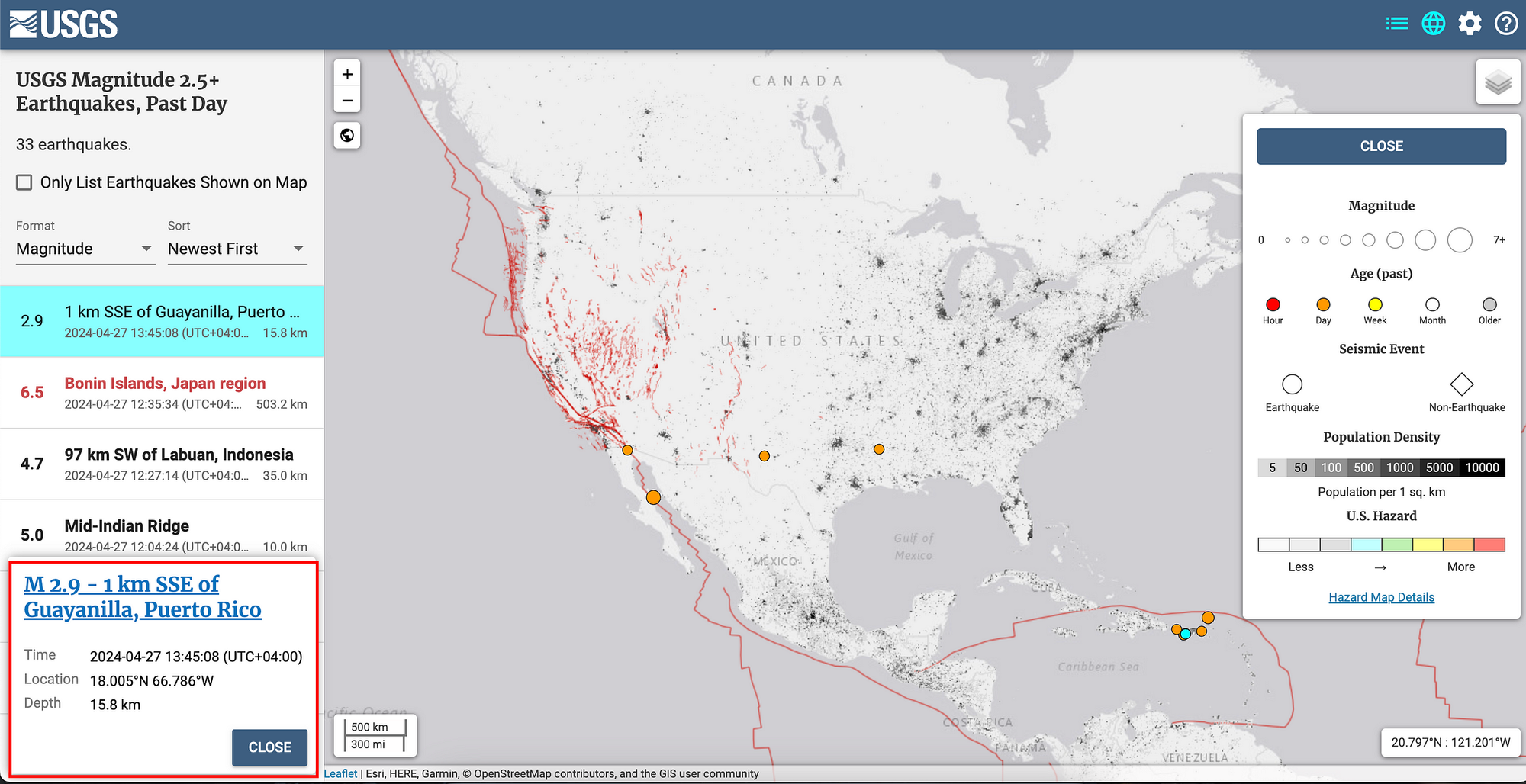
رمزگشایی آشوب: تصادفی واقعی چگونه در مهندسی نرم افزار کار می کند

درک تصادفی بودن
وقتی کلمه "تصادفی" را می شنوید، معمولاً چه چیزی به ذهن شما خطور می کند؟ شما ممکن است به چیزی ناملموس فکر کنید، یک مفهوم انتزاعی بدون شکل یا شکل خاص - تصادفی است.
اما تصادفی بودن بسیار بیشتر از یک ایده انتزاعی است – این یک جنبه اساسی از تصمیمات و انتخاب های روزانه ما است. خواه تصمیم گیری برای خوردن صبحانه باشد یا انتخاب یک عدد از 1 تا 10 در یک بازی، تصادفی بودن نقش مهمی ایفا می کند.
تصادفی بودن فقط در مورد غیرقابل پیش بینی بودن نیست. همچنین در مورد فقدان الگو یا پیش بینی پذیری در رویدادها است. به عنوان مثال، هنگامی که یک سکه پرتاب می کنید، نتیجه سرها یا دم ها تصادفی است زیرا به همان اندازه محتمل و غیرقابل پیش بینی است.
چرا تصادفی بودن در مهندسی نرم افزار مهم است؟
این مفهوم در زمینه مهندسی نرم افزار بسیار مهم است، جایی که تولید تصادفی واقعی می تواند امنیت، شبیه سازی ها و الگوریتم ها را افزایش دهد. در توسعه نرم افزار، این غیرقابل پیش بینی بودن فقط یک ویژگی نیست، بلکه یک نیاز اساسی برای عملکردهای مختلف حیاتی است.
امنیت
مهمترین نقش تصادفی بودن در نرم افزار در حوزه امنیت است. اعداد تصادفی برای تولید کلیدهای امن برای رمزگذاری استفاده میشوند و اطمینان حاصل میکنند که دادههای حساس - خواه اطلاعات شخصی، جزئیات مالی یا ارتباطات محرمانه - از دسترسی غیرمجاز محافظت میشوند.
