شروع کار با window.ai Prompt API کروم


نحوه استفاده از API کروم پرامپت
کروم ۱۳۸+ (کانال توسعهدهندگان یا کانال قناری) را روی دستگاهی با پردازنده گرافیکی پشتیبانیشده نصب کنید .
پرچمهای optimization-guide-on-device-model و prompt-api-for-gemini-nano را در chrome://flags فعال کنید .
تأیید کنید که دانلود مدل Gemini Nano در chrome://on-device-internals تکمیل شده است.
با استفاده از LanguageModel.availability() در دسترس بودن را بررسی کنید و هر چهار مقدار وضعیت را مدیریت کنید.
یک جلسه از طریق LanguageModel.create() با اعلان سیستم و پارامترهای اختیاری ایجاد کنید .
برای پاسخهای کامل، با استفاده از session.prompt() یا برای خروجی بلادرنگ با استفاده از session.promptStreaming() پیامها را ارسال کنید .
قبل از هر فراخوانی، با استفاده از session.countPromptTokens() و session.tokensLeft ، میزان استفاده از توکن را زیر نظر داشته باشید .
جلسه را در یک بلوک finally از بین ببرید تا منابع GPU و RAM آزاد شود.
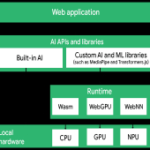
رابط برنامهنویسی کاربردی کروم پرومپت (Chrome Prompt API) به توسعهدهندگان فرانتاند این امکان را میدهد که استنتاج LLM را مستقیماً در مرورگر و بدون نیاز به زیرساخت سرور و بدون خروج دادههای کاربر از دستگاه اجرا کنند. این رابط برنامهنویسی کاربردی به Gemini Nano که روی دستگاه اجرا میشود متصل میشود و یک رابط جاوا اسکریپت مبتنی بر promise و استریمینگ را برای تولید متن ارائه میدهد. این رابط در کروم ۱۳۸+ (کانال توسعهدهندگان یا Canary) و در پشت یک جفت پرچم ویژگی (feature flag) ارائه میشود و در حال حاضر کار میکند.
این آموزش، تمام مراحل لازم برای فعال کردن پرچمها تا ساخت یک ابزار خلاصهسازی کارآمد را پوشش میدهد.
فهرست مطالب
رابط برنامهنویسی کاربردی کروم پرامپت چیست؟
ابتکار هوش مصنوعی داخلی کروم، چندین قابلیت هوش مصنوعی روی دستگاه را مستقیماً در مرورگر قرار میدهد. رابط برنامهنویسی کاربردی (API) Prompt که گاهی اوقات به عنوان API مدل زبان (Language Model API) نیز شناخته میشود، رابط اصلی تولید متن در این ابتکار عمل است. این رابط تحت شیء سراسری LanguageModel قرار دارد و روشی استاندارد برای ارسال دستورات زبان طبیعی به Gemini Nano، یک LLM سبک که کاملاً روی دستگاه کاربر اجرا میشود، ارائه میدهد. در کد، آن را مستقیماً به عنوان LanguageModel (مثلاً LanguageModel.create() ) ارجاع دهید، نه از طریق window.ai.LanguageModel .
از آنجا که استنتاج روی دستگاه اتفاق میافتد، هیچ رفت و برگشت شبکهای برای تولید وجود ندارد. توسعه محلی نیازی به کلید API ندارد، اگرچه کاربران Origin Trial به جای آن یک توکن آزمایشی را مدیریت میکنند. این مدل به عنوان بخشی از زیرساخت بهروزرسانی کامپوننت کروم ارائه میشود و API در کروم ۱۳۸ و بالاتر (کانال توسعه یا Canary) در پشت پرچمهای chrome://flags/#optimization-guide-on-device-model و chrome://flags/#prompt-api-for-gemini-nano .
از آنجا که استنتاج روی دستگاه اتفاق میافتد، هیچ رفت و برگشت شبکهای برای تولید وجود ندارد. توسعه محلی نیازی به کلید API ندارد.
