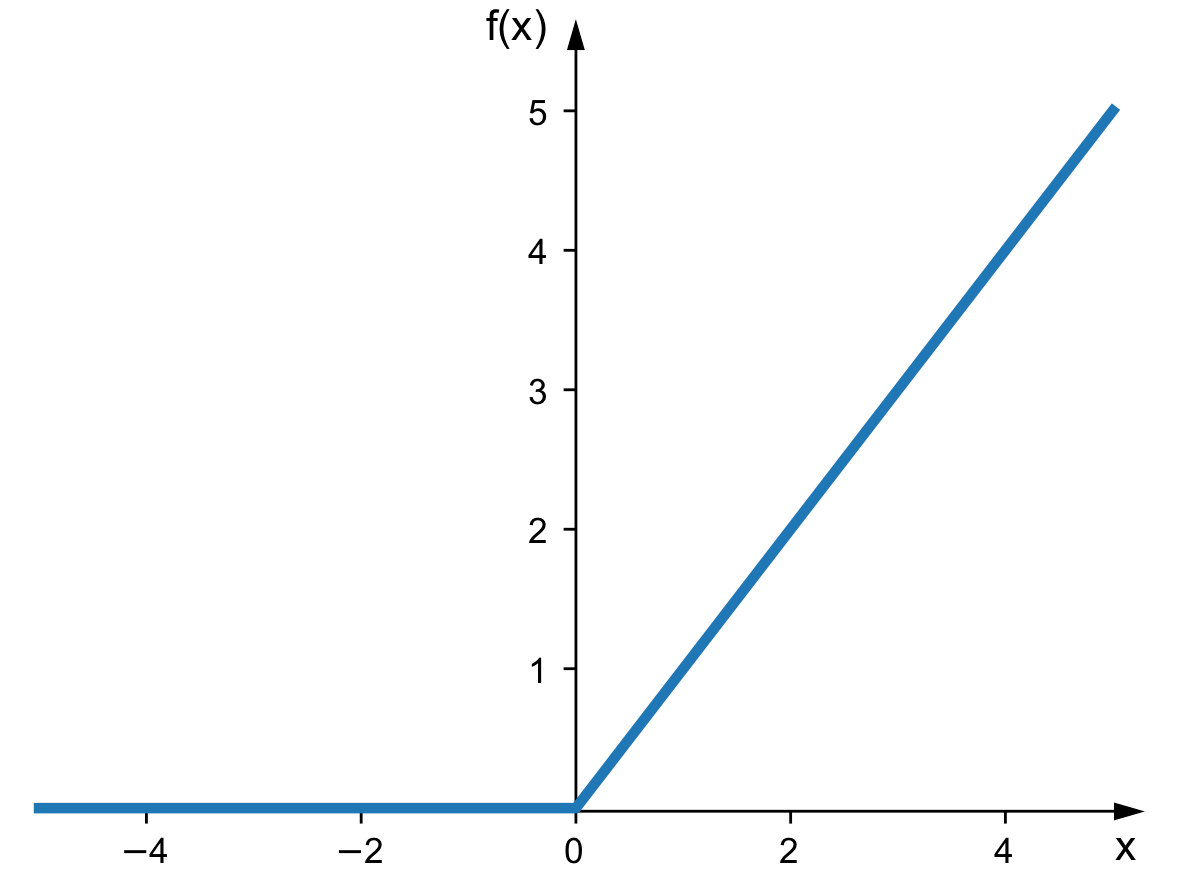
بیایید با پرکاربردترین عملکرد فعال سازی در یادگیری عمیق شروع کنیم (این یکی از ساده ترها نیز می باشد).
این یک تابع فعال سازی ReLU است. قبل از اینکه نورون مقداری را به نورون بعدی خود ارسال کند، اساساً به عنوان یک فیلتر عمل می کند.
این فیلتر در اصل دو شرط است:
اگر مقدار وزن منفی باشد 0 می شود
اگر مقدار وزنه مثبت باشد چیزی را تغییر نمی دهد
با این کار، ما یک فرآیند تصمیم گیری را به هر نورون اضافه می کنیم. تصمیم می گیرد که کدام داده ارسال شود و کدام داده ارسال نشود.
اکنون به چند نمونه از دیگر عملکردهای فعال سازی نگاه می کنیم.
توابع فعال سازی سیگموئید
این تابع فعالسازی مقدار ورودی را بین 0 و 1 تبدیل میکند. سیگموئیدها به طور گسترده در مسائل طبقهبندی باینری در آخرین نورون استفاده میشوند.