تصادفی بودن تضمین می کند که این کلیدها نمی توانند به راحتی پیش بینی یا تکرار شوند و موانع امنیتی را تقویت می کند (به بخش تصادفی در سیستم های رمزنگاری بیشتر مراجعه کنید)
تست و تضمین کیفیت
توسعه دهندگان از ورودی های تصادفی برای شبیه سازی نحوه عملکرد نرم افزار در شرایط مختلف استفاده می کنند. این رویکرد به کشف اشکالات غیرمنتظره کمک می کند و تضمین می کند که نرم افزار می تواند انواع سناریوها را مدیریت کند و قابلیت اطمینان و پایداری آن را بهبود می بخشد.
شرکت هایی مانند نتفلیکس، فیس بوک، گوگل از Chaos Engineering برای قابل اعتمادتر کردن سیستم های خود استفاده می کنند (در بخش Chaos Engineering بیشتر بیاموزید).
شبیه سازی و مدل سازی
تصادفی بودن یک جزء کلیدی در شبیهسازیهایی است که پدیدههای دنیای واقعی را تقلید میکنند، که میتوانند ذاتاً غیرقابل پیشبینی باشند. تصادفی بودن مدلسازی الگوهای آب و هوا، بازارهای اقتصادی یا جریانهای ترافیکی به ایجاد مدلهای دقیقتر کمک میکند که پیچیدگی این سیستمها را بهتر منعکس کند.
برنامه های کاربردی اضافی
تصادفی در بسیاری از زمینه ها استفاده می شود و به توزیع وظایف در سرورها در تعادل بار کمک می کند، کارایی در مسیریابی ترافیک را بهبود می بخشد و واقع گرایی را در تولید تصویر می افزاید. همچنین، برای ایجاد شناسههای منحصربهفرد مانند GUID (شناسههای منحصربهفرد جهانی) و به هم زدن فهرست های پخش برای بهبود تجربه کاربر بسیار مهم است. همانطور که می بینید، موارد استفاده برای تصادفی بودن بسیار زیاد است.
پیش نیازها
این مقاله به گونه ای طراحی شده است که در دسترس باشد و توضیحات کافی برای خوانندگانی با پیشینه های مختلف داشته باشد. با این حال، چند پیش نیاز اساسی می تواند درک شما را افزایش دهد:
دانش اولیه برنامه نویسی : اگرچه ضروری نیست، اما آشنایی با مفاهیم برنامه نویسی در زبان هایی مانند C#، جاوا یا پایتون می تواند به شما کمک کند تا نمونه هایی از نحوه پیاده سازی تصادفی در کد را سریعتر درک کنید.
مهارت های ریاضی ابتدایی : درک اولیه احتمالات و آمار مفید است اما ضروری نیست، زیرا هدف مقاله توضیح این مفاهیم به زبان ساده است.
رمزنگاری مقدماتی : اگر در مورد جنبههای امنیتی تصادفی بودن کنجکاو هستید، برخی پیشینه در مفاهیم رمزنگاری مانند رمزگذاری و تولید کلید میتواند مفید باشد.
به طور کلی، ساختار مقاله به گونهای است که دنبال کردن آن آسان است، بدون نیاز به دانش پیشرفته. این به معنای معرفی مفهوم تصادفی در مهندسی نرم افزار به طور گسترده است و آن را برای خوانندگان از زمینه های مختلف مناسب می کند.
در اینجا چیزی است که در این مقاله به آن خواهیم پرداخت:
چگونه مولدهای اعداد تصادفی کار می کنند
تولید اعداد تصادفی واقعی (TRNG) و منابع آنتروپی
Chaos Monkey نتفلیکس من را توسعه داد
تصادفی بودن در سیستم های رمزنگاری
آیا می توانید رمزگذاری را هک کنید؟
تصادفی در شبیه سازی و مدل سازی
آینده تصادفی در مهندسی نرم افزار
محاسبات کوانتومی و تصادفی کوانتومی
پارادایم پرتاب سکه

آیا پرتاب سکه واقعا یک اتفاق تصادفی است؟ در نگاه اول، پرتاب سکه نشاندهنده الگوی تصادفی بودن است: دو نتیجه، که هر کدام شانس یکسانی برای وقوع دارند.
اما اگر عمیقتر به فیزیک پشت پرتاب سکه بپردازیم، داستان به شکل دیگری شروع میشود. به طور فرضی، اگر بتوانیم هر متغیر درگیر در پرتاب را کنترل و تکرار کنیم - نیروی اعمال شده، زاویه پرتاب، مقاومت هوا، و حتی سطحی که روی آن فرود می آید - آیا نتیجه باز هم غیرقابل پیش بینی بود؟
پاسخ به یک اعلامیه شگفت انگیز متمایل است: در یک محیط کاملاً کنترل شده، نتیجه پرتاب سکه را می توان با اطمینان تقریباً پیش بینی کرد. این درک ما از تصادفی بودن را به چالش می کشد، و نشان می دهد که آنچه ما اغلب به عنوان تصادفی درک می کنیم تحت تأثیر عوامل متعددی است که بسیاری از آنها خارج از کنترل ما هستند یا برای تکرار در عمل بسیار پیچیده هستند.
پس ، به یک نتیجه روشنگر میرسیم که تصادفی بودن نتیجه متغیرهایی است که تکرار آنها بسیار دشوار است.