توسعهدهندگان همچنین میتوانند برای آزمایشهای گستردهتر، از طریق نسخه آزمایشی Origin به آن دسترسی داشته باشند. برای اطلاع از در دسترس بودن فعلی، صفحه Chrome Origin Trials را بررسی کنید و توکن را از طریق <meta http-equiv="origin-trial" content="YOUR_TOKEN"> در HTML خود تزریق کنید. در مسیر استانداردها، این API یک پیشنهاد از سوی گروه جامعه انکوباتور وب W3C (WICG) است که هدف صریح آن استانداردسازی بین مرورگرها در طول زمان است.
پیشنیازها و تنظیمات محیطی
الزامات سیستم
کروم ۱۳۸ یا جدیدتر در کانال Dev یا Canary. این پرچمها در Chrome Stable نمایش داده نمیشوند. از chrome.com/chrome/dev یا google.com/chrome/canary دانلود کنید.
ویندوز، macOS، لینوکس یا ChromeOS. دامنه پشتیبانی بسته به نسخه متفاوت است.
مدل روی دستگاه به یک پردازنده گرافیکی پشتیبانیشده و رم کافی برای نگهداری مدل در حافظه نیاز دارد. حداقلهای دقیقی منتشر نشده است. برای بررسی اینکه آیا دستگاه شما واجد شرایط است یا خیر، به chrome://on-device-internals بروید. اگر واجد شرایط نباشد، بررسی در دسترس بودن، "unavailable" را برمیگرداند.
دانلود این مدل در نسخههای اولیه کروم ۱۳۸ تقریباً ۱.۷ گیگابایت طول میکشد. برای اطلاع از حجم فعلی نسخه خود، chrome://on-device-internals را بررسی کنید.
برای دانلود اولیه مدل، اتصال به شبکه مورد نیاز است. استنتاجهای بعدی کاملاً آفلاین هستند.
فعال کردن پرچمهای کروم مورد نیاز
کروم (نسخهی توسعهدهندگان یا Canary، نسخهی ۱۳۸ به بالا) را باز کنید و به chrome://flags بروید. این دو پرچم (flags) را جستجو و فعال کنید:
optimization-guide-on-device-model — روی «Enabled BypassPerfRequirement» تنظیم شده باشد (این گزینه بررسیهای سختافزاری را در طول توسعه کاهش میدهد).
prompt-api-for-gemini-nano — روی «فعال» تنظیم شده است.
وقتی از شما خواسته شد، کروم را دوباره راهاندازی کنید.
تأیید کنید که مدل دانلود شده است
پس از فعال کردن پرچمها، کروم شروع به دانلود Gemini Nano در پسزمینه میکند. دانلود بسته به سرعت اتصال، چند دقیقه طول میکشد.
برای تأیید پیشرفت، به chrome://on-device-internals بروید. در این صفحه، به دنبال فیلد وضعیت مدل باشید. وضعیت "نصب شده" یا مسیر فایل نمایش داده شده، تأیید میکند که دانلود با موفقیت انجام شده است. از طرف دیگر، فراخوانی بررسی در دسترس بودن (که در ادامه توضیح داده خواهد شد) میتواند در صورت عدم شروع دانلود، آن را آغاز کند.
بررسی مرورگر و در دسترس بودن مدل
هر نصب کرومی این مدل را آماده ندارد. ممکن است دستگاه نیازهای سختافزاری را برآورده نکند، دانلود هنوز در حال انجام باشد، یا پرچمها غیرفعال باشند. تنزل تدریجی ضروری است.
متد LanguageModel.availability() یکی از چهار رشته زیر را برمیگرداند: "available" (مدل آماده است)، "downloadable" (مدل میتواند دریافت شود اما هنوز دریافت نشده است)، "downloading" (در حال دریافت) یا "unavailable" (در این دستگاه/مرورگر پشتیبانی نمیشود).
async function checkPromptAPI ( ) {
if ( ! ( "LanguageModel" in self ) ) { return { status : "unavailable" , message : "Prompt API not supported in this browser." } ; }
const availability = await LanguageModel . availability ( ) ;
const messages = { available : "Model is ready. You can start prompting." , downloadable : "Model is available for download. Creating a session will trigger it." , downloading : "Model is currently downloading. Please wait." , unavailable : "Model is not available on this device." } ;
if ( ! messages [ availability ] ) { console . warn ( ` Unexpected availability status: " ${ availability } " ` ) ; }
return { status : availability , message : messages [ availability ] || "Unknown status." } ; } این قطعه کد مستقل، توضیحی است - بررسی در دسترس بودن را به صورت جداگانه نشان میدهد. برنامه کامل در آموزش زیر، همین منطق را در تابع init() خود ادغام میکند، بنابراین نیازی به استفاده از هر دو نیست.
