غواصی عمیق در راه حل های هوش مصنوعی مولد درجه سازمانی ساختمان
این مقاله راهنمای جامعی در مورد اصول اساسی، روششناسی و بهترین شیوهها برای پیادهسازی راهحلهای هوش مصنوعی در محیطهای سازمانی در مقیاس بزرگ ارائه میکند.
این مؤلفههای کلیدی معماری Gen AI، مانند پایگاههای داده برداری، جاسازیها، و مهندسی سریع را پوشش میدهد و بینشهای عملی را در مورد برنامههای کاربردی در دنیای واقعی ارائه میدهد.
این مقاله تکنیکهای مهندسی سریع را با جزئیات تحلیل میکند و در مورد چگونگی بهینهسازی اعلانها برای راهحلهای موثر هوش مصنوعی مولد بحث میکند.
Retrieval Augmented Generation (RAG) را معرفی میکند و توضیح میدهد که چگونه میتوان دادهها را از بازیابی داده جدا کرد تا عملکرد سیستم را بهبود بخشد.
یک مثال عملی با استفاده از کد پایتون گنجانده شده است که نحوه پیادهسازی RAG با LangChain، Chroma Database و OpenAI API را نشان میدهد و راهنماییهای عملی را برای توسعهدهندگان ارائه میدهد.
سال گذشته، شاهد بودیم که OpenAI با معرفی ChatGPT به مصرف کنندگان در سراسر جهان، چشم انداز فناوری را متحول کرد. این ابزار به سرعت در مدت کوتاهی پایگاه کاربران زیادی را به دست آورد و حتی از پلتفرم های رسانه های اجتماعی محبوب پیشی گرفت. ChatGPT با استفاده از هوش مصنوعی Generative، نوعی فناوری یادگیری عمیق، بر مصرفکنندگان تأثیر میگذارد و همچنین توسط بسیاری از شرکتها برای هدف قرار دادن موارد استفاده تجاری بالقوه که قبلاً چالشهای غیرممکن تلقی میشدند، استفاده میشود.
مروری بر هوش مصنوعی مولد در سازمانی –
نظرسنجی اخیری که توسط BCG با 1406 CXO در سطح جهانی انجام شد نشان داد که هوش مصنوعی مولد یکی از سه فناوری برتر (پس از امنیت سایبری و رایانش ابری) است که 89 درصد از آنها در نظر دارند برای سال 2024 در آن سرمایه گذاری کنند. محصولات Gen-AI یا سرمایه گذاری برای گفت ن خط تولید Gen-AI به فهرست دارایی های شرکت خود از ارائه دهندگان خارجی.
با رشد گسترده پذیرش Gen-AI در تنظیمات سازمانی، بسیار مهم است که یک معماری مرجع با معماری خوب به تیم مهندسی و معماران کمک کند تا نقشههای راه و بلوکهای ساختمانی برای ساخت راهحلهای Gen-AI ایمن و سازگار را شناسایی کنند. این راه حل ها نه تنها باعث ایجاد نوآوری می شوند، بلکه رضایت ذینفعان را نیز افزایش می دهند.
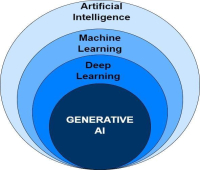
قبل از غواصی عمیق، باید بدانیم که هوش مصنوعی مولد چیست؟ برای درک هوش مصنوعی مولد، ابتدا باید چشماندازی را که در آن عمل میکند، درک کنیم. این چشمانداز با هوش مصنوعی (AI) شروع میشود که به رشتهای از سیستمهای کامپیوتری اشاره دارد که سعی میکنند رفتار انسان را تقلید کنند و وظایف را بدون برنامهنویسی صریح انجام دهند. یادگیری ماشین (ML) بخشی از هوش مصنوعی است که بر روی مجموعه داده عظیمی از داده های تاریخی عمل می کند و بر اساس الگوهایی که بر روی آن داده ها شناسایی کرده است، پیش بینی می کند. برای مثال، ML میتواند پیشبینی کند که مردم چه زمانی اقامت در هتلها را در مقابل اقامت در خانههای اجارهای از طریق AirBNB در فصول خاص بر اساس دادههای گذشته ترجیح میدهند. یادگیری عمیق نوعی ML است که با استفاده از شبکههای عصبی عمیق مصنوعی، مشابه مغز انسان، به قابلیتهای شناختی رایانهها کمک میکند. این شامل لایههایی از پردازش داده است که در آن هر لایه خروجی قبلی را اصلاح میکند و در نهایت محتوای پیشبینی تولید میکند. هوش مصنوعی مولد زیرمجموعهای از تکنیکهای یادگیری عمیق است که از الگوریتمهای مختلف یادگیری ماشین و شبکههای عصبی مصنوعی برای تولید محتوای جدید مانند متن، صدا، ویدئو یا تصاویر، بدون دخالت انسان بر اساس دانشی که در طول آموزش کسب کرده است، استفاده میکند.
اهمیت راه حل های ایمن و سازگار Gen-AI –
همانطور که Gen-AI به فناوری نوظهور تبدیل می شود، بیشتر و بیشتر شرکت ها در تمام صنایع برای پذیرش این فناوری عجله دارند و توجه کافی به لزوم تمرین برای پیروی از هوش مصنوعی مسئول، هوش مصنوعی قابل توضیح و جنبه انطباق و امنیت از این فناوری ندارند. راه حل ها به همین دلیل ما شاهد مسائل مربوط به حریم خصوصی مشتری یا سوگیری در محتوای تولید شده هستیم. این افزایش سریع پذیرش GEN-AI نیازمند یک رویکرد آهسته و پیوسته است زیرا با قدرت زیاد، مسئولیت بیشتری نیز به همراه دارد. قبل از اینکه این حوزه را بیشتر تحلیل کنیم، میخواهم چند مثال را برای نشان دادن دلیل آن به اشتراک بگذارم
سازمانها باید سیستمهای مبتنی بر GEN-AI را مسئولانه و با رعایت اصول طراحی کنند، در غیر این صورت ممکن است خطر از دست دادن اعتماد عمومی به ارزش برند خود را داشته باشند. سازمانها باید در حین ساخت، پیادهسازی، و بهبود منظم سیستمهای Gen-AI و همچنین نظارت بر عملکرد آنها و محتوای تولید شده، از یک رویکرد متفکرانه و جامع پیروی کنند.