تحقیقات بزرگ دانشگاه کالیفرنیا در برکلی، با عنوان " سوگیری دینامیکی در پرتاب سکه "، به این پدیده می پردازد:
چکیده: ما روند طبیعی چرخاندن سکه ای را که در دست گیر می کند، تجزیه و تحلیل می کنیم. نشان میدهیم که سکههایی که به شدت برگردانده میشوند، به همان روشی که شروع کردند، بالا میآیند. شانس محدود کننده رسیدن به این روش به یک پارامتر بستگی دارد، زاویه بین نرمال به سکه و بردار تکانه زاویه ای. اندازه گیری این پارامتر بر اساس عکاسی با سرعت بالا گزارش شده است. برای تلنگرهای طبیعی، شانس بالا آمدن همانطور که شروع شده است حدود 0.51 است 
توهم تصادفی بودن انسان
برای انسان ها، تولید یک عدد تصادفی، گفتن یک کلمه تصادفی یا تصمیم گیری تصادفی کار آسانی است. اما باز هم، آیا واقعاً یک چیز تصادفی است و آیا می توان آن را به نحوی مانند آنچه برای پرتاب سکه بیان کردیم پیش بینی کرد؟
اگر فیلم فوکوس 2015 را دیده باشید، ممکن است صحنه «پرایمینگ» را به خاطر بیاورید که در آن روز را با «آغاز کردن» قربانی خود می گذرانند تا به طور ناخودآگاه عدد 55 را با نشان دادن آن در اطراف او شناسایی و انتخاب کنند.
پرایمینگ یکی از مهمترین اصول روانشناختی برای درک است زیرا از طریق حافظه ضمنی بر رفتار تأثیر می گذارد. به عبارت دیگر، قرار گرفتن در معرض یک نشانه در یک محیط می تواند ارتباطی را ایجاد کند که به دیگری منتقل می شود.
یکی از نمونه های پرایمینگ از یک مغازه بطری فروشی سوپرمارکت به دست ما می رسد. تصور کنید یک هفته به مغازه بطری فروشی می روید و در پس زمینه موسیقی فرانسوی پخش می شود. شما شراب خود را می خرید و می روید.
حالا تصور کنید یک هفته بعد برمی گردید، اما این بار موسیقی آلمانی از بلندگوها پخش می شود. باز هم شراب خود را می خرید و می روید. این احتمال وجود دارد که وقتی موسیقی فرانسوی پخش میشد، شراب فرانسوی میخریدید، و زمانی که موسیقی آلمانی پخش میشد، شراب آلمانی میخریدید - درست مانند 77٪ و 73٪ از شرکت کنندگان در تحقیق.
آیا این مصرف کنندگان از موسیقی و تأثیر آن بر تصمیم خود آگاه بودند؟ 86 درصد مردم گفتند نه، موسیقی تاثیری نداشت.
این پدیده بر یک حقیقت عمیق تأکید می کند: چه دانسته یا نه، ما هم آغازگر هستیم و هم آغازگر . تصادفی بودن درک شده ما در تصمیم گیری به طور مداوم توسط محرک های اطراف ما شکل می گیرد. این نشان میدهد که جوهر تصادفی بودن انسان بسیار پیچیدهتر و تحتتاثیرتر از آن چیزی است که در ابتدا ممکن است باور کنیم.
چگونه مولدهای اعداد تصادفی کار می کنند
بیایید سفری به روزهای اولیه محاسبات داشته باشیم تا تکامل مولدهای اعداد تصادفی را درک کنیم.
در ابتدا، کامپیوترها در مقایسه با ماشین های پیچیده امروزی کاملاً ابتدایی بودند. اساساً، یک رایانه بر اساس مجموعه ای دقیق از دستورالعمل ها عمل می کند: نمی تواند به طور خود به خود عددی تولید کند، زیرا انسان ها ممکن است به طور تصادفی یک عدد از 1 تا 10 را انتخاب کنند.
برای یک کامپیوتر، تولید یک عدد تصادفی به دستورالعملهای خاصی نیاز دارد. امروزه این کار در بسیاری از زبان های برنامه نویسی از طریق توابع داخلی ساده شده است. به عنوان مثال، در سی شارپ با این دستور ساده می توانید یک عدد تصادفی بین 1 تا 10 ایجاد کنید:
Random.Next(1, 10) // <-- Generates a radom number from 1 to 10قسمت جالب زمانی شروع می شود که به زیر کاپوت نگاه می کنیم.
مولد اعداد تصادفی ساده
اگر به شما وظیفه ای داده شود که یک تابع ایجاد کنید که یک عدد تصادفی تولید می کند چه؟ فرض کنید این تابع را دارید:
public static int GenerateRandomNumber(int start, int end) { return ✨🪄 magic ✨🪄 }یکی از ساده ترین راه ها برای انجام این کار استفاده از ژنراتور همگام خطی (LCG) است. مثال زیر یک رویکرد ساده است و شما نباید از آن برای مقاصد رمزنگاری یا برنامه هایی که نیاز به سطوح بالایی از تصادفی بودن دارند استفاده کنید.
using System; class SimpleRandomGenerator { private long seed; private const long a = 25214903917; private const long c = 11; private long m = (long)Math.Pow(2, 48); public SimpleRandomGenerator(long seed) { this.seed = seed; } public int Next(int min, int max) { // Update the seed seed = (a * seed + c) % m; // Ensure the result is within the bounds [min, max) int result = (int)(min + (seed % (max - min))); return result; } } class Program { static void Main(string[] args) { var generator = new SimpleRandomGenerator(DateTime.Now.Ticks); for(int i = 0; i < 15; i++) { var rndNumber = generator.Next(1, 101); Console.WriteLine($"Random number between 1 and 100: {rndNumber}"); } } } /* Output Random number between 1 and 100: 78 Random number between 1 and 100: 9 Random number between 1 and 100: -48 Random number between 1 and 100: 71 Random number between 1 and 100: 6 Random number between 1 and 100: 45 Random number between 1 and 100: 64 Random number between 1 and 100: 99 Random number between 1 and 100: -34 Random number between 1 and 100: 85 Random number between 1 and 100: -44 Random number between 1 and 100: -25 Random number between 1 and 100: 26 Random number between 1 and 100: -27 Random number between 1 and 100: 24 */این مثال از روش Linear Congruential Generator (LCG) استفاده می کند که یک مولد اعداد شبه تصادفی پایه است.