بررسی "LanguageModel" in self first از خطاهای ارجاع در مرورگرهایی که اصلاً از API آگاهی ندارند، جلوگیری میکند.
ایجاد یک جلسه مدل زبان
تمام تعاملات با API مربوط به Prompt از طریق یک شیء session جریان مییابد که از طریق LanguageModel.create() ایجاد شده است. یک session پیکربندی مدل، وضعیت مکالمه و بودجه توکن را کپسولهسازی میکند.
گزینههای کلیدی ارسالی به create() :
systemPrompt : محدودیتهای شخصیتی و رفتاری مدل را تنظیم میکند.
temperature : تصادفی بودن را کنترل میکند (مقادیر پایینتر، خروجی متمرکزتر و کمتنوعتری تولید میکنند؛ مقادیر بالاتر، خلاقیت را افزایش میدهند).
topK : نمونهگیری توکن را به K کاندیدای برتر محدود میکند. این پارامترها در صورت حذف، از پیشفرضهای مدل استفاده میکنند.
signal : یک AbortSignal برای پشتیبانی از لغو (همچنین توسط promptStreaming() برای لغو به ازای هر تماس پذیرفته میشود).
const session = await LanguageModel . create ( { systemPrompt : "You are a helpful summarizer. Respond in two sentences or fewer." } ) ;درک محدودیتهای توکن
هر جلسه سه ویژگی برای مدیریت زمینه ارائه میدهد: maxTokens (کل پنجره زمینه)، tokensSoFar (توکنهای مصرفشده توسط اعلان سیستم و تاریخچه مکالمه) و tokensLeft (ظرفیت باقیمانده). پنجره زمینه بر اساس نسخه مدل متفاوت است؛ session.maxTokens در زمان اجرا برای مقدار معتبر بخوانید (معمولاً حدود ۶۱۴۴ توکن در نسخههای اولیه). برای ورودیهای طولانیتر، بررسی اولیه تعداد توکنها با session.countPromptTokens(text) قبل از ارسال اعلان، از کوتاهسازی یا خطاهای خاموش جلوگیری میکند.
ارسال پیامهای فوری و مدیریت پاسخها
پاسخ غیر استریمینگ
سادهترین مسیر: فراخوانی session.prompt() با یک رشته. این متد یک promise را برمیگرداند که به متن کامل تولید شده تبدیل میشود.
const result = await session . prompt ( "Summarize this paragraph: The rapid growth of on-device AI..." ) ; console . log ( result ) ;این کار تا زمان تولید کامل پاسخ متوقف میشود، که برای خروجیهای کوتاه خوب کار میکند اما برای نسلهای طولانیتر باعث ایجاد تأخیر قابل توجه در رابط کاربری میشود.
پاسخ استریمینگ
برای رندرینگ بلادرنگ، session.promptStreaming() یک ReadableStream برمیگرداند. API کل پاسخ انباشته شده را به عنوان هر بخش برمیگرداند، نه یک دلتا. این رفتار را در نسخه Chrome خود بررسی کنید، زیرا ممکن است معنای جریان تغییر کند. کد برنامه زیر شامل منطق تشخیص خودکار برای هر دو حالت است.
const stream = session . promptStreaming ( "Summarize this paragraph: The rapid growth of on-device AI..." ) ;
let accumulated = "" ; let isCumulative = null ; let chunkIndex = 0 ;
for await ( const chunk of stream ) { chunkIndex ++ ; if ( chunkIndex === 2 ) {
isCumulative = chunk . startsWith ( accumulated ) ; } if ( isCumulative === false ) { accumulated += chunk ; outputEl . textContent = accumulated ; } else {
outputEl . textContent = chunk ; accumulated = chunk ; } } اگر تکهها تجمعی باشند، اختصاص مستقیم chunk به textContent یک جلوه ماشین تحریر روان و بدون هیچ منطق تجمع رشتهای ایجاد میکند. اگر میدانید که تکهها در نسخه کروم شما دلتا هستند، به outputEl.textContent += chunk بروید.