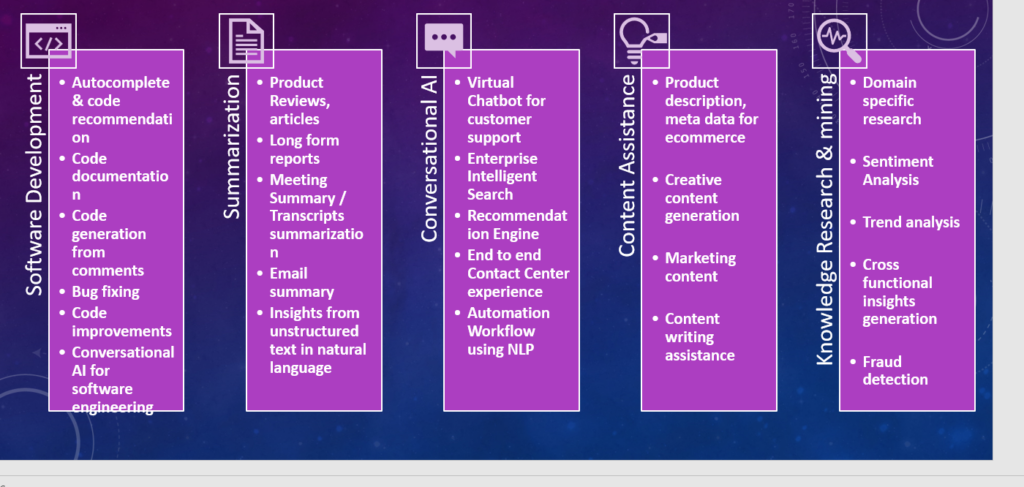
کاربردهای رایج و مزایای هوش مصنوعی مولد در تنظیمات سازمانی
سازمان های متمرکز بر فناوری می توانند از قدرت واقعی Gen-AI در توسعه نرم افزار با افزایش بهره وری و کیفیت کد استفاده کنند. آپشن های تکمیل خودکار و توصیه کد مبتنی بر هوش مصنوعی به توسعهدهندگان و مهندسان کمک میکند تا کد را کارآمدتر بنویسند، در حالی که اسناد کد و تولید از نظرات زبان طبیعی در هر زبانی میتواند فرآیند توسعه را سادهتر کند. سرنخهای فنی میتوانند با استفاده از Gen-AI برای انجام بازبینی دستی تکراری، رفع اشکال و بهبود کیفیت کد، تلاشهای توسعه قابل توجهی را کاهش دهند. این منجر به چرخه های توسعه و انتشار سریع تر و نرم افزار با کیفیت بالاتر می شود. همچنین، هوش مصنوعی محاوره ای برای مهندسی نرم افزار به فعال کردن تعاملات زبان طبیعی کمک می کند، که همکاری و ارتباط بین اعضای تیم را بهبود می بخشد. مدیران و صاحبان محصول می توانند از هوش مصنوعی Generative برای مدیریت چرخه عمر محصول، ایده پردازی، برنامه ریزی نقشه راه محصول و همچنین ایجاد داستان کاربر و نوشتن معیارهای پذیرش با کیفیت بالا استفاده کنند.
خلاصه کردن محتوا حوزه دیگری است که در آن هوش مصنوعی مولد، فناوری برتر هوش مصنوعی در حال استفاده است. این می تواند به طور خودکار تحلیل های معنی دار محصول، مقالات، گزارش های طولانی، رونوشت جلسات و ایمیل ها را خلاصه کند و در زمان و تلاش تحلیلگران صرفه جویی کند. هوش مصنوعی مولد همچنین با ایجاد یک نمودار دانش بر اساس بینش های کلیدی استخراج شده از متن و داده های بدون ساختار به تصمیم گیری آگاهانه و شناسایی روندها کمک می کند.
در پشتیبانی مشتری، هوش مصنوعی Generative به چتباتهای مجازی کمک میکند که به مشتریان کمک میکنند، که تجربه کلی کاربر را افزایش میدهد. به عنوان مثال، در صنعت مراقبت های بهداشتی برای بیمارانی که با برنامه مواجه هستند، چت بات ها می توانند با ارائه پاسخ های همدلانه بیشتر بیمار محور باشند. این امر به سازمان کمک می کند تا رضایت مشتری بیشتری کسب کند. موتورهای جستجوی هوشمند سازمانی از هوش مصنوعی مولد برای ارائه سریع و دقیق اطلاعات مرتبط استفاده می کنند. سیستمهای توصیهای که توسط هوش مصنوعی Generative ارائه میشوند، رفتارهای کاربر را تجزیه و تحلیل میکنند تا پیشنهادات سفارشیسازی شده را ارائه دهند که تعامل و رضایت مشتری را بهبود میبخشد. همچنین، هوش مصنوعی Generative تجربههای مرکز تماس سرتاسری، خودکارسازی گردش کار و کاهش هزینههای عملیاتی را امکانپذیر میسازد. نمایندگان زنده می توانند از قابلیت خلاصه سازی برای درک سریع فرآیند یا رویه ها استفاده کنند و می توانند به سرعت مشتریان خود را راهنمایی کنند.
هوش مصنوعی مولد همچنین پیشرفت های قابل توجهی در کمک محتوا داشته است. این می تواند به تولید توضیحات محصول، کلمات کلیدی و ابرداده برای پلتفرم های تجارت الکترونیک، ایجاد محتوای بازاریابی جذاب و کمک به وظایف نوشتن محتوا کمک کند. همچنین میتواند با استفاده از پردازش زبان طبیعی (NLP) برای درک و تفسیر نیازهای کاربر، تصاویری را برای اهداف بازاریابی و برندسازی تولید کند.
در زمینه تحقیقات دانش و داده کاوی، هوش مصنوعی مولد برای تحقیقات دامنه خاص، تجزیه و تحلیل احساسات مشتری، تجزیه و تحلیل روند، و ایجاد بینش های متقابل استفاده می شود. همچنین نقش مهمی در کشف تقلب ایفا می کند و از توانایی خود برای تجزیه و تحلیل حجم وسیعی از داده ها و شناسایی الگوهایی که نشان دهنده فعالیت های تقلبی هستند، استفاده می کند.
پس میتوانیم ببینیم که هوش مصنوعی مولد با فعال کردن اتوماسیون هوشمند و افزایش فرآیندهای تصمیمگیری، صنایع را متحول میکند. کاربردهای متنوع آن در توسعه نرمافزار، خلاصهسازی، هوش مصنوعی محاورهای، کمک محتوا و تحقیقات دانش پتانسیل واقعی آن را در چشمانداز سازمانی نشان میدهد. اگر یک کسب و کار بتواند به سرعت هوش مصنوعی مولد را بپذیرد، در مسیر دستیابی به مزیت رقابتی و ایجاد نوآوری در صنایع مربوطه خود است.
همانطور که می توان مشاهده کرد که هوش مصنوعی مولد با ارتقای تجربیات مشتریان از محصولات یا بهبود بهره وری نیروی کار، ارزش تجاری قابل توجهی را برای هر سازمانی به ارمغان آورده است. شرکتهایی که در مسیر پذیرش راهحلهای Gen-AI هستند، پتانسیل واقعی برای ایجاد فرآیندهای تجاری جدید برای هدایت نوآوریها پیدا میکنند. ویژگی Co-Pilot محصولات یا نمایندگان Gen-AI این توانایی را دارند که یک زنجیره فکری را انجام دهند تا براساس دانش بیرونی مانند نتایج API یا خدمات برای تکمیل وظایف تصمیم گیری تصمیم گیری کنند. کاربردهای متعددی در صنایع مختلف وجود دارد.
نمودار زیر برخی از قابلیت هایی را نشان می دهد که می توان با استفاده از Gen-AI در مقیاس امکان پذیر بود.