LCGها یکی از قدیمیترین و سادهترین روشها برای تولید دنبالهای از اعداد شبه تصادفی هستند و بر اساس یک فرمول ریاضی ساده عمل میکنند: " new seed = (a×seed+c) mod m". دانه معمولاً با استفاده از مقداری با آنتروپی کافی، مانند زمان جاری (در این مورد DateTime.Now.Ticks ) مقداردهی اولیه می شود. روش Next یک عدد "تصادفی" جدید در محدوده مشخص شده [min, max) تولید می کند.
در اینجا منطق گام به گام است:
بذر را به روز کنید : دانه با استفاده از فرمول LCG ذکر شده در بالا به روز می شود. این مرحله بسیار مهم است، زیرا از دانه قدیمی برای تولید یک مورد جدید استفاده میکند، و اطمینان حاصل میکند که هر فراخوانی به Next خروجی متفاوتی دارد.
مقیاس بندی خروجی : هنگامی که دانه جدید محاسبه شد، باید تنظیم شود تا در محدوده مشخص شده توسط کاربر قرار گیرد [min, max) .
– seed % (max - min) دانه را به مقداری در محدوده 0 تا (max - min) - 1 مقیاس می دهد.
– با گفت ن min ، این مقدار مقیاسشده به محدوده مورد نظر منتقل میشود، و تضمین میکند که نتیجه حداقل min اما کمتر از max است.
تولید اعداد تصادفی واقعی (TRNG) و منابع آنتروپی
تولید اعداد تصادفی بر اساس رویدادهای طبیعی یا ویژگی های سخت افزاری شامل استفاده از منابع غیرقابل پیش بینی و غیر قطعی برای تولید تصادفی است. این رویکرد اغلب به عنوان استفاده از "منابع آنتروپی" یا "تولید اعداد تصادفی واقعی" (TRNG) نامیده می شود.
برخلاف مولدهای اعداد تصادفی شبه (PRNG) که از الگوریتمهای ریاضی استفاده میکنند و به یک مقدار بذر نیاز دارند، مولدهای اعداد تصادفی واقعی تصادفی بودن خود را از رویدادهای فیزیکی که تقریباً غیرقابل پیشبینی هستند به دست میآورند. در اینجا چند نمونه هستند:
زلزله در TRNG
زمین لرزه ها داده های لرزه ای تولید می کنند که تقریباً غیرقابل پیش بینی است و می توان از آنها به عنوان منبع تصادفی استفاده کرد. با اندازه گیری فعالیت لرزه ای از طریق ژئوفون یا لرزه نگار، تغییرات دقیقه ای در حرکت زمین را می توان به اعداد تصادفی تبدیل کرد.
زمین لرزه به دلیل آزاد شدن ناگهانی انرژی در پوسته زمین و در نتیجه لرزش زمین رخ می دهد. این آزاد شدن انرژی غیرقابل پیش بینی است و از نظر بزرگی، مکان و فرکانس متفاوت است. غیرقابل پیش بینی بودن زمان، مدت و شدت رویدادهای لرزه ای این را به یک منبع آنتروپی قابل دوام تبدیل می کند.
جزئیات فنی اضافی
در اینجا برخی از جزئیات فنی اضافی در مورد زلزله در TRNG آمده است:
جمع آوری داده ها معمولاً با استفاده از ابزارهایی به نام لرزه سنج یا ژئوفون انجام می شود که به ارتعاشات زمین حساس هستند. این دستگاهها انرژی جنبشی حرکات زمین را به سیگنالهای الکتریکی تبدیل میکنند که میتوان آنها را دیجیتالی و آنالیز کرد.
این فرآیند ممکن است شامل موارد زیر باشد:
تهویه و فیلتر کردن سیگنال: فیلتر کردن سیگنال های لرزه ای برای جداسازی اجزای تصادفی از نویزهای قابل پیش بینی یا ارتعاشات پس زمینه.
دیجیتال سازی: تبدیل سیگنال های آنالوگ به مقادیر دیجیتال، که معمولاً شامل نمونه برداری از سیگنال در فواصل زمانی منظم و کمی کردن این نمونه ها به مقادیر دیجیتال است.
دادههای دیجیتال خام بهدستآمده از فعالیتهای لرزهای ممکن است بهدلیل سوگیریهای طبیعی در نحوه وقوع زلزله یا نحوه جمعآوری دادهها به طور یکنواخت تصادفی نباشند.
برای اطمینان از اینکه اعداد تولید شده برای استفاده در برنامه هایی که نیاز به تصادفی با کیفیت بالا دارند (مانند سیستم های رمزنگاری) مناسب هستند، ممکن است پردازش بیشتری لازم باشد.
در اینجا تکنیک های رایج وجود دارد:
Debiasing : استفاده از الگوریتم ها برای حذف هر گونه الگوی قابل پیش بینی یا سوگیری از داده ها.
سفید کردن : تبدیل داده ها برای اطمینان از توزیع یکنواخت در تمام مقادیر ممکن. این اغلب شامل آزمون های آماری برای تنظیم خروجی تا زمانی که معیارهای تصادفی بودن را برآورده کند، می شود.
استفاده از زمین لرزه برای تولید اعداد تصادفی می تواند به ویژه در کاربردهایی که منبع تصادفی غیرقابل پیش بینی خارجی سودمند است، ارزشمند باشد.
اما معایب و ملاحظات عملی وجود دارد:
محدودیتهای جغرافیایی : همه مکانها فعالیت لرزهای مکرری را تجربه نمیکنند، که میتواند در دسترس بودن این روش را به مناطق خاصی محدود کند.
نادر بودن رویداد : رویدادهای لرزهای مهم نسبتاً نادر و از نظر زمانبندی غیرقابل پیشبینی هستند، که ممکن است در صورت نیاز منبع ثابت یا قابل اعتمادی از تصادفی بودن ارائه نکنند.