هدف: یک برنامه تک صفحهای مینیمال که در آن کاربران متن را در یک ناحیه متنی پیست میکنند و خلاصهای از آن را که به صورت جریانی در صفحه نمایش داده میشود، دریافت میکنند. بدون ابزار ساخت. بدون وابستگی.
هدف: یک برنامه تک صفحهای مینیمال که در آن کاربران متن را در یک ناحیه متنی پیست میکنند و خلاصهای از آن را که به صورت جریانی در صفحه نمایش داده میشود، دریافت میکنند. بدون ابزار ساخت. بدون وابستگی.
ساختار HTML
موارد زیر را با نام index.html ذخیره کنید:
<! DOCTYPE html > < html lang = " en " > < head > < meta charset = " UTF-8 " > < meta name = " viewport " content = " width=device-width, initial-scale=1.0 " > < title > On-Device Summarizer </ title > < style >
body { font-family : system-ui , sans-serif ; max-width : 640 px ; margin : 2 rem auto ; padding : 0 1 rem ; } textarea { width : 100 % ; height : 150 px ; margin-bottom : 0.5 rem ; } #output { white-space : pre-wrap ; padding : 1 rem ; background : #f5f5f5 ; min-height : 3 rem ; margin-top : 1 rem ; } #status { font-size : 0.85 rem ; color : #666 ; } button { margin-right : 0.5 rem ; } </ style > </ head > < body > < h1 > On-Device Summarizer </ h1 > < span id = " status " > Checking model availability... </ span > < textarea id = " input " maxlength = " 100000 " placeholder = " Paste text to summarize... " > </ textarea > < button id = " summarize " disabled > Summarize </ button > < button id = " cancel " hidden > Cancel </ button > < div id = " output " > </ div > < script src = " app.js " > </ script > </ body > </ html >منطق جاوا اسکریپت
کد زیر را با نام app.js و در همان پوشهی index.html ذخیره کنید:
const inputEl = document . getElementById ( "input" ) ; const outputEl = document . getElementById ( "output" ) ; const statusEl = document . getElementById ( "status" ) ; const summarizeBtn = document . getElementById ( "summarize" ) ; const cancelBtn = document . getElementById ( "cancel" ) ;
const SYSTEM_PROMPT = "You are a helpful summarizer. Respond in two sentences or fewer." ; const INPUT_MAX_LENGTH = 50_000 ; const SESSION_TIMEOUT_MS = 30_000 ;
let controller = null ; let isRunning = false ;
function withTimeout ( promise , ms , label ) { const timer = new Promise ( ( _ , reject ) => setTimeout ( ( ) => reject ( new Error ( ` ${ label } timed out after ${ ms } ms ` ) ) , ms ) ) ; return Promise . race ( [ promise , timer ] ) ; }
async function init ( ) { if ( ! ( "LanguageModel" in self ) ) { statusEl . textContent = "Prompt API not supported. Enable flags in chrome://flags." ; return ; }
try { const availability = await LanguageModel . availability ( ) ; if ( availability === "available" ) { statusEl . textContent = "Model ready." ; summarizeBtn . disabled = false ; } else if ( availability === "downloadable" || availability === "downloading" ) { statusEl . textContent = ` Model status: ${ availability } . Please wait for the download to finish, then refresh this page. ` ; } else { statusEl . textContent = "Model unavailable on this device." ; } } catch ( err ) { console . error ( "LanguageModel.availability() failed:" , err ) ; statusEl . textContent = "Could not check model status. Reload the page to retry." ; } }
async function summarize ( ) { if ( isRunning ) return ; isRunning = true ;
const text = inputEl . value . trim ( ) ; if ( ! text || text . length > INPUT_MAX_LENGTH ) { outputEl . textContent = text . length > INPUT_MAX_LENGTH ? "Input too large. Please shorten your text." : "" ; isRunning = false ; return ; }
summarizeBtn . disabled = true ; cancelBtn . hidden = false ; outputEl . textContent = "" ;
const localController = new AbortController ( ) ; controller = localController ; let session = null ;
try { session = await withTimeout ( LanguageModel . create ( { systemPrompt : SYSTEM_PROMPT , signal : localController . signal } ) , SESSION_TIMEOUT_MS , "Session creation" ) ;
const tokenCount = await session . countPromptTokens ( text ) ; statusEl . textContent = ` Input tokens: ${ tokenCount } | Budget: ${ session . tokensLeft } remaining ` ;
if ( tokenCount > session . tokensLeft ) { outputEl . textContent = "Input exceeds token budget. Please shorten your text." ; return ; }
const stream = session . promptStreaming ( ` Summarize this:
${ text } ` , { signal : localController . signal } ) ;
let accumulated = "" ; let isCumulative = null ; let chunkIndex = 0 ;
for await ( const chunk of stream ) { chunkIndex ++ ; if ( chunkIndex === 2 ) { isCumulative = chunk . startsWith ( accumulated ) ; } if ( isCumulative === false ) { accumulated += chunk ; outputEl . textContent = accumulated ; } else { outputEl . textContent = chunk ; accumulated = chunk ; } }
const used = session . tokensSoFar ; const max = session . maxTokens ; statusEl . textContent = ` Tokens used: ${ used } / ${ max } ` ; } catch ( err ) { if ( err . name === "AbortError" ) { outputEl . textContent = "[Generation cancelled]" ; } else { console . error ( "Summarization failed:" , err ) ; outputEl . textContent = "Something went wrong. Check the console for details." ; } statusEl . textContent = "Ready." ; } finally { if ( session ) { session . destroy ( ) ; } isRunning = false ; summarizeBtn . disabled = false ; cancelBtn . hidden = true ; controller = null ; } }
summarizeBtn . addEventListener ( "click" , summarize ) ; cancelBtn . addEventListener ( "click" , ( ) => controller ?. abort ( ) ) ;
init ( ) ;بهبود تجربه کاربری (UX)
اسکریپت بالا چندین مورد مربوط به تجربه کاربری را که فراتر از سیمکشی اولیه API هستند، مدیریت میکند.
پرچم isRunning به عنوان یک محافظ ورود مجدد عمل میکند. این پرچم از فراخوانیهای همپوشانی summarize() جلوگیری میکند، حتی اگر کاربر قبل از اینکه اولین await اجرا را به حالت تعلیق درآورد، به سرعت روی دکمه کلیک کند. این امر تضمین میکند که فقط یک جلسه در یک زمان فعال است.
لغو از طریق سیمکشی AbortController انجام میشود. دکمه لغو، controller.abort() را فراخوانی میکند و از آنجا که localController در هر فراخوانی محدود میشود، لغو همیشه session صحیح در حین اجرا را هدف قرار میدهد. ایجاد session همچنین در یک timeout قرار میگیرد تا دانلود یا مقداردهی اولیه مدل متوقف شده، رابط کاربری را به طور نامحدود قفل نکند. اگر timeout فعال شود، خطا گرفته شده و دکمه دوباره فعال میشود.
قبل از هرگونه فراخوانی API، محافظ اندازه ورودی، چسباندنهای بسیار بزرگ را رد میکند و از معطل ماندن تب در شمارش توکن جلوگیری میکند. پس از اینکه ورودی از این بررسی عبور کرد، countPromptTokens() تأیید میکند که متن در محدوده بودجه توکن باقیمانده جلسه قرار میگیرد و از استنتاج بیهوده روی ورودیهایی که به هر حال با شکست مواجه میشوند، جلوگیری میکند.
حلقهی استریمینگ با مقایسهی بخش دوم در مقابل بخش اول، تشخیص میدهد که آیا API تکههای تجمعی یا دلتا منتشر میکند یا خیر، سپس رندرینگ را بر اساس آن تنظیم میکند. رشتههای خطای خام API برای اشکالزدایی به کنسول میروند، در حالی که ناحیهی خروجی یک پیام عمومی برای کاربر نشان میدهد. در نهایت، session.destroy() در بلوک finally در هر مسیر خروج (موفقیت، خطا یا لغو) اجرا میشود و منابع GPU و RAM را آزاد میکند.
نکتهای در مورد وضعیت دانلود مدل : اگر مدل هنگام اولین بار بارگذاری صفحه هنوز در حال دانلود باشد، دکمه خلاصهسازی غیرفعال خواهد ماند. پس از اتمام دانلود، صفحه را رفرش کنید (برای فعال کردن دکمه، پیشرفت را در chrome://on-device-internals بررسی کنید).
نکات، محدودیتها و بهترین شیوهها
برای مکالمات چند نوبتی، به جای ایجاد مجدد یک جلسه از ابتدا، یک جلسه موجود را با session.clone() کپی کنید. این کار پیکربندی اعلان سیستم را بدون مقداردهی مجدد جلسه حفظ میکند:
const cloned = await session . clone ( ) ; توجه داشته باشید که وضعیت دقیق حفظ شده توسط clone() (مثلاً اینکه آیا تاریخچه مکالمات منتقل میشود یا فقط پیکربندی اعلان سیستم) باید در برابر رفتار فعلی API تأیید شود.
وقتی دیگر به یک نشست نیازی نیست، تابع session.destroy() را فراخوانی کنید. میزان مصرف حافظه Gemini Nano قابل توجه است؛ برای مشاهده میزان استفاده از حافظه به ازای هر تب پس از ایجاد نشست، Chrome Task Manager (Shift+Esc) را بررسی کنید. نشستهای یتیم این منابع را حفظ میکنند. همیشه destroy() را در یک بلوک finally قرار دهید تا از پاکسازی مسیرهای خطا و لغو اطمینان حاصل شود.
همیشه قبل از ارسال اعلان، با session.countPromptTokens(text) از قبل بررسی کنید. پنجره context به سرعت با اسناد طولانیتر پر میشود. برای اطلاع از بودجه دقیق، session.maxTokens در زمان اجرا بخوانید.
تمام پردازشها روی دستگاه باقی میمانند. هیچ دادهای در طول استنتاج به سرورهای خارجی منتقل نمیشود، که این امر این را برای برنامههایی که محتوای حساس کاربر را مدیریت میکنند، مناسب میکند.
این مدل فقط از زبان انگلیسی پشتیبانی میکند، فقط متن را مدیریت میکند (بدون تصویر یا صدا) و منحصراً در کروم اجرا میشود. کیفیت آن برای وظایف متمرکز تک نوبتی مانند خلاصهسازی، فرمولبندی مجدد و طبقهبندی مناسب است. درخواستها یا درخواستهای زنجیرهای چند مرحلهای که بیش از تقریباً ۲۰۰۰ توکن ورودی دارند، به طور قابل توجهی کاهش مییابند و تولید کد بسیار فراتر از آن چیزی است که Gemini Nano به طور قابل اعتمادی مدیریت میکند.
تمام پردازشها روی دستگاه باقی میمانند. هیچ دادهای در طول استنتاج به سرورهای خارجی منتقل نمیشود، که این امر این را برای برنامههایی که محتوای حساس کاربر را مدیریت میکنند، مناسب میکند.
قدم بعدی برای هوش مصنوعی داخلی در مرورگر چیست؟
رابط برنامهنویسی کاربردی سریع (Prompt API) بخشی از یک تلاش گستردهتر است. رابطهای برنامهنویسی کاربردی (API) همراه در حال توسعه شامل رابط برنامهنویسی کاربردی خلاصهکننده (Summarizer API) و رابط برنامهنویسی کاربردی نویسنده و بازنویس (Writer and Rewriter API) هستند که هر دو وظایف خاصی را با رابطهای کاربری بهینهشده هدف قرار میدهند. یک رابط برنامهنویسی کاربردی مترجم (Translator API) و یک رابط برنامهنویسی کاربردی تشخیص زبان (Language Detector API) نیز در حال انجام هستند.
مستندات کامل در سایت مستندات هوش مصنوعی داخلی کروم موجود است. WICG پیشنهادات را در گیتهاب دنبال میکند. این API در حال توسعه فعال است و الگوهای اصلی LanguageModel.create() و session.prompt() برای توسعه محلی و نمونهسازی اولیه امروزه کار میکنند.
خودتان امتحان کنید : بلوک HTML را با نام index.html و بلوک جاوا اسکریپت را با نام app.js در یک پوشه ذخیره کنید. آنها را با یک سرور محلی (مثلاً npx serve . یا VS Code Live Server) ارائه دهید - index.html مستقیماً از طریق file:// باز نکنید، زیرا ممکن است بارگیری اسکریپت با شکست مواجه شود. پرچمهای Chrome را فعال کنید و یک خلاصهساز روی دستگاه را بدون هیچ وابستگی اجرا کنید. نیازی به کلید API نیست.
برچسبها
|
|



ارسال نظر