اجزای اصلی معماری سازمانی برای هوش مصنوعی Generative دارای بلوکهای ساختمانی متفاوتی هستند. در این بخش به سرعت برخی از مؤلفه ها مانند پایگاه داده برداری، مهندسی سریع و مدل زبان بزرگ (LLM) را لمس خواهیم کرد. در دنیای هوش مصنوعی یا یادگیری ماشین، داده ها در قالب عددی چند بعدی نشان داده می شوند که به آن Embedding یا Vector می گویند. پایگاه داده برداری برای ذخیره و بازیابی بردارهایی که جنبه های مختلف داده را نشان می دهند، بسیار مهم است و پردازش و تجزیه و تحلیل کارآمد را ممکن می سازد. Prompt Engineering بر طراحی اعلانهای موثر برای هدایت خروجی مدل هوش مصنوعی تمرکز میکند و از پاسخهای مرتبط و دقیق از LLM اطمینان میدهد. مدلهای زبان بزرگ بهعنوان ستون فقرات هوش مصنوعی مولد عمل میکنند که از الگوریتمهای مختلف (ترانسفورماتور یا GAN و غیره) استفاده میکند و مجموعههای داده وسیعی را از قبل آموزش میدهد تا محتوای دیجیتال پیچیده و منسجمی را در قالب متون یا صدا یا ویدیو تولید کند. این مؤلفهها با هم کار میکنند تا عملکرد و عملکرد راهحلهای هوش مصنوعی تولیدی را در تنظیمات سازمانی مقیاسپذیر کنند. در بخش های بعدی بیشتر تحلیل خواهیم کرد.
پایگاه داده برداری –
اگر پیشینه علم داده یا یادگیری ماشین دارید یا قبلاً با سیستمهای ML کار کردهاید، به احتمال زیاد در مورد جاسازیها یا بردارها اطلاعات دارید. به زبان ساده، تعبیهها برای تعیین شباهت یا نزدیکی بین موجودیتها یا دادههای مختلف، خواه متون، کلمات، گرافیک، داراییهای دیجیتال یا هر قطعه اطلاعاتی باشند، استفاده میشوند. برای اینکه ماشین محتویات مختلف را بفهمد، به فرمت عددی تبدیل میشود. این نمایش عددی توسط یک مدل یادگیری عمیق دیگر محاسبه می شود که ابعاد آن محتوا را تعیین می کند.
بخش زیر تعبیههای معمولی را نشان میدهد که توسط مدل « text-embedding-ada-002-v2 » برای متن ورودی «راهحل با هوش مصنوعی مولد» که ابعاد 1536 دارد، ایجاد شده است.
| «شیء»: «فهرست» "داده ها": [ { «شیء»: «جاسازی» "شاخص": 0، "جاسازی": [ -0.01426721، -0.01622797، -0.015700348، 0.015172725، -0.012727121، 0.01788214، -0.05147889، 0.022473885، 0.02689451، 0.016898194، 0.0067129326، 0.008470487، 0.0025008614، 0.025825003، . . <خیلی زیاد>… . 0.032398902، -0.01439555، -0.031229576، -0.018823305، 0.009953735، -0.017967701، -0.00446697، -0.020748416 ] } ]، "model": "text-embedding-ada-002-v2"، "استفاده": { "prompt_tokens": 6، "Total_Tokens": 6 } }{ |
پایگاههای داده سنتی در هنگام ذخیره دادههای برداری با ابعاد بالا در کنار انواع دیگر دادهها با چالشهایی مواجه میشوند، هرچند استثناهایی وجود دارد که در ادامه به آنها خواهیم پرداخت. این پایگاه داده ها همچنین با مسائل مقیاس پذیری دست و پنجه نرم می کنند. همچنین، آنها فقط زمانی نتایج را برمیگردانند که کوئری ورودی دقیقاً با متن ذخیره شده در فهرست مطابقت داشته باشد. برای غلبه بر این چالش ها، یک مفهوم پایگاه داده پیشرفته پدید آمده است که قادر است این داده های برداری با ابعاد بالا را به طور موثر ذخیره کند. این راه حل نوآورانه از الگوریتم هایی مانند K-th Nearest Neighbor (K-NN) یا Approximate Nearest Neighbor (A-NN) برای فهرست بندی و بازیابی داده های مرتبط، بهینه سازی برای کوتاه ترین مسافت ها استفاده می کند. این پایگاههای داده بردار وانیلی، فهرستهای دادههای مرتبط و مرتبط را در حین ذخیره نگه میدارند و پس در صورت افزایش تقاضا از سوی برنامه، به طور موثر مقیاس میشوند.
مفهوم پایگاه داده های برداری و جاسازی ها نقش مهمی در طراحی و توسعه برنامه های کاربردی هوش مصنوعی Enterprise Generative ایفا می کند. به عنوان مثال در موارد استفاده از QnA در دادههای خصوصی موجود یا ساخت رباتهای گفتگوی پایگاه داده Vector پشتیبانی از حافظه متنی را برای LLMها فراهم میکند. برای ساختن جستجوی سازمانی یا سیستم توصیه پایگاه داده های برداری استفاده می شود زیرا دارای قابلیت های قدرتمند جستجوی معنایی است.
دو نوع اصلی از پیادهسازی پایگاه داده برداری برای تیم مهندسی در حین ساخت برنامههای هوش مصنوعی بعدی وجود دارد: پایگاههای داده برداری خالص وانیلی و پایگاههای داده برداری یکپارچه در یک NoSQL یا پایگاهداده رابطهای.
پایگاه داده برداری خالص وانیلی: یک پایگاه داده برداری خالص به طور خاص برای ذخیره و مدیریت کارآمد جاسازی های برداری، همراه با مقدار کمی ابرداده طراحی شده است. این به طور مستقل از منبع داده ای که جاسازی ها را تولید می کند عمل می کند، به این معنی که شما می توانید از هر نوع مدل یادگیری عمیق برای تولید Embedding با ابعاد مختلف استفاده کنید، اما همچنان می توانید آنها را به طور موثر در پایگاه داده بدون هیچ گونه تغییر یا ترفند اضافی در بردارها ذخیره کنید. محصولات منبع باز مانند پایگاه داده Weaviate، Milvus، Chroma پایگاه های داده برداری خالص هستند. پایگاه داده برداری محبوب مبتنی بر SAAS Pinecone همچنین یک انتخاب محبوب در میان جامعه توسعه دهندگان در هنگام ساخت برنامه های کاربردی هوش مصنوعی مانند جستجوی سازمانی، سیستم توصیه یا سیستم تشخیص تقلب است.
پایگاه داده برداری یکپارچه: از سوی دیگر، یک پایگاه داده برداری یکپارچه در یک NoSQL یا پایگاه داده رابطه ای عملکردهای بیشتری ارائه می دهد. این رویکرد یکپارچه امکان ذخیره سازی، نمایه سازی و جستجوی جاسازی ها را در کنار داده های اصلی فراهم می کند. با ادغام عملکرد پایگاه داده برداری و قابلیت جستجوی معنایی در زیرساخت پایگاه داده موجود، نیازی به کپی کردن داده ها در یک پایگاه داده برداری خالص جداگانه نیست. این ادغام همچنین عملیات داده های چندوجهی را تسهیل می کند و ثبات، مقیاس پذیری و عملکرد بیشتر داده ها را تضمین می کند. با این حال، این نوع پایگاه داده فقط میتواند انواع بردار مشابه را پشتیبانی کند، با ابعاد یکسانی که توسط همان نوع LLM ایجاد شده است. به عنوان مثال پسوند pgVector پایگاه داده PostGres را به یک پایگاه داده برداری تبدیل می کند اما شما نمی توانید داده های برداری با اندازه های مختلف مانند 512 یا 1536 را با هم ذخیره کنید. نسخه Enterprise Redis همراه با جستجوی برداری فعال است که پایگاه داده Redis noSQL را به یک پایگاه داده برداری با قابلیت تبدیل می کند. نسخه اخیر MongoDB از قابلیت جستجوی برداری نیز پشتیبانی می کند.
مهندسی سریع –
مهندسی سریع هنر ایجاد متن یا عبارات مختصر با پیروی از دستورالعمل ها و اصول خاص است. این اعلانها به عنوان دستورالعملهایی برای مدلهای زبان بزرگ (LLM) عمل میکنند تا LLM را برای تولید خروجی دقیق و مرتبط راهنمایی کنند. این فرآیند بسیار مهم است زیرا اعلانهای ضعیف میتوانند منجر به ایجاد پاسخهای توهمآمیز یا نامربوط توسط LLM شوند. پس ، طراحی دقیق دستورات برای هدایت مدل به طور موثر ضروری است.
هدف مهندسی سریع این است که اطمینان حاصل شود که ورودی داده شده به LLM واضح، مرتبط و از نظر زمینه مناسب است. با پیروی از اصول مهندسی سریع، توسعه دهندگان می توانند پتانسیل LLM را به حداکثر برسانند و عملکرد آن را بهبود بخشند. به عنوان مثال، اگر قصد تولید خلاصهای از یک متن طولانی است، باید به LLM دستور دهد که اطلاعات را به یک خلاصه و منسجم فشرده کند.
همچنین، مهندسی سریع به فعال کردن LLM برای نشان دادن قابلیت های مختلف بر اساس هدف عبارات ورودی کمک می کند. این قابلیت ها شامل خلاصه کردن متون گسترده، روشن کردن موضوعات، تبدیل متون ورودی یا گسترش اطلاعات ارائه شده است. توسعه دهندگان با ارائه اعلان های ساختاریافته می توانند توانایی LLM را در درک و پاسخگویی دقیق به پرس و جوها و درخواست های پیچیده افزایش دهند.
یک ساختار معمولی از هر درخواستی که به خوبی ساخته شده است، دارای بلوکهای ساختمانی زیر خواهد بود تا اطمینان حاصل شود که زمینه کافی و زمان کافی برای فکر کردن به مدل برای تولید خروجی با کیفیت را فراهم میکند.
| دستورالعمل و وظایف | زمینه و مثال ها | نقش (اختیاری) | لحن (اختیاری) | مرزها (اختیاری) | فرمت خروجی (اختیاری) |
| دستورالعمل روشنی ارائه دهید و وظایفی را که LLM قرار است تکمیل کند را مشخص کنید | زمینه ورودی و اطلاعات خارجی را فراهم کنید تا مدل بتواند وظایف را انجام دهد. | اگر LLM باید نقش خاصی را برای تکمیل یک کار دنبال کند، باید به آن اشاره شود. | سبک نوشتن را ذکر کنید، به عنوان مثال می توانید از LLM بخواهید که پاسخ را به زبان انگلیسی حرفه ای ایجاد کند. | مدل نردههای محافظ و محدودیتهایی را که باید هنگام تولید خروجی تحلیل کنید، یادآوری کنید. | اگر بخواهیم LLM خروجی را در قالب خاصی تولید کند. به عنوان مثال json یا xml و غیره، درخواست باید موارد ذکر شده را داشته باشد. |
به طور خلاصه، مهندسی سریع نقش حیاتی ایفا می کند تا اطمینان حاصل شود که LLM ها خروجی معنادار و مناسبی را برای وظایفی که قرار است انجام دهند، تولید می کنند. با پیروی از اصول مهندسی سریع، توسعه دهندگان می توانند اثربخشی و کارایی LLM ها را در طیف وسیعی از کاربردها، از خلاصه کردن متن گرفته تا ارائه توضیحات و بینش دقیق، بهبود بخشند.
تکنیک ها یا الگوهای مهندسی سریع مختلفی وجود دارد که می توان از آنها در هنگام توسعه راه حل Gen-AI استفاده کرد. این الگوها یا تکنیک های پیشرفته، تلاش تیم مهندسی توسعه را کوتاه می کند و قابلیت اطمینان و عملکرد را ساده می کند.
درخواست صفر شات - درخواست صفر شات به نوعی از دستورات اشاره دارد که از مدل میخواهد برخی کارها را انجام دهد اما هیچ مثالی ارائه نمیکند. این مدل محتوا را بر اساس آموزش قبلی تولید می کند. این در کارهای ساده ساده NLP استفاده می شود. به عنوان مثال ارسال پاسخ ایمیل خودکار، خلاصه سازی متن ساده.
درخواست Few-Shot - در الگوی اعلان چند شات، چندین مثال در زمینه ورودی به LLM و یک دستورالعمل واضح ارائه میشود تا مدل بتواند از مثالها بیاموزد و نوع پاسخها را بر اساس نمونههای ارائه شده تولید کند. این الگوی اعلان زمانی استفاده میشود که کار یک کار پیچیده باشد و دستور صفر شات نتواند نتایج لازم را ایجاد کند.
Chain-Of-Thought - الگوی سریع زنجیره ای فکر (CoT) در موارد استفاده مناسب است که در آن ما به LLM برای نشان دادن قابلیت های استدلال پیچیده نیاز داریم. در این رویکرد مدل فرآیند فکری خود را گام به گام قبل از ارائه پاسخ نهایی نشان می دهد. این رویکرد را می توان با تحریک چند شات ترکیب کرد، که در آن چند مثال برای راهنمایی مدل ارائه شده است تا به نتایج بهتری در کارهای پیچیده ای که نیاز به استدلال قبل از پاسخ دادن دارند، دست یابیم.
ReAct - در این الگو، LLMها به ابزارها یا سیستم خارجی دسترسی دارند. LLMها به این ابزارها دسترسی دارند تا دادههایی را که برای انجام وظیفهای که انتظار داریم که بر اساس قابلیتهای استدلال انجام دهد، واکشی کنند. ReAct در مواردی استفاده می شود که ما به LLM برای تولید فرآیند فکری متوالی نیاز داریم و بر اساس آن فرآیند داده های مورد نیاز خود را با دسترسی به منبع خارجی بازیابی می کند و پاسخ قابل اعتمادتر و واقعی تر را تولید می کند. الگوی ReAct در ارتباط با الگوی سریع زنجیرهای از فکر استفاده میشود که در آن LLMها برای وظایف تصمیمگیری بیشتر مورد نیاز هستند.
ترغیب درخت افکار - در الگوی درخت اندیشه، LLM از یک رویکرد انسانی برای حل یک کار پیچیده با استفاده از استدلال استفاده می کند. شاخه های مختلف فرآیند فکر را ارزیابی می کند و سپس نتایج را برای انتخاب راه حل بهینه مقایسه می کند.
عملیات LLM -
همانطور که از نام گفته شد LLMOps به پلت فرم عملیاتی اشاره دارد که در آن مدل زبان بزرگ (اصطلاح دیگر مدل بنیادی است) در دسترس است و استنتاج از طریق الگوی API برای برنامه کاربردی برای تعامل با هوش مصنوعی یا بخش شناختی کل گردش کار در معرض دید قرار می گیرد. LLMOps به عنوان یک بلوک اصلی دیگر برای هر برنامه Gen-AI به تصویر کشیده شده است. این محیط مشترکی است که در آن دانشمندان داده، تیم مهندسی و تیم محصول به طور مشترک مدلهای یادگیری ماشینی را میسازند، آموزش میدهند، استقرار میدهند و خط لوله داده را حفظ میکنند و مدل برای ادغام با سایر لایههای کاربردی در دسترس میشود.
سه رویکرد مختلف وجود دارد که پلتفرم LLMOps را می توان برای هر شرکتی راه اندازی کرد:
گالری مدل های بسته : در گالری مدل های بسته، پیشنهادات LLM کاملاً توسط ارائه دهندگان غول پیکر هوش مصنوعی مانند مایکروسافت، گوگل، OpenAI، Anthropic یا StableDiffusion و غیره کنترل می شود. این غول های فناوری مسئول آموزش و نگهداری مدل های خود هستند. آنها زیرساخت و همچنین معماری مدل ها و همچنین نیازهای مقیاس پذیری اجرای کل سیستم های LLMOps را مدیریت می کنند. مدلها از طریق الگوهای API در دسترس هستند، جایی که تیم برنامه کلیدهای API را ایجاد میکند و مدلها را برای استنتاج در برنامهها ادغام میکند. مزایای این نوع GenAI Ops این است که شرکتها نباید نگران حفظ هر نوع زیرساخت، مقیاسپذیری پلتفرم در هنگام افزایش تقاضا، ارتقای مدلها یا ارزیابی رفتار مدل نباشند. با این حال، در رویکردهای مدل بسته، شرکتها کاملاً به این غولهای فناوری وابسته هستند و هیچ کنترلی بر روی نوع و کیفیت دادههایی که برای آموزش یا ارتقای آموزش LLM استفاده میشوند، ندارند، گاهی اوقات ممکن است مدلها با عوامل محدودکننده نرخ مواجه شوند. زیرساخت شاهد افزایش شدید تقاضا است.
گالری مدلهای منبع باز: در این رویکرد شما با استفاده از مدلهای زبان بزرگ مدیریت شده توسط جامعه منبع باز از طریق HugginFace یا kaggle، گالری مدل خود را میسازید. در این رویکرد، شرکتها مسئول مدیریت کل زیرساخت هوش مصنوعی هستند، چه به صورت پیش فرض یا در فضای ابری. آنها نیاز به ارائه مدل های منبع باز دارند و پس از استقرار موفقیت آمیز استنباط های مدل از طریق API برای سایر مؤلفه های Enterprise برای ادغام در برنامه های خود در معرض دید قرار می گیرند. معماری داخلی مدل، اندازه پارامترها، روشهای استقرار و مجموعه دادههای پیشآموزشی برای سفارشیسازی توسط جامعه منبع باز در دسترس عموم قرار میگیرد و پس شرکتها کنترل کامل بر دسترسی، اعمال لایه تعدیل و کنترل مجوز دارند، اما در عین حال زمان کل هزینه مالکیت نیز افزایش می یابد.
رویکرد ترکیبی: امروزه رویکرد ترکیبی کاملاً رایج و ابری اصلی است
شرکتهایی مانند AWS یا Azure و GCP با ارائه گالریهای بدون سرور بر این فضا تسلط دارند که در آن هر سازمانی میتواند مدلهای منبع باز را از مخزن موجود مستقر کند یا از مدلهای بسته این شرکتها استفاده کند. Amazon Bedrock و Google Vertex پلتفرمهای ترکیبی محبوب Gen-AI هستند که میتوانید BYOM (مدل خود را بیاورید) یا از مدل بسته مانند Amazon Titan از طریق کنسول بستر یا Google Gemini از طریق Vertex استفاده کنید. رویکرد ترکیبی انعطافپذیری را برای شرکتها فراهم میکند تا کنترلهایی روی دسترسی داشته باشند و در عین حال میتواند از دسترسی مدل منبع باز با کیفیت بالا به روش مقرونبهصرفه با اجرای زیرساختهای مشترک استفاده کند.
RAG یک چارچوب محبوب برای ساخت برنامه های کاربردی هوش مصنوعی در دنیای Enterprise است. در بیشتر موارد استفاده ای که در بالا تحلیل کردیم یک چیز مشترک دارد. در بیشتر موارد، مدل زبان بزرگ نیاز به دسترسی به دادههای خارجی مانند دادههای تجاری خصوصی سازمان یا مقالاتی در مورد فرآیندها و رویههای تجاری یا برای دسترسی توسعه نرمافزار به کد منبع دارد. همانطور که میدانید، مدلهای زبان بزرگ با دادههای جمعشده در دسترس عموم از اینترنت آموزش داده میشوند. پس اگر سوالی در مورد داده های خصوصی هر سازمانی پرسیده شود، نمی تواند پاسخ دهد و توهم نشان می دهد. توهم با یک مدل زبان بزرگ زمانی اتفاق میافتد که پاسخ هر پرس و جو یا متن ورودی را نمیداند و دستورالعمل واضح نیست. در آن سناریو تمایل به ایجاد پاسخ های نامعتبر و نامربوط دارد.
RAG همانطور که از نام پیداست سعی می کند این مشکل را با کمک به LLM برای دسترسی به دانش و داده های خارجی حل کند. اجزای مختلفی که چارچوب RAG را تامین می کنند عبارتند از:
بازیابی - هدف اصلی در این فعالیت واکشی مرتبط ترین و مشابه ترین محتوا یا تکه از پایگاه داده برداری بر اساس پرس و جوی ورودی است.
یک ugmented - در این فعالیت یک اعلان به خوبی ساخته شده ایجاد می شود تا زمانی که تماس با LLM برقرار می شود، دقیقاً بداند چه خروجی باید تولید کند و زمینه ورودی چیست.
G eneration - این ناحیه ای است که LLM وارد بازی می شود. هنگامی که مدل با زمینه خوب و کافی (ارائه شده توسط "بازیابی") و دارای مراحل واضح مشخص شده (ارائه شده توسط مرحله " گفت ه") ارائه می شود، پاسخی با ارزش بالا برای کاربر ایجاد می کند.
ما مؤلفه جذب داده را با بخش بازیابی جدا کردهایم تا معماری را مقیاسپذیرتر کنیم، با این حال میتوان هر دوی دادهها و بازیابی را برای موارد استفاده با حجم کم داده ترکیب کرد.