سربار جمع آوری و پردازش داده ها: زیرساخت و تلاش محاسباتی مورد نیاز برای ضبط، پردازش و استفاده از داده های لرزه ای برای تولید اعداد تصادفی می تواند قابل توجه باشد.
رویدادهای سخت افزاری در TRNG
مولدهای اعداد تصادفی مبتنی بر سخت افزار (HRNG) از فرآیندهای فیزیکی در دستگاه های محاسباتی برای تولید تصادفی استفاده می کنند. مثالها عبارتند از:
نویز حرارتی (صدای جانسون-نیکوئیست):
نویز حرارتی، همچنین به عنوان نویز جانسون-نیکوئیست شناخته می شود، نوعی تداخل است که به طور طبیعی در تمام دستگاه ها و مدارهای الکترونیکی وجود دارد. این ناشی از حرکت تصادفی الکترون ها در یک ماده به دلیل گرما است. این پدیده می تواند به عنوان منبع تصادفی برای تولید اعداد تصادفی در دستگاه های سخت افزاری مورد استفاده قرار گیرد.
هر ماده ای که الکتریسیته را هدایت می کند دارای الکترون است که ذرات بسیار ریزی هستند که در اطراف حرکت می کنند و جریان الکتریکی را حمل می کنند. حتی زمانی که یک دستگاه به طور فعال مورد استفاده قرار نمی گیرد، این الکترون ها هرگز کاملاً ساکن نیستند - به دلیل انرژی گرمایی درون ماده به طور تصادفی حرکت می کنند. هر چه دما بیشتر باشد، الکترون ها فعال تر می شوند.
نویز حرارتی توسط انرژی ذاتی موجود در همه مواد در دمای بالاتر از صفر مطلق (273.15- درجه سانتیگراد یا -459.67 درجه فارنهایت) ایجاد می شود. در این دماها، الکترون ها انرژی می گیرند و به طور تصادفی شروع به حرکت می کنند. این حرکت باعث ایجاد نوسانات کوچک و تصادفی در جریان الکتریکی در اجزایی مانند مقاومت ها می شود.
نویز حرارتی برای برنامه های رمزنگاری که امنیت بالا ضروری است ایده آل است. این شامل تولید کلید و ارتباطات ایمن می شود که در آن غیرقابل پیش بینی بودن برای جلوگیری از حملات مهم است.
در توسعه پروتکلهای ارتباطی امن برای برنامههایی مانند پیامرسانی فوری، VoIP یا سیستمهای انتقال داده، میتوان از نویز حرارتی برای تولید کلیدهای رمزگذاری استفاده کرد که پیشبینی آنها تقریباً غیرممکن است و امنیت را افزایش میدهد.
رانش ساعت
رانش ساعت به دلیل تغییرات جزئی و غیرقابل پیشبینی در مکانیسمهای زمانبندی (مانند نوسانگرهای کریستالی) رایانهها و سایر دستگاههای دیجیتال رخ میدهد. رانش ساعت از تنوع طبیعی در ساعتهای سختافزاری استفاده میکند، ساعتهایی که برای اندازهگیری زمان طراحی شدهاند اما به دلیل تفاوتهای جزئی در فرکانس نوسانگرهایشان میتوانند از هم دور شوند.
با مقایسه زمان گزارش شده توسط دو یا چند ساعت مستقل، تفاوت های کوچکی که به طور طبیعی و غیرقابل پیش بینی رخ می دهند را می توان اندازه گیری کرد. این تفاوت ها تحت تأثیر عواملی مانند تغییرات دما، عیوب سخت افزاری و تغییرات ولتاژ تغذیه قرار دارند.

انتشار فوتونیک
تولید اعداد تصادفی مبتنی بر انتشار فوتونیک از فرآیند انتشار نور برای ایجاد اعداد تصادفی استفاده می کند. این رویکرد بر ماهیت کوانتومی نور متکی است - به طور خاص، رفتار فوتون ها، که ذرات ریزی هستند که نور را می سازند.
انتشار فوتونیک زمانی رخ می دهد که انرژی از اتم ها به شکل نور آزاد می شود. این در دستگاه هایی مانند LED (دیودهای ساطع کننده نور) و لیزرها اتفاق می افتد.
در LED، هنگامی که الکتریسیته از طریق دستگاه جریان می یابد، الکترون ها (ذرات ریز با بار منفی) را به حالت های انرژی بالاتر تحریک می کند. با بازگشت این الکترون ها به حالت طبیعی خود، انرژی را به شکل فوتون آزاد می کنند.
لحظه دقیق گسیل یک فوتون ذاتاً به دلیل اصول مکانیک کوانتومی غیرقابل پیش بینی است، جایی که ذراتی مانند الکترون ها به شیوه ای احتمالی رفتار می کنند.
برای تبدیل گسیل فوتونیک به اعداد تصادفی، ابتدا باید این فوتون ها را شناسایی کنیم. ما میتوانیم این کار را با استفاده از دستگاهی به نام ردیاب نوری انجام دهیم که نور را جذب میکند و هر فوتونی که برخورد میکند به سیگنال الکتریکی تبدیل میکند.
کلید تصادفی بودن در زمان رسیدن هر فوتون به آشکارساز نهفته است. از آنجایی که گسیل هر فوتون تصادفی است، زمان های شناسایی آنها نیز تصادفی است. سپس این زمان ها با دقت بالایی ثبت می شوند.
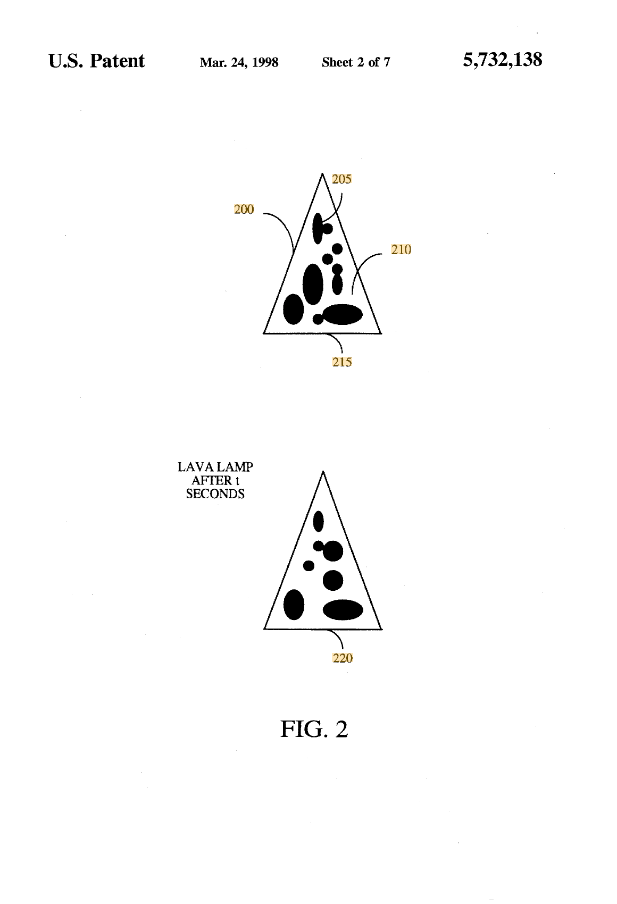
لامپ های گدازه Cloudflare برای تصادفی
Cloudflare، یک شرکت عملکرد وب و امنیت، دیواری از لامپ های گدازه ای را در لابی دفتر خود در سانفرانسیسکو راه اندازی کرده است. این راه اندازی به عنوان سیستم "LavaRand" شناخته می شود. این اهرم از حرکات غیرقابل پیش بینی و همیشه در حال تغییر "گدازه" درون این لامپ ها برای ایجاد تصادفی استفاده می کند.

LavaRand چگونه کار می کند:
فرآیند با گرفتن تصویری شروع می شود. دوربینی به سمت دیوار لامپ های گدازه گرفته شده است. لامپ ها حاوی حباب های موم در مایعی هستند که با گرم شدن به روش های غیرقابل پیش بینی منبسط شده و حرکت می کنند.
همانطور که موم گرم می شود، بالا می رود و با سرد شدن، سقوط می کند و یک صفحه نمایش همیشه در حال تغییر و از نظر بصری آشفته ایجاد می کند.
دوربین در فواصل زمانی معین از لامپ های گدازه عکس می گیرد. هر تصویر یک الگوی تصادفی و منحصر به فرد از موم چرخان را ثبت می کند. سپس این تصاویر با استفاده از الگوریتم های کامپیوتری برای استخراج داده های تصادفی از الگوهای مشاهده شده در تصاویر پردازش می شوند.
ارتباط با انتشار فوتونیک:
در حالی که لامپهای گدازهای Cloudflare از نوعی گسیل فوتونیک استفاده میکنند، اما غیرمستقیم است. گسیل فوتونیک در این زمینه، نور ساطع شده از لامپ ها است که موم داخل را روشن می کند.
با این حال، فرآیند تولید اعداد تصادفی در درجه اول به حرکات فیزیکی آشفته موم بستگی دارد که توسط نور گرفته شده و توسط دوربین ثبت می شود. تصادفی بودن از نحوه پخش نور و سایه با گدازه متحرک ناشی می شود، نه از انتشار و تشخیص فوتون ها در سطح کوانتومی (که در سیستم های RNG گسیل فوتونیک با استفاده از LED یا لیزر معمول تر است).
اطلاعات از وب سایت رسمی Cloudflare:
LavaRand سیستمی است که از لامپ های گدازه به عنوان منبع ثانویه تصادفی برای سرورهای تولید ما استفاده می کند. دیواری از لامپهای گدازهای در لابی دفتر ما در سانفرانسیسکو ورودی غیرقابل پیشبینی را به دوربینی که به سمت دیوار نشانه رفته است ارائه میکند. یک فید ویدیویی از دوربین به یک CSPRNG وارد میشود و آن CSPRNG جریانی از مقادیر تصادفی را ارائه میکند که میتواند به عنوان منبع اضافی تصادفی توسط سرورهای تولید ما استفاده شود. از آنجایی که جریان "گدازه" در یک لامپ گدازه بسیار غیرقابل پیش بینی است، "اندازه گیری" لامپ ها با گرفتن فیلم از آنها راه خوبی برای به دست آوردن تصادفی غیرقابل پیش بینی است. رایانه ها تصاویر را به صورت اعداد بسیار بزرگ ذخیره می کنند، پس می توانیم مانند هر عدد دیگری از آنها به عنوان ورودی یک CSPRNG استفاده کنیم.
ما اولین کسانی نیستیم که این کار را انجام می دهیم. سیستم LavaRand ما از یک سیستم مشابه الهام گرفته شده است که ابتدا توسط Silicon Graphics پیشنهاد و ساخته شد و در سال 1996 ثبت اختراع شد (پتنت از آن زمان منقضی شده است).
امیدوارم هرگز به آن نیاز نخواهیم داشت. امیدواریم که منابع اولیه تصادفی که توسط سرورهای تولیدی ما استفاده میشوند، امن باقی بمانند و LavaRand هدف کمی فراتر از گفت ن کمی استعداد به دفتر ما داشته باشد. اما اگر معلوم شد که اشتباه میکنیم، و منابع تصادفی ما در تولید واقعاً ناقص هستند، LavaRand محافظ ما خواهد بود و هک کردن Cloudflare را کمی سختتر میکند.
عوامل انسانی در TRNG
ماوس افزار
برخی از ابزارها مانند Mouseware از عوامل انسانی برای ایجاد تصادفی استفاده می کنند. Mouseware از یک مولد اعداد تصادفی امن رمزنگاری بر اساس حرکات ماوس برای تولید رمزهای عبور امن و به یاد ماندنی استفاده می کند. گذرواژه ها به طور کامل در مرورگر تولید می شوند و هیچ داده ای از طریق شبکه ارسال نمی شود.
برای آن رمزهای عبور تولید شده، 22400.7 سال برای حدس زدن با 1000 حدس در ثانیه و 2.0 ساعت برای حدس زدن 100 میلیارد حدس در ثانیه طول می کشد.
1000 حدس در ثانیه بدترین حمله مبتنی بر وب است. به طور معمول این تنها نوع حمله ای است که علیه یک وب سایت امن امکان پذیر است.
100 میلیارد حدس در ثانیه، بدترین حمله آفلاین است که یک پایگاه داده رمز عبور هش شده توسط شخصی با منابع فنی و مالی غیر ضروری دزدیده شود. 
می توانید اطلاعات بیشتری در مورد Mouseware در وب سایت آنها بخوانید .
تصادفی بودن در تست نرم افزار
Chaos Monkey نتفلیکس من را توسعه داد

Chaos Monkey ابزاری نوآورانه است که توسط نتفلیکس توسعه یافته است. این مسئول خاتمه تصادفی نمونه های نتفلیکس در تولید است تا اطمینان حاصل شود که مهندسان خدمات خود را به گونه ای اجرا می کنند که در برابر خرابی های نمونه مقاوم باشند.
تصور کنید یک میمون مجازی و شرور به طور تصادفی با شبکه دستکاری می کند - نمونه هایی را خاموش می کند، سرورها را قطع می کند یا سیستم ها را بیش از حد بارگذاری می کند تا خرابی های احتمالی را شبیه سازی کند.
اگرچه ممکن است خلاف واقع به نظر برسد، اما هدف Chaos Monkey این است که به طور فعالانه شکست های کنترل شده را تحریک کند. این استراتژی به مهندسان نتفلیکس این امکان را میدهد تا آزمایش کنند که سیستمهایشان تا چه اندازه میتوانند اختلالات غیرمنتظره را مدیریت کنند. هدف شناسایی و رفع نقاط ضعف قبل از تأثیرگذاری بر کاربران است و اطمینان حاصل شود که زیرساخت به اندازه کافی قوی است تا بتواند در برابر مسائل دنیای واقعی مقاومت کند.
به عنوان مثال، اگر Chaos Monkey به طور تصادفی یک سرور را خاتمه دهد و همه چیز به آرامی به کار خود ادامه دهد، این یک برد است. در صورت بروز مشکلات، مهندسان به سرعت آنها را تجزیه و تحلیل و اصلاح می کنند و در نتیجه سیستم را تقویت می کنند. این چرخه آزمایش و بهبود مستمر کمک میکند تا اطمینان حاصل شود که وقتی به تماشای سریالهای مورد علاقهتان رضایت میدهید، پخش جریانی بدون وقفه را تجربه میکنید.
به لطف ابزارهایی مانند Chaos Monkey و اصول Chaos Engineering، نتفلیکس می تواند یک تجربه تماشای یکپارچه را ارائه دهد. دفعه بعد که نمایشی را بدون هیچ اشکالی تماشا می کنید، تلاش های پشت صحنه این قهرمانان گمنام را به خاطر بیاورید که سرگرمی شما را بی عیب و نقص نگه می دارند.
این ابزار برای استفاده از منبع باز نیز موجود است. اسناد را اینجا تحلیل کنید .
تصادفی بودن در سیستم های رمزنگاری
تصادفی بودن نقش مهمی در سیستم های رمزنگاری ایفا می کند و ستون فقرات پروتکل های امنیتی را در سراسر چشم انداز دیجیتال تشکیل می دهد. این بخش به تحلیل این موضوع می پردازد که چرا تصادفی بودن در رمزنگاری ضروری است، چگونه ایجاد می شود و چالش های موجود در تضمین اثربخشی آن.
در سیستم های رمزنگاری، تصادفی برای تولید کلیدها، مقداردهی اولیه الگوریتم های رمزنگاری، و برای فرآیندهای غیر انکار مانند امضای دیجیتال و ارتباطات ایمن استفاده می شود.
قدرت و امنیت تقریباً تمام تکنیک های رمزنگاری به کیفیت تصادفی مورد استفاده بستگی دارد. اگر تصادفی بودن قابل پیش بینی باشد، کلیدهای رمزنگاری نیز قابل پیش بینی است و سیستم را در برابر حملات آسیب پذیر می کند.
اگر متن " Hello World " را رمزگذاری کنیم، این متن " oO64D2IzNWKSQnDM8fcZ/w== " را دریافت خواهیم کرد. برای دیدن قدرت رمزگذاری، بیایید انواع متن را نیز رمزگذاری کنیم: "HelloWorld" (بدون فاصله) و "Hello world" (با حروف کوچک)، در حالی که با یک کلید رمزگذاری متفاوت نیز آزمایش می کنیم.
در اینجا نتایج آمده است:
╔═════════════╦═══════════╦══════════════════════════╗ ║ Text ║ Password ║ Encoded value ║ ╠═════════════╬═══════════╬══════════════════════════╣ ║ Hello World ║ 1234 ║ oO64D2IzNWKSQnDM8fcZ/w== ║ ╠─────────────╬───────────╬──────────────────────────╣ ║ HelloWorld ║ 1234 ║ KvqAEHQhP9iBdFWhOUcYVg== ║ ╠─────────────╬───────────╬──────────────────────────╣ ║ Hello world ║ 1234 ║ jdKRaAw9ULCFb627e3mNpQ== ║ ╠─────────────╬───────────╬──────────────────────────╣ ║ Hello World ║ 123 ║ S/eGTyDQsgLwcEIrCWUAJw== ║ ╠─────────────╬───────────╬──────────────────────────╣ ║ HelloWorld ║ 123 ║ /JRa5+mllydL/F0m7NuxYA== ║ ╠─────────────╬───────────╬──────────────────────────╣ ║ Hello world ║ 123 ║ s3AydwlvlgHCcpiAhaurXg== ║ ╚═════════════╩═══════════╩══════════════════════════╝اگر جدول بالا را در نظر بگیرید، متوجه خواهید شد که حتی یک تغییر کوچک، مانند تغییر در فاصله یا یک کاراکتر، منجر به تغییر کامل متن رمزگذاری شده می شود.
این بدان معنی است که اگر نفوذگر موفق شود هم متن اصلی و هم شکل رمزگذاری شده آن را به دست آورد، همچنان در تلاش برای حدس زدن رمز عبور مورد نیاز برای باز کردن قفل کل پایگاه داده با چالش مهمی روبرو خواهد شد.
آیا می توانید رمزگذاری را هک کنید؟
حملات Brute Force روشی ساده و در عین حال قدرتمند است که توسط مهاجمان برای شکستن رمزهای عبور و کلیدهای رمزگذاری استفاده می شود.
حمله brute force شامل تحلیل سیستماتیک همه ترکیبات ممکن است تا زمانی که ترکیب صحیح پیدا شود. مهاجمان از روشهای brute force برای امتحان هر کلید یا رمز عبور ممکن استفاده میکنند تا زمانی که دادههای هدف را رمزگشایی کنند.
در مورد ما، برای رمزگشایی کلمه، باید هر ترکیب ممکن را امتحان کنیم (حتی مانند رشته های a، aa، b، bb و غیره).
اکنون اجازه میدهیم محاسبه کنیم که چقدر زمان برای رمزگشایی/بررسی هر ترکیب ممکن برای رمز عبور ما لازم است. فرض کنید شما صاحب یک ابرکامپیوتر فوقالعاده قدرتمند، همراه با فناوری پیشرفته و منابع تقریباً نامحدود هستید.
فرض کنید رایانه دارای 1 ترابایت (TB) رم است که به آن امکان می دهد کارهای زیادی را همزمان انجام دهد. برای CPU، این ابرکامپیوتر دارای سرعت شگفت انگیز 1 exaflop است که به این معنی است که می تواند حدود 1 کوئینتیلیون محاسبه را تنها در یک ثانیه انجام دهد. 1 اگزافلاپ برابر با 1000000 گیگافلاپ است. پس ، برای دستیابی به 1 اگزافلاپ قدرت محاسباتی با استفاده از پردازندههای i9 اینتل با عملکرد هر کدام 300 گیگافلاپ، به 1،000،000 گیگافلاپ / 300 گیگافلاپ = 3،333،333 پردازنده i9 اینتل نیاز دارید.
این ابرکامپیوتر فرضی که محاسبات شگفتانگیزی را با سرعت رعد و برق انجام میدهد، میتواند به یک الگوریتم رمزگذاری حملهای با نیروی brute-force انجام دهد.
اگر قرار بود ابررایانه فرضی ما هر ترکیب ممکنی از متن را برای رمزگشایی داده های رمزگذاری شده امتحان کند، با تعداد نجومی احتمالات روبرو می شد - 2256. تخمین زده می شود که نه تنها سال ها، نه حتی قرن ها، بلکه به طور بالقوه ده ها هزار دهه طول می کشد.
برای مطالعه بیشتر در این مورد می توانید به این مقاله ای که من نوشتم مراجعه کنید .
تصادفی در شبیه سازی و مدل سازی
شبیه سازی مونت کارلو
شبیهسازی مونت کارلو یک تکنیک ریاضی است که برای درک تأثیر ریسک و عدم قطعیت در مدلهای پیشبینی و پیشبینی استفاده میشود. اساساً، این روشی است که برای پیشبینی احتمال نتایج مختلف زمانی که مداخله متغیرهای تصادفی وجود دارد، استفاده میشود.
این روش به دلیل اتکا به تصادفی بودن کازینوی معروف مونت کارلو نامگذاری شده است، این روش به طور گسترده در امور مالی، مهندسی، تحقیقات و موارد دیگر مورد استفاده قرار می گیرد.
در زمینه امور مالی، شبیه سازی مونت کارلو معمولاً برای ارزیابی ریسک و ارزش ابزارهای مالی، مانند گزینه ها یا پورتفولیوها استفاده می شود. با ایجاد تعداد زیادی سناریو تصادفی برای متغیرهای ورودی مختلف، مانند قیمت دارایی یا نرخ بهره، شبیهسازی مونت کارلو میتواند طیفی از نتایج ممکن و احتمالات مرتبط با آنها را ارائه دهد. این روش بیشتر زمانی استفاده می شود که هیچ راه حل تحلیلی برای مسئله داده شده وجود نداشته باشد.
مخابرات از آنها برای ارزیابی عملکرد شبکه در سناریوهای مختلف استفاده می کند که به آنها کمک می کند تا شبکه های خود را بهینه کنند. تحلیلگران مالی از شبیه سازی های مونت کارلو برای ارزیابی ریسک نکول یک واحد تجاری و تجزیه و تحلیل مشتقات مانند اختیار معامله استفاده می کنند. بیمهگران و حفاریهای چاه نفت نیز از آنها برای اندازهگیری ریسک استفاده میکنند.
برای مطالعه بیشتر، این مقاله را تحلیل کنید .
آینده تصادفی در مهندسی نرم افزار
آینده تصادفی در مهندسی نرم افزار به خصوص امیدوار کننده به نظر می رسد، با پیشرفت های قابل توجهی که از فناوری های نوظهور مانند محاسبات کوانتومی پیش بینی می شود.
محاسبات کوانتومی و تصادفی کوانتومی
محاسبات کوانتومی یک عنصر ذاتی تصادفی به نام تصادفی کوانتومی را معرفی می کند.
برخلاف محاسبات کلاسیک، که بر فرآیندهای قطعی متکی است، فرآیندهای کوانتومی طبیعتