مدلهای هوش مصنوعی اعداد مورد علاقه خود را دارند، زیرا فکر میکنند مردم هستند
مدلهای هوش مصنوعی همیشه ما را غافلگیر میکنند، نه فقط در آنچه که میتوانند انجام دهند، بلکه در مورد آنچه که نمیتوانند و چرا. یک رفتار جدید جالب در مورد این سیستم ها هم سطحی و هم آشکار است: آنها اعداد تصادفی را طوری انتخاب می کنند که گویی انسان هستند.
اما اولاً، این اصلاً به چه معناست؟ آیا مردم نمی توانند یک عدد را به طور تصادفی انتخاب کنند؟ و چگونه می توانید تشخیص دهید که آیا کسی این کار را با موفقیت انجام می دهد یا خیر؟ این در واقع یک محدودیت بسیار قدیمی و شناخته شده است که ما انسان ها داریم: تصادفی بودن را بیش از حد فکر می کنیم و اشتباه می فهمیم.
به یک نفر بگویید سر یا دم را برای 100 چرخش سکه پیش بینی کند و آن را با 100 چرخش سکه واقعی مقایسه کنید - تقریباً همیشه می توانید آنها را از هم تشخیص دهید زیرا، برخلاف شهود، چرخش سکه های واقعی کمتر تصادفی به نظر می رسند . به عنوان مثال، اغلب شش یا هفت سر یا دم پشت سر هم وجود خواهد داشت، چیزی که تقریباً هیچ پیشبینیکننده انسانی در 100 مورد خود گنجانده نیست.
وقتی از کسی میخواهید عددی را بین 0 تا 100 انتخاب کند، به همین صورت است. مردم تقریباً هرگز 1 یا 100 را انتخاب نمیکنند. به طور کلی از وسط جایی.
نمونه های بی شماری از این نوع پیش بینی پذیری در روانشناسی وجود دارد. اما زمانی که هوش مصنوعی همین کار را انجام میدهد، این امر باعث نمیشود که کمتر عجیب باشد.
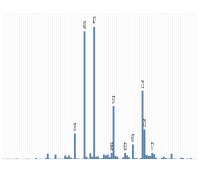
بله، برخی از مهندسان کنجکاو در Gramener یک آزمایش غیررسمی اما جذاب انجام دادند که در آن به سادگی از چندین چت ربات اصلی LLM خواستند تا یک عدد تصادفی بین 0 تا 100 را انتخاب کنند.
خواننده، نتایج تصادفی نبودند .

هر سه مدل آزمایششده دارای یک عدد «مورد علاقه» بودند که همیشه در صورت قرار گرفتن در قطعیترین حالت، پاسخ آنها خواهد بود، اما اغلب حتی در «دماهای» بالاتر ظاهر میشد و تغییرپذیری نتایج آنها را افزایش میداد.
GPT-3.5 Turbo OpenAI واقعاً 47 را دوست دارد. قبلاً 42 را دوست داشت - عددی که البته توسط داگلاس آدامز در The Hitchhiker's Guide to the Galaxy به عنوان پاسخی به زندگی، جهان و همه چیز معروف شد.
هایکوی کلود 3 آنتروپیک با 42 همراه شد و جمینی 72 را دوست دارد.
جالبتر اینکه، هر سه مدل در اعدادی که انتخاب کردند، حتی در دمای بالا، تعصب شبیه به انسان را نشان دادند.
همه تمایل داشتند از اعداد کم و زیاد اجتناب کنند. کلود هرگز بالاتر از 87 یا کمتر از 27 نرفت، و حتی آن ها نیز پرت بودند. از دو رقمی با دقت اجتناب شد: هیچ 33، 55، یا 66، اما 77 نشان داده شد (به 7 ختم می شود). تقریباً هیچ عدد گردی وجود ندارد - اگرچه جمینی یک بار، در بالاترین درجه حرارت، وحشی شد و 0 را انتخاب کرد.
چرا باید اینطور باشد؟ هوش مصنوعی انسان نیست! چرا آنها به آنچه تصادفی «به نظر می رسد» اهمیت می دهند؟ آیا بالاخره به شعور رسیده اند و اینگونه نشان می دهند؟!
نه. پاسخ، همانطور که معمولاً در مورد این موارد اتفاق میافتد، این است که ما یک قدم خیلی دور را انسانسازی میکنیم. این مدل ها به تصادفی بودن و نبودن اهمیتی نمی دهند. آنها نمی دانند "تصادفی" چیست! آنها به این سؤال همانگونه پاسخ می دهند که به بقیه پاسخ می دهند: با نگاه کردن به داده های آموزشی خود و تکرار آنچه که اغلب بعد از سؤالی که شبیه "یک عدد تصادفی انتخاب کنید" نوشته شده است. هر چه بیشتر ظاهر شود، مدل بیشتر آن را تکرار می کند.
اگر تقریباً هیچ کس هرگز چنین پاسخی ندهد، آنها در کجای داده های آموزشی خود 100 را خواهند دید؟ با تمام آنچه که مدل هوش مصنوعی می داند، 100 پاسخ قابل قبولی برای این سوال نیست. بدون توانایی استدلال واقعی، و بدون درک اعداد، فقط می تواند مانند طوطی تصادفی که هست پاسخ دهد.
این یک درس شیئی در عادات LLM است، و انسانیتی که آنها می توانند نشان دهند. در هر تعامل با این سیستمها، باید در نظر داشت که آنها آموزش دیدهاند تا به شیوهای که مردم انجام میدهند، رفتار کنند، حتی اگر این هدف نبوده باشد. به همین دلیل است که اجتناب یا پیشگیری از شبهدرمانی بسیار دشوار است.
من در عنوان نوشتم که این مدلها «فکر میکنند مردم هستند»، اما این کمی گمراهکننده است. اصلا فکر نمیکنن اما در پاسخهای خود در همه حال از مردم تقلید میکنند ، بدون اینکه اصلاً نیازی به دانستن یا فکر کردن داشته باشند. فرقی نمیکند دستور تهیه سالاد نخود را از آن بخواهید، توصیه سرمایهگذاری یا یک عدد تصادفی، روند یکسان است. نتایج به نظر انسانی میرسند، زیرا انسان هستند و مستقیماً از محتوای تولید شده توسط انسان استخراج شده و دوباره میکس شدهاند - برای راحتی شما و البته هدف اصلی هوش مصنوعی.
برچسبها
|
|






ارسال نظر