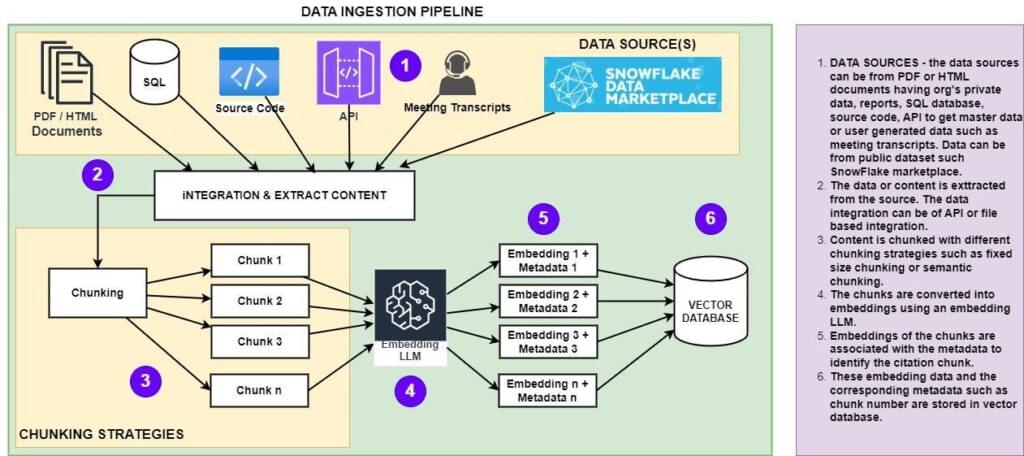
گردش کار بلع داده-
در این گردش کار، محتویات منابع دادههای مختلف مانند گزارشهای PDF، مقالات HTML یا هر داده رونوشتهایی از مکالمه با استفاده از استراتژیهای تقسیمبندی مناسب، بهعنوان مثال، تکهشدن با اندازه ثابت یا قطعهسازی آگاه از زمینه، تکه تکه میشوند. پس از تکه تکه شدن، محتوای تقسیم شده برای ایجاد جاسازی ها با فراخوانی LLMOهای مناسبی که شرکت شما راه اندازی کرده است، استفاده می شود – این می تواند یک مدل بسته باشد که دسترسی را از طریق API یا مدل منبع باز در حال اجرا در زیرساخت خود شما فراهم می کند. هنگامی که embedding ایجاد شد، در یک پایگاه داده برداری ذخیره می شود تا توسط برنامه در حال اجرا در بخش بازیابی مصرف شود.
گردش کار بازیابی داده -
در گردش کار بازیابی داده، درخواست کاربر از نظر توهین و تعدیل دیگر تحلیل می شود تا اطمینان حاصل شود که عاری از هرگونه داده سمی یا محتوای بی طرفانه است. لایه تعدیل همچنین تحلیل میکند تا اطمینان حاصل شود که کوئری دادههای حساس یا خصوصی ندارد. پس از عبور از لایه تعدیل، با فراخوانی LLM تعبیه شده به embedding تبدیل می شود. هنگامی که یک سوال به جاسازی تبدیل می شود، از این برای انجام جستجوی شباهت در پایگاه داده برداری برای شناسایی محتوای مشابه استفاده می شود. متون اصلی و همچنین جاسازی تبدیل شده برای یافتن اسناد مشابه از پایگاه داده برداری استفاده می شود.
نتایج top-k برای ساخت یک اعلان کاملاً تعریف شده با استفاده از مهندسی سریع استفاده میشود و این به مدل LLM مختلف (به طور کلی مدل دستورالعمل) داده میشود تا پاسخهای معناداری برای کاربر ایجاد کند. پاسخ ایجاد شده مجدداً از لایه تعدیل عبور داده می شود تا اطمینان حاصل شود که حاوی محتوای توهم آمیز یا پاسخ مغرضانه و همچنین عاری از هرگونه داده نفرت انگیز یا داده های خصوصی است. هنگامی که تعدیل راضی شد، پاسخ با کاربر به اشتراک گذاشته می شود.
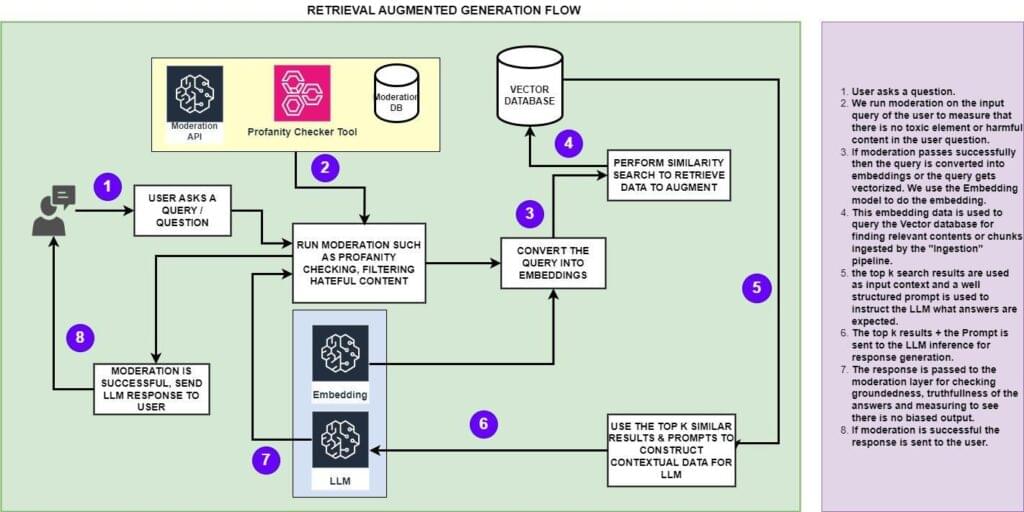
چالش ها و راه حل های RAG -
چارچوب RAG به عنوان مقرون به صرفه ترین راه برای ساخت سریع و ادغام هر گونه قابلیت Gen-AI در معماری سازمانی برجسته است. این با یک خط لوله داده یکپارچه شده است، پس نیازی به آموزش مدل ها با محتوای خارجی که مرتباً تغییر می کند وجود ندارد. برای موارد استفاده که دانش یا محتوای خارجی پویا است، RAG برای جذب و گفت ن دادهها به مدل بسیار مؤثر است. آموزش مدلی با داده های مکرر در حال تغییر بسیار گران است و باید از آن اجتناب کرد. اینها مهمترین دلایل محبوبیت RAG در بین جامعه توسعه هستند. دو فریمورک محبوب gen-ai پایتون LLamaIndex و LangChain آپشن های خارج از جعبه را برای توسعه Gen-AI با استفاده از رویکردهای RAG ارائه میکنند.
با این حال، چارچوب RAG مجموعه ای از چالش ها و مسائل خاص خود را دارد که باید در مراحل اولیه توسعه به آنها پرداخته شود تا پاسخ هایی که دریافت می کنیم با کیفیت بالا باشد.
مشکل تکهشدن: قطعهسازی بزرگترین نقش را برای سیستم RAG برای ایجاد پاسخهای مؤثر بازی میکند. هنگامی که اسناد بزرگ تکه تکه می شوند، معمولاً از الگوهای تکه تکه با اندازه ثابت استفاده می شود که اسناد با اندازه کلمه یا محدودیت اندازه کاراکتر ثابت تقسیم یا تکه تکه می شوند. وقتی یک جمله معنی دار به روش اشتباهی تکه تکه شود و در نهایت دو تکه حاوی دو جمله متفاوت با دو معنای متفاوت داشته باشیم، مشکلاتی را ایجاد می کند. هنگامی که این نوع تکهها به جاسازیها تبدیل میشوند و به پایگاه داده برداری داده میشوند، معنای معنایی را از دست میدهند و پس در طول فرآیند بازیابی قادر به تولید پاسخهای مؤثر نیست. برای غلبه بر این مسئله باید از یک استراتژی تقسیم بندی مناسب استفاده شود. در برخی از سناریوها، به جای استفاده از تکه تکه شدن با اندازه ثابت، بهتر است از تکه تکه سازی با آگاهی از متن یا قطعه بندی معنایی استفاده شود تا معنای درونی مجموعه بزرگی از اسناد حفظ شود.
مسئله بازیابی: عملکرد مدل های RAG به شدت به کیفیت اسناد متنی بازیابی شده از پایگاه داده برداری بستگی دارد. هنگامی که بازیابی نتواند مسیرهای مربوطه و صحیح را بیابد، به طور قابل توجهی توانایی مدل را برای ایجاد پاسخ های دقیق و دقیق محدود می کند. در برخی موقعیتها، بازیابیکنندهها محتوای ترکیبی با اسناد مرتبط به همراه اسناد نامربوط را واکشی میکنند و این نتایج ترکیبی باعث میشود LLM در تولید محتوای مناسب با مشکل مواجه شود، زیرا وقتی با محتوای مربوط مخلوط میشود، نمیتواند دادههای نامربوط را شناسایی کند. برای غلبه بر این مشکل، ما معمولاً از راهحلهای سفارشیشده مانند بهروزرسانی ابرداده با یک نسخه خلاصهشده از تکهای که همراه با محتوای جاسازی ذخیره میشود، استفاده میکنیم. یکی دیگر از رویکردهای رایج استفاده از روش RA-FT (بازیابی تقویت شده با تنظیم دقیق) است که در آن مدل به گونهای تنظیم شده است که بتواند محتوای نامربوط را هنگامی که با محتوای مربوطه مخلوط میشود شناسایی کند.
مشکل در وسط گم شده است : این مشکل زمانی اتفاق می افتد که LLM ها با اطلاعات بیش از حد به عنوان زمینه ورودی ارائه می شوند و همه اطلاعات مرتبط نیستند. حتی LLM های ممتاز مانند "Claude 3" یا "GPT 4" که دارای پنجره های زمینه بزرگ هستند، زمانی که با اطلاعات بیش از حد غرق می شوند و بیشتر داده ها به دستورالعمل ارائه شده توسط مهندسی سریع مربوط نمی شوند، با مشکل مواجه می شوند. به دلیل داده های ورودی بسیار زیاد، LLM نمی تواند پاسخ های مناسبی ایجاد کند. اگر اطلاعات مربوطه در ابتدای متن ورودی نباشد، عملکرد و کیفیت خروجی کاهش می یابد. این مشکل کلاسیک و آزمایش شده یکی از نقاط دردسر RAG در نظر گرفته می شود و تیم مهندسی را ملزم به ساخت دقیق مهندسی سریع و همچنین رتبه بندی مجدد محتویات بازیابی شده می کند تا مطالب مرتبط همیشه در ابتدا برای LLM باقی بماند. تولید محتوای با کیفیت بالا
همانطور که می بینید، اگرچه RAG مقرون به صرفه ترین و سریع ترین چارچوب برای طراحی و ساخت برنامه های Gen-AI است، اما در حین تولید پاسخ های با کیفیت بالا یا بهترین نتایج، از مشکلات زیادی نیز رنج می برد. کیفیت پاسخ LLM را می توان با رتبه بندی مجدد نتایج بازیابی شده از پایگاه های داده برداری، پیوست کردن محتویات خلاصه شده یا ابرداده به اسناد برای ایجاد جستجوی معنایی بهتر، و آزمایش مدل های تعبیه شده با ابعاد مختلف، تا حد زیادی بهبود بخشید. همراه با آن تکنیک های پیشرفته و ادغام برخی از رویکردهای ترکیبی مانند RA-FT، عملکرد RAG افزایش می یابد.
یک نمونه پیادهسازی RAG با استفاده از Langchain
در این بخش ما در ساخت یک برنامه مبتنی بر پارچه کوچک با استفاده از Langchain ، Database Chrima و API AI افتتاح خواهیم کرد. ما از پایگاه داده Chroma به عنوان پایگاه داده وکتور در حافظه خود استفاده خواهیم کرد که یک بانک اطلاعاتی سبک برای ساخت MVP (حداقل محصول قابل دوام) یا POC (اثبات مفهوم) برای تجربه این مفهوم است. Chromadb هنوز برای برنامه های درجه تولید ساختمان توصیه نمی شود.
من به طور کلی از Google Coll برای اجرای سریع هر کد پایتون استفاده می کنم. در صورت تمایل می توانید از همان استفاده کنید یا کد زیر را در Python IDE مورد علاقه خود امتحان کنید ..
مرحله 1: کتابخانه ها / ماژول های پایتون را نصب کنید
| Langchain را نصب کنید PIP نصب Langchain-Community Langchain-Core ! Pip نصب -u langchain -openai ! PIP نصب لنگچین کروما |
API OpenAi خدماتی است که به توسعه دهندگان امکان دسترسی و استفاده از مدل های بزرگ زبان OpenAI (LLMS) را در برنامه های خود می دهد.
Langchain یک چارچوب منبع باز است که ساخت برنامه های LLM را برای توسعه دهندگان آسان می کند.
Chromadb یک بانک اطلاعاتی وکتور منبع باز است که به طور خاص برای ذخیره و مدیریت بازنمایی بردار داده های متن طراحی شده است.
"!" از اظهارات PIP اگر مستقیماً کد را از سریع فرمان خود اجرا می کنید.
مرحله 2: اشیاء مورد نیاز را وارد کنید
| # ماژول های لازم را برای پردازش متن ، تعامل مدل و مدیریت پایگاه داده وارد کنید از langchain.text_splitter import RecursiveCharacterTextSplitter از langchain.chat_models ChatOpenAI را وارد کنید از langchain.prompts وارد PromptTemplate از langchain.chains واردات RetrievalQA از Langchain_openai واردات Openaiembeddings ، Chatopenai از Chroma واردات Langchain_chroma واردات Chromadb واردات pprint # توضیحات استفاده از ماژول: |
مرحله 3: مصرف داده ها
| input_texts = [ "هوش مصنوعی (AI) در حال تغییر صنایع در سراسر جهان است. " "AI ماشین ها را قادر می سازد از تجربه یاد بگیرند و کارهای انسانی مانند را انجام دهند." "در مراقبت های بهداشتی ، الگوریتم های هوش مصنوعی می توانند به تشخیص بیماری هایی با دقت بالا کمک کنند." "اتومبیل های خودران از AI برای حرکت در خیابان ها و جلوگیری از موانع استفاده می کنند." "Chatbots با قدرت AI پشتیبانی مشتری را ارائه می دهد و تجربه کاربر را ارتقا می بخشد." "تجزیه و تحلیل پیش بینی شده توسط هوش مصنوعی به مشاغل کمک می کند تا روند پیش بینی و تصمیم گیری های محور داده را انجام دهند." "هوش مصنوعی همچنین از طریق تجارت خودکار و تشخیص کلاهبرداری در زمینه امور مالی متحول می شود." "پردازش زبان طبیعی (NLP) به هوش مصنوعی اجازه می دهد تا زبان انسانی را درک و پاسخ دهد." "در ساخت ، سیستم های هوش مصنوعی باعث افزایش کارایی و کنترل کیفیت می شوند." "هوش مصنوعی در کشاورزی برای بهینه سازی عملکرد محصول و نظارت بر سلامت خاک استفاده می شود." "آموزش توسط هوش مصنوعی از طریق سیستم های یادگیری شخصی و آموزش هوشمند تقویت می شود." "روباتیک های AI محور وظایفی را انجام می دهند که برای انسان خطرناک یا یکنواخت است. " "هوش مصنوعی در مدل سازی آب و هوا و نظارت بر محیط زیست به مبارزه با تغییرات آب و هوا کمک می کند." "صنایع سرگرمی از هوش مصنوعی برای ایجاد محتوا و سیستم های توصیه استفاده می کنند." "فن آوری های هوش مصنوعی برای توسعه شهرهای هوشمند اساسی هستند." "ادغام هوش مصنوعی در مدیریت زنجیره تأمین ، تدارکات و کنترل موجودی را افزایش می دهد." "تحقیقات AI همچنان به مرزها در یادگیری ماشین و یادگیری عمیق فشار می آورد." "ملاحظات اخلاقی در توسعه هوش مصنوعی برای اطمینان از انصاف و شفافیت بسیار مهم است. " "هوش مصنوعی در امنیت سایبری به تشخیص و پاسخ دادن به تهدیدات در زمان واقعی کمک می کند." "آینده هوش مصنوعی پتانسیل پیشرفت ها و برنامه های حتی بیشتر در زمینه های مختلف را دارد." ] # تمام عناصر موجود در فهرست را در یک رشته واحد با Newline به عنوان جداکننده ترکیب کنید # "recursivecharactertextsplitter" را انجام دهید تا داده ها بتوانند یک شیء "page_content" داشته باشند chunk_texts = text_splitter.create_document ([combined_text]) |
مرحله 4: تعبیه و ذخیره در پایگاه داده Chroma
| # API تعبیه شده را با کلید OpenAi API OpenAI_API_KEY = "SK-Proj-Rekm9uelh5ozqf533c2St3blbkfjtufxt2nm113b28lztjd" آغاز کنید . " تعبیه = Openaiembeddings (OpenAI_API_KEY = OpenAI_API_KEY) # دایرکتوری برای ادامه پایگاه داده Chroma # اسناد و تعبیه ها را در پایگاه داده محلی Chroma ذخیره کنید # پایگاه داده Chroma را از فهرست محلی بارگیری کنید # آزمایش تنظیمات را با یک پرس و جو نمونه آزمایش کنید # اسناد بازیابی شده را چاپ کنید |
مرحله 5: اکنون ما مهندسی سریع را انجام خواهیم داد تا به LLM آموزش دهیم که چه چیزی را بر اساس زمینه ای که عرضه می کنیم تولید کنیم.
| # الگوی سریع را تعریف کنید الگوی = "" " نقش: شما یک دانشمند هستید. ورودی: از زمینه زیر برای پاسخ به سوال استفاده کنید. زمینه: {context} سوال: {سوال} مراحل: به مودبانه پاسخ دهید و بگویید ، "امیدوارم که شما خوب باشید" ، سپس روی پاسخ به این سوال تمرکز کنید. انتظار: پاسخ های دقیق و مرتبط را بر اساس زمینه ارائه شده ارائه دهید. باریک کردن: 1. پاسخ های خود را به متن داده شده محدود کنید. فقط روی سؤالات مربوط به هوش مصنوعی تمرکز کنید. 2. اگر جواب را نمی دانید ، فقط بگویید ، "متاسفم ... من نمی دانم." 3. اگر کلمات یا سؤالاتی در خارج از متن هوش مصنوعی وجود دارد ، فقط بگویید "بیایید در مورد هوش مصنوعی صحبت کنیم." پاسخ: """ # {زمینه} داده های حاصل از بردارهای پایگاه داده است که شباهت هایی با سوال دارند # الگوی سریع را ایجاد کنید |
مرحله ششم: استنتاج LLM را پیکربندی کنید و بازیابی را انجام دهید
# مقادیر پارامتر را تعریف کنید دما = 0.2 param = { "top_p": 0.4 ، "فرکانس_پنیت": 0.1 ، "requent_penalty": 0.7 } # با پارامترهای مشخص شده یک شی LLM ایجاد کنید # با پارامترهای مشخص شده و الگوی سریع یک شیء بازیابی ایجاد کنید # تنظیمات را با یک پرس و جو نمونه نمونه تست کنید = "چگونه AI صنعت را تغییر می دهد؟" # اسناد بازیابی شده و پاسخ را چاپ کنید |
خروجی نهایی -
| [ سند (page_content = 'هوش مصنوعی (AI) در حال تغییر صنایع در سراسر جهان است. ") سند (page_content = '\ n آینده AI پتانسیل پیشرفت ها و برنامه های حتی بیشتر در زمینه های مختلف را دارد.') سند (page_content = '\ nin تولید ، سیستم های AI باعث افزایش کارآیی و کنترل کیفیت می شوند.) سند (page_content = '\ nai همچنین در زمینه مالی از طریق تجارت خودکار و تشخیص کلاهبرداری انقلابی می کند.') ] |
REARIVALQA روشی برای پاسخگویی به وظایف است که از یک فهرست برای بازیابی اسناد مربوطه یا قطعه های متنی استفاده می کند ، مناسب برای برنامه های ساده پاسخ به سؤال. Retrievalqachain ترکیب Retriever و یک زنجیره QA است. از آن برای واکشی اسناد از رتریور و سپس استفاده از زنجیره QA برای پاسخ به سؤالات بر اساس اسناد بازیابی شده استفاده می شود.
در پایان ، یک معماری مرجع قوی یک الزام اساسی برای سازمانهایی است که یا در حال ساخت راه حل های Gen-AI هستند یا فکر می کنند اولین قدم را انجام دهند. این به ساخت راه حل های هوش مصنوعی ایمن و سازگار کمک می کند. یک معماری مرجع به خوبی در این زمینه می تواند با پیروی از اصطلاحات استاندارد ، بهترین شیوه ها و رویکردهای معماری IT ، به تیم های مهندسی در حرکت در پیچیدگی های توسعه AI مولد کمک کند. این امر باعث افزایش استقرار فناوری می شود ، قابلیت همکاری را بهبود می بخشد و پایه و اساس محکمی برای اجرای مراحل حاکمیت و تصمیم گیری فراهم می کند. از آنجا که تقاضا برای هوش مصنوعی تولیدی همچنان در حال افزایش است ، بنگاه هایی که در توسعه سرمایه گذاری می کنند و به یک معماری مرجع جامع پایبند هستند ، در موقعیت بهتری برای برآورده کردن الزامات نظارتی ، بالا بردن اعتماد مشتری ، کاهش خطرات و ایجاد نوآوری در خط مقدم خود قرار می گیرند. صنایع مربوطه
برچسبها
|
|





ارسال نظر