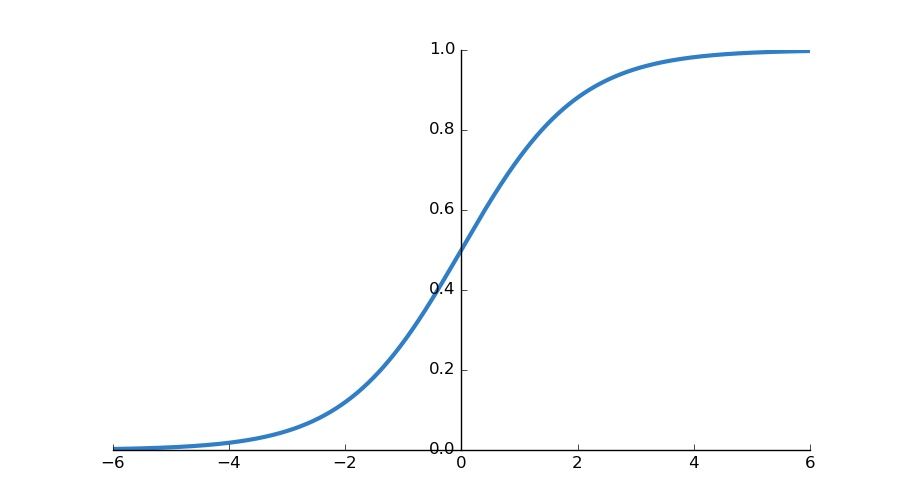
با این حال، یک مشکل با توابع فعال سازی سیگموئید وجود دارد. مقادیر خروجی یک تبدیل خطی داده شده را بگیرید:
0.00000003
0.99999992
0.00000247
0.99993320
سؤالاتی در مورد این مقادیر وجود دارد که می توانیم بپرسیم:
آیا مقادیری مانند 0.00000003 و 0.000002 واقعا مهم هستند؟ آیا آنها نمی توانند فقط 0 باشند تا ما چیزهای کمتری برای اجرا در رایانه داشته باشیم؟ به یاد داشته باشید، در بسیاری از مدل های امروزی، ما میلیون ها وزنه در آنها داریم. آیا میلیون ها 0.00000003 و 0.000002 نمی توانند 0 باشند؟
و اگر یک مقدار مثبت است، چگونه یک ارزش بزرگ را از یک مقدار بسیار بزرگ تشخیص می دهد؟ به عنوان مثال، در 0.99993320 و 0.99999992، مقادیر ورودی مانند 7 و 13 یا 7 و 55 کجا هستند؟ 0.99993320 و 0.99999992 دقیق نیستند مقادیر ورودی آنها را شرح دهید.
چگونه می توانیم تفاوت های ظریف در خروجی ها را تشخیص دهیم تا دقت حفظ شود؟
این همان چیزی است که توابع فعال سازی ReLU حل کردند: تنظیم اعداد منفی روی صفر در حالی که اعداد مثبت را حفظ می کند، کارایی محاسباتی شبکه عصبی را افزایش می دهد.
توابع فعال سازی Tanh (Hyperbolic Tangent).
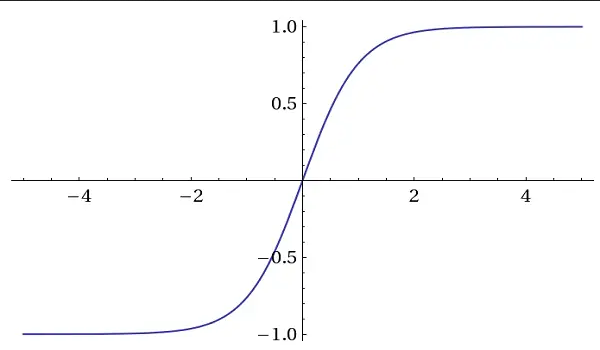
این توابع فعال سازی مقادیر بین 1- و 1 را مشابه Sigmoid تولید می کنند.
آنها اغلب در شبکه های عصبی بازگشتی (RNN) و شبکه های حافظه کوتاه مدت (LSTM) استفاده می شوند.
تنه نیز به دلیل صفر محور بودن استفاده می شود. این بدان معنی است که میانگین مقادیر خروجی در حدود صفر است. این ویژگی هنگام برخورد با مشکل گرادیان ناپدید کننده کمک می کند.
نشتی reLU
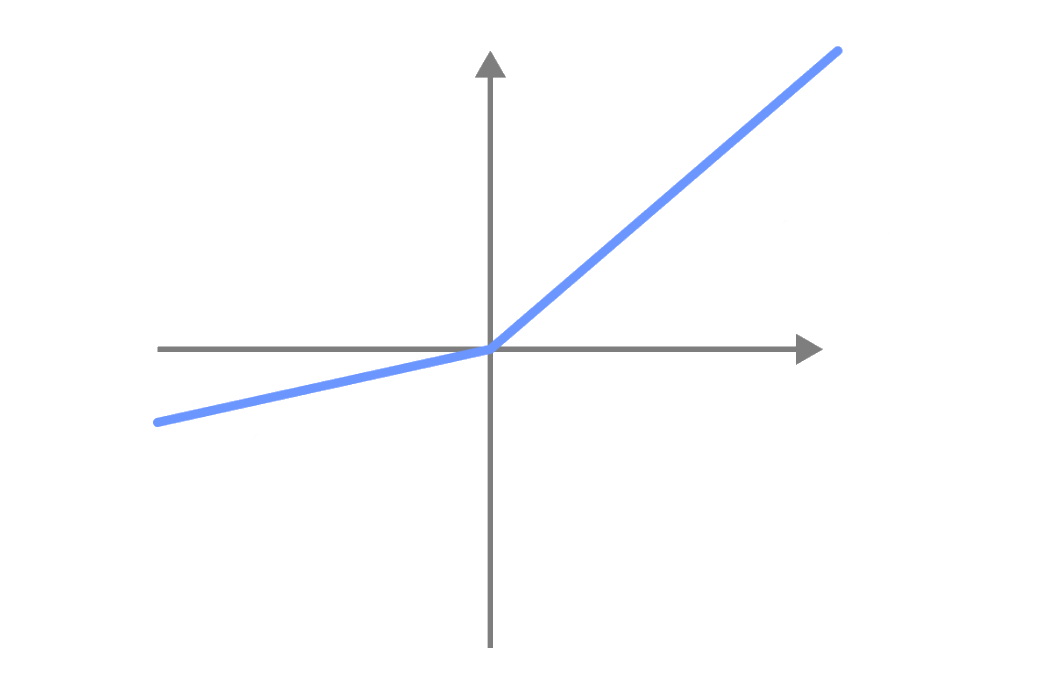
به جای نادیده گرفتن مقادیر منفی، توابع فعالسازی Leaky ReLU دارای مقدار منفی کوچکی هستند.
به این ترتیب هنگام آموزش شبکه های عصبی از مقادیر منفی نیز استفاده می شود.
با تابع فعالسازی ReLU، نورونهایی با مقادیر منفی غیرفعال هستند و به فرآیند یادگیری کمک نمیکنند.
با عملکرد فعالسازی Leaky ReLU، نورونهایی با مقادیر منفی فعال هستند و به فرآیند یادگیری کمک میکنند.
این فرآیند تصمیم گیری توسط تابع فعال سازی اجرا می شود. بدون آن، به سادگی داده ها را به نورون بعدی ارسال می کند (دقیقاً مانند بازیکنی که بدون فکر توپ را لگد می زند).
توضیح ریاضی توابع فعال سازی

نورون ها دو کار انجام می دهند:
آنها از تبدیل های خطی با مقادیر وزن نورون های قبلی استفاده می کنند
آنها از توابع فعال سازی برای فیلتر کردن مقادیر خاص برای انتقال انتخابی مقادیر استفاده می کنند.
بدون توابع فعال سازی، شبکه عصبی فقط یک کار را انجام می دهد: تبدیل های خطی.
اگر فقط تبدیل های خطی را انجام دهد، یک سیستم خطی است.
اگر یک سیستم خطی باشد، به عبارت بسیار ساده بدون اینکه خیلی فنی باشد، قضیه برهم نهی به ما می گوید که هر مخلوطی از دو یا چند تبدیل خطی را می توان به یک تبدیل واحد ساده کرد.
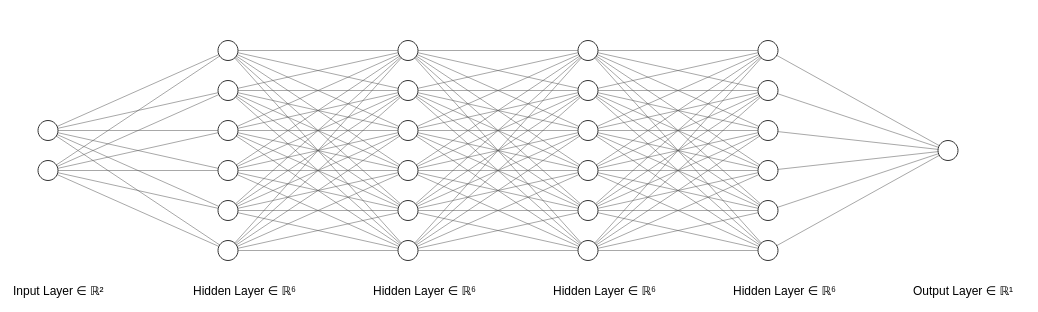
اساساً به این معنی است که بدون توابع فعال سازی، این شبکه عصبی پیچیده:
مثل این ساده است:
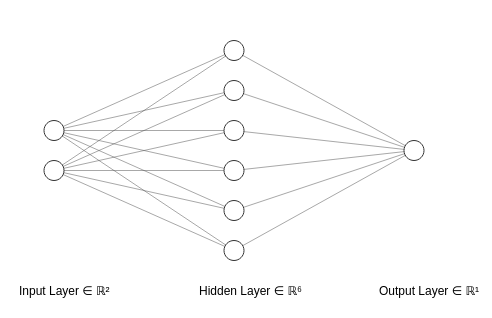
این به این دلیل است که هر لایه در شکل ماتریسی خود محصول تبدیل های خطی لایه های قبلی است.
و با توجه به قضیه، از آنجایی که هر مخلوطی از دو یا چند تبدیل خطی را می توان در یک تبدیل ساده ساده کرد، پس هر مخلوطی از لایه های پنهان (یعنی لایه های بین ورودی و خروجی نورون ها) در یک شبکه عصبی را می توان به شکل ساده تبدیل کرد. فقط یک لایه
این همه به چه معناست؟
این بدان معنی است که فقط می تواند داده ها را به صورت خطی مدل کند. اما در زندگی واقعی با داده های واقعی، هر سیستمی غیر خطی است. پس ما به توابع فعال سازی نیاز داریم.
ما غیرخطی بودن را به یک شبکه عصبی وارد می کنیم تا الگوهای غیر خطی را یاد بگیرد.
مثال کد تابع فعال سازی PyTorch
در این بخش قصد داریم شبکه عصبی زیر را آموزش دهیم:

این یک مدل هوش مصنوعی شبکه عصبی ساده با چهار لایه است:
لایه ورودی با 10 نورون
دو لایه پنهان با 18 نورون
یک لایه پنهان با 18 نورون
یک لایه خروجی با 1 نورون
در کد می توانیم یکی از چهار تابع فعال سازی ذکر شده در این آموزش را انتخاب کنیم.
در اینجا این کد کامل است - در زیر به تفصیل بحث خواهیم کرد:
import torch import torch.nn as nn import torch.optim as optim #Choose which activation function to use in code defined_activation_function = 'relu' activation_functions = { 'relu': nn.ReLU(), 'sigmoid': nn.Sigmoid(), 'tanh': nn.Tanh(), 'leaky_relu': nn.LeakyReLU() } # Initializing hyperparameters num_samples = 100 batch_size = 10 num_epochs = 150 learning_rate = 0.001 # Define a simple synthetic dataset def generate_data(num_samples): X = torch.randn(num_samples, 10) y = torch.randn(num_samples, 1) return X, y # Generate synthetic data X, y = generate_data(num_samples) class SimpleModel(nn.Module): def __init__(self, activation=defined_activation_function): super(SimpleModel, self).__init__() self.fc1 = nn.Linear(in_features=10, out_features=18) self.fc2 = nn.Linear(in_features=18, out_features=18) self.fc3 = nn.Linear(in_features=18, out_features=4) self.fc4 = nn.Linear(in_features=4, out_features=1) self.activation = activation_functions[activation] def forward(self, x): x = self.fc1(x) x = self.activation(x) x = self.fc2(x) x = self.activation(x) x = self.fc3(x) x = self.activation(x) x = self.fc4(x) return x # Initialize the model, define loss function and optimizer model = SimpleModel(activation=defined_activation_function) criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Training loop for epoch in range(num_epochs): for i in range(0, num_samples, batch_size): # Get the mini-batch inputs = X[i:i+batch_size] labels = y[i:i+batch_size] # Zero the parameter gradients optimizer.zero_grad() # Forward pass outputs = model(inputs) # Compute the loss loss = criterion(outputs, labels) # Backward pass and optimize loss.backward() optimizer.step() print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss}') print("Training complete.")خیلی به نظر می رسد، اینطور نیست؟ نگران نباشید - ما آن را تکه تکه خواهیم کرد.
1: وارد کردن کتابخانه ها و تعریف توابع فعال سازی
import torch import torch.nn as nn import torch.optim as optim #Choose which activation function to use in code defined_activation_function = 'relu' activation_functions = { 'relu': nn.ReLU(), 'sigmoid': nn.Sigmoid(), 'tanh': nn.Tanh(), 'leaky_relu': nn.LeakyReLU() } 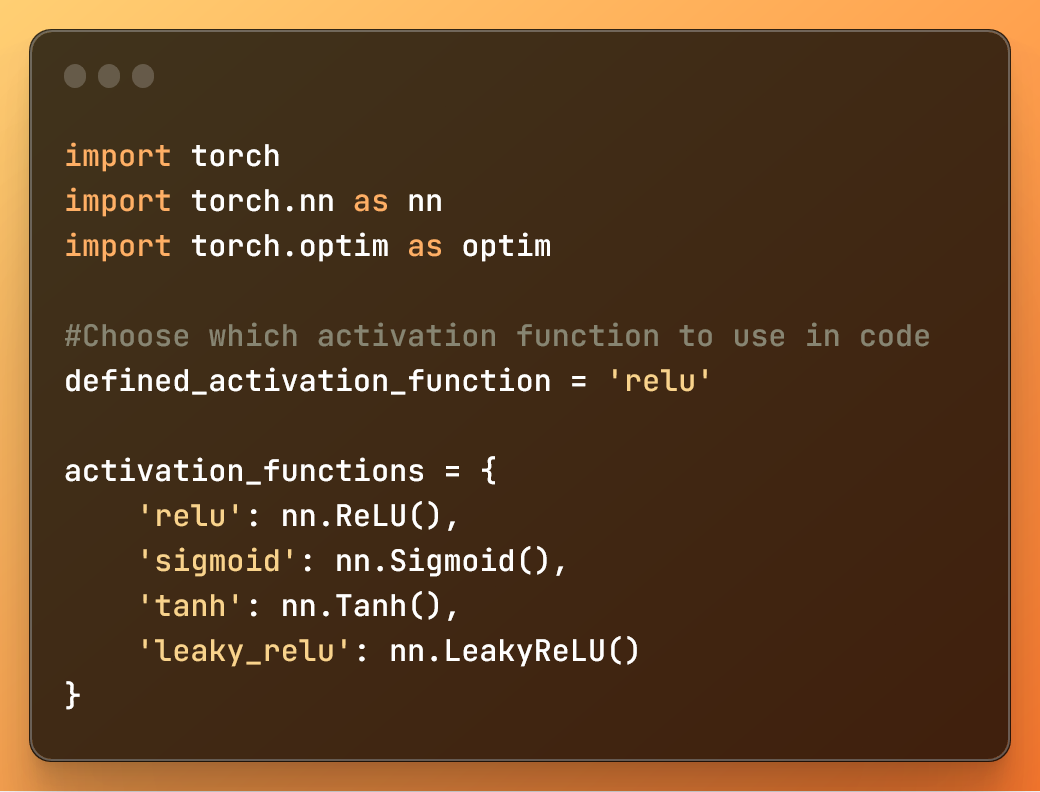
در این کد:
import torch : کتابخانه PyTorch را وارد می کند.
import torch.nn as nn : ماژول شبکه عصبی را از PyTorch وارد می کند.
import torch.optim as optim : ماژول بهینه سازی را از PyTorch وارد می کند.
متغیر و فرهنگ لغت بالا به شما کمک می کند تا به راحتی تابع فعال سازی را برای این مدل یادگیری عمیق تعریف کنید.
2: تعریف هایپرپارامترها و تولید مجموعه داده
# Initializing hyperparameters num_samples = 100 batch_size = 10 num_epochs = 150 learning_rate = 0.001 # Define a simple synthetic dataset def generate_data(num_samples): X = torch.randn(num_samples, 10) y = torch.randn(num_samples, 1) return X, y # Generate synthetic data X, y = generate_data(num_samples) 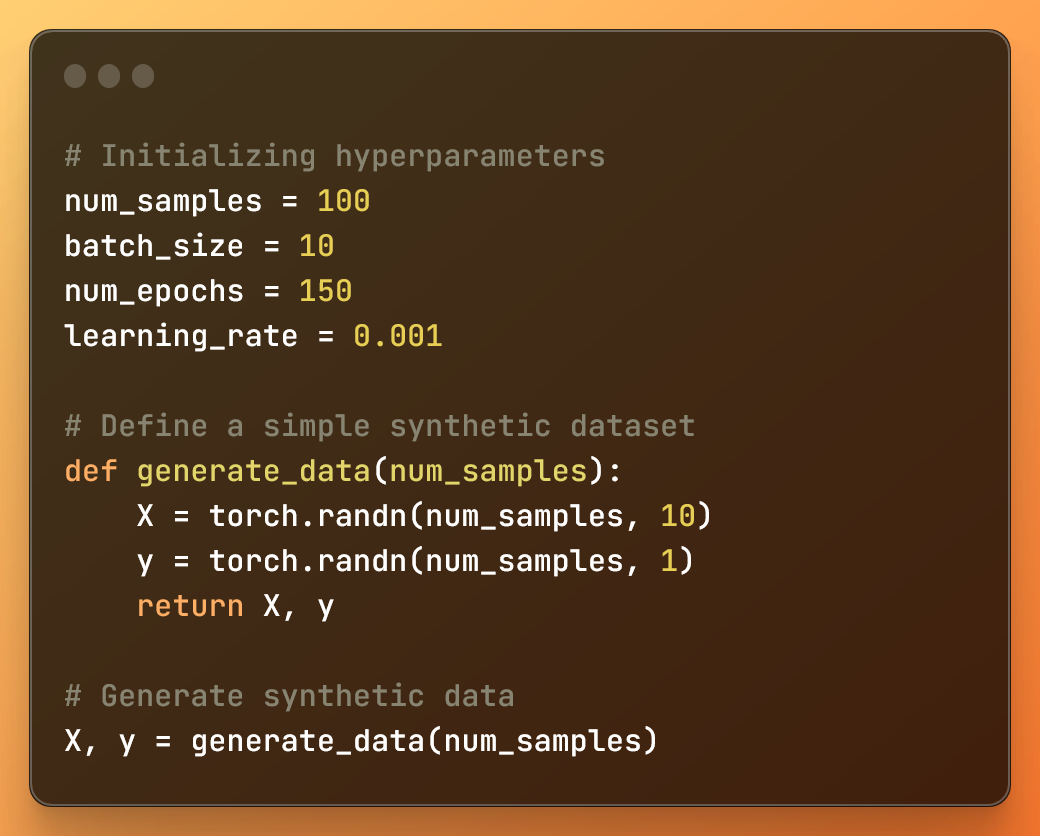
در این کد:
num_samples تعداد نمونههای موجود در مجموعه داده مصنوعی است.
batch_size اندازه هر مینی بچ در طول آموزش است.
num_epochs تعداد تکرارها در کل مجموعه داده در طول آموزش است.
learning_rate نرخ یادگیری است که توسط الگوریتم بهینه سازی استفاده می شود.
علاوه بر این، ما یک تابع generate_data را برای ایجاد دو تانسور با مقادیر تصادفی تعریف می کنیم. سپس تابع را فراخوانی می کند و برای X و y دو تانسور با مقادیر تصادفی تولید می کند.
3: ایجاد مدل یادگیری عمیق
class SimpleModel(nn.Module): def __init__(self, activation=defined_activation_function): super(SimpleModel, self).__init__() self.fc1 = nn.Linear(in_features=10, out_features=18) self.fc2 = nn.Linear(in_features=18, out_features=18) self.fc3 = nn.Linear(in_features=18, out_features=4) self.fc4 = nn.Linear(in_features=4, out_features=1) self.activation = activation_functions[activation] def forward(self, x): x = self.fc1(x) x = self.activation(x) x = self.fc2(x) x = self.activation(x) x = self.fc3(x) x = self.activation(x) x = self.fc4(x) return x 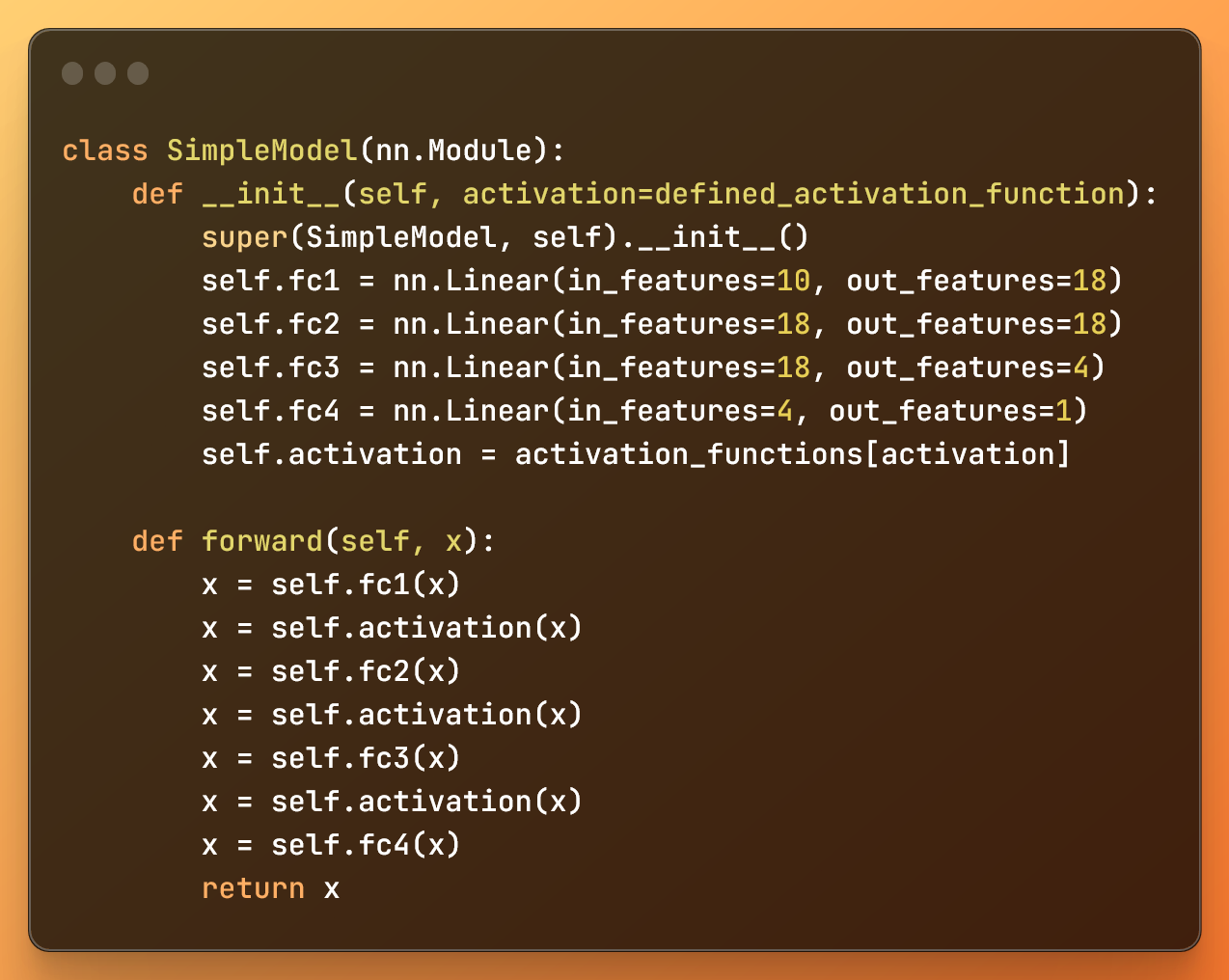
متد __init__ در کلاس SimpleModel مقدار دهی اولیه می شود معماری شبکه عصبی چهار لایه کاملا متصل را مقداردهی اولیه می کند و تابع فعال سازی را که قرار است استفاده کنیم را تعریف می کند.
ما هر لایه را با استفاده از nn.Linear ایجاد می کنیم، در حالی که روش forward نحوه جریان داده ها را در شبکه عصبی تعریف می کند.
4: راه اندازی مدل و تعریف تابع ضرر و بهینه ساز
model = SimpleModel(activation=defined_activation_function) criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=learning_rate) 
در این کد:
model = SimpleModel(activation=defined_activation_function) یک مدل شبکه عصبی با یک تابع فعال سازی مشخص ایجاد می کند.
criterion = nn.MSELoss() تابع ضرر میانگین مربعات خطا (MSE) را تعریف می کند.
optimizer = optim.Adam(model.parameters(), lr=learning_rate) بهینه ساز Adam را برای به روز رسانی پارامترهای مدل در طول آموزش، با نرخ یادگیری مشخص تنظیم می کند.
5: آموزش مدل یادگیری عمیق
for epoch in range(num_epochs): for i in range(0, num_samples, batch_size): # Get the mini-batch inputs = X[i:i+batch_size] labels = y[i:i+batch_size] # Zero the parameter gradients optimizer.zero_grad() # Forward pass outputs = model(inputs) # Compute the loss loss = criterion(outputs, labels) # Backward pass and optimize loss.backward() optimizer.step() print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss}') 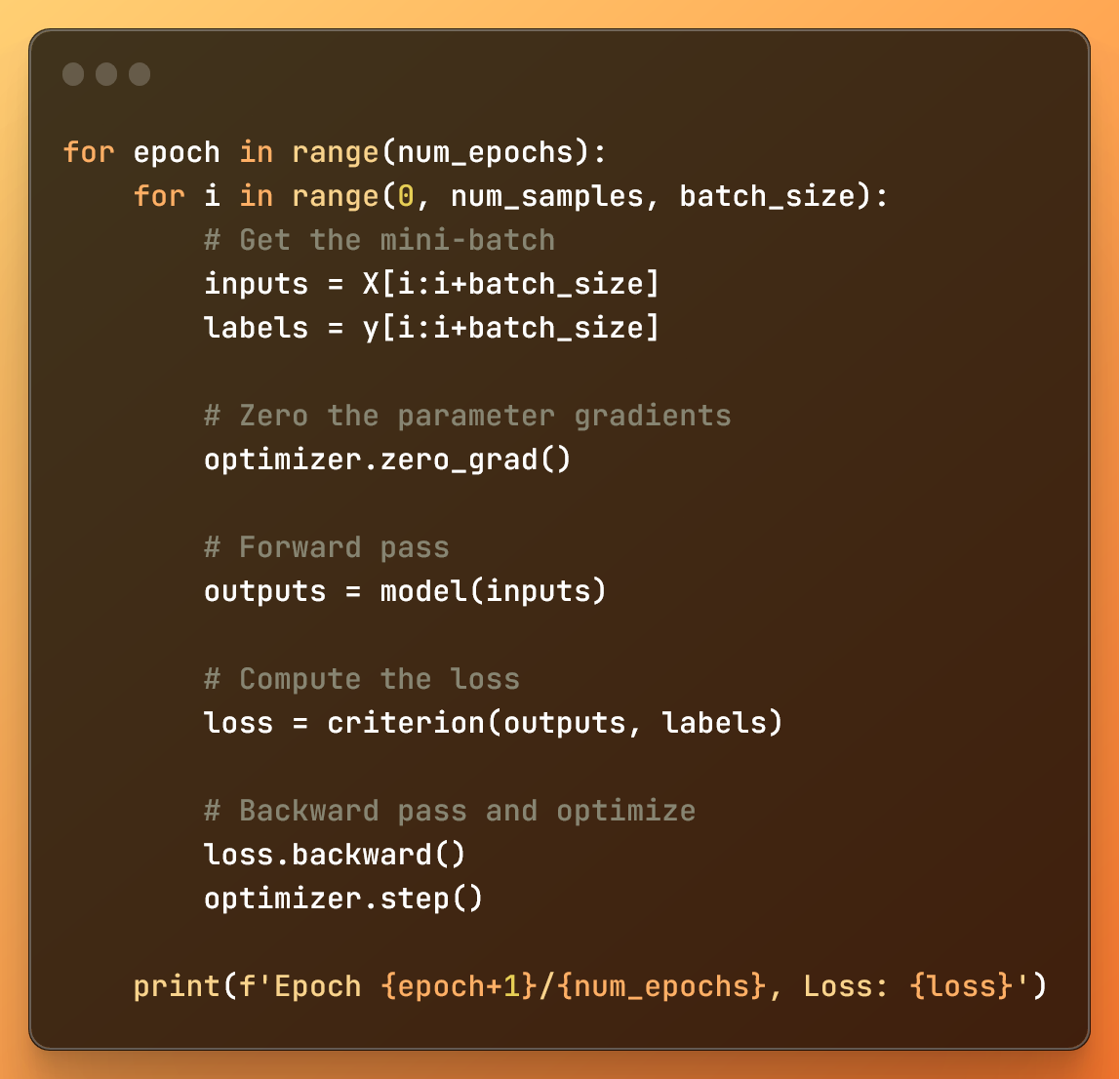
حلقه بیرونی، بر اساس num_epochs (تعداد دورهها) تعداد دفعات پردازش کل مجموعه داده را کنترل میکند.
حلقه داخلی با استفاده از تابع محدوده، مجموعه داده را به دسته های کوچک تقسیم می کند.
در هر حلقه کوچک:
با ورودی ها و برچسب ها، داده ها را از مینی دسته ای که قصد داریم پردازش کنیم، دریافت می کنیم
ما با optimizer.zero_grad() ، گرادیان ها - متغیرهایی که به ما می گویند چگونه وزن ها را برای پیش بینی های دقیق تنظیم کنیم - تکرار دسته ای کوچک قبلی را حذف می کنیم . این برای جلوگیری از اختلاط اطلاعات گرادیان بین مینی دسته ها مهم است.
پاس رو به جلو پیشبینیهای مدل ( outputs ) را به ما میدهد و ضرر با استفاده از تابع ضرر مشخص شده ( criterion ) محاسبه میشود.
با loss.backward() ، گرادیان وزن ها را محاسبه می کنیم.
در نهایت، optimizer.step() وزن های مدل را بر اساس آن گرادیان ها به روز می کند تا تابع ضرر را به حداقل برساند.
این کد کامل برای آموزش یک مدل یادگیری عمیق بسیار ساده بر روی یک مجموعه داده بسیار ساده است.
هیچ چیز پیشرفتهتری مانند شبکههای عصبی کانولوشن ندارد.
نتیجه گیری: قهرمانان گمنام شبکه های عصبی هوش مصنوعی
توابع فعال سازی مانند دروازه بان ها هستند. با محدود کردن جریان اطلاعات، شبکه عصبی می تواند بهتر یاد بگیرد.
عملکردهای فعال سازی دقیقاً مانند افراد هنگام مطالعه یا بازیکنان فوتبال در هنگام تصمیم گیری برای انجام کار با توپ هستند.
این توابع به شبکه های عصبی توانایی یادگیری و پیش بینی صحیح را می دهد.
از نظر ریاضی، توابع فعالسازی چیزی هستند که امکان تقریب صحیح هر تابع خطی یا غیرخطی در شبکههای عصبی را فراهم میکنند. بدون آنها، شبکه های عصبی فقط توابع خطی را تقریب می کنند.
و من شما را با این تنها می گذارم:
ایده ریاضی شبکه عصبی که بتواند هر تابع غیر خطی را تقریب کند، قضیه تقریب جهانی نامیده میشود.
می توانید کد کامل را در GitHub در اینجا پیدا کنید:
 GitHub
GitHubبرچسبها
|
|



ارسال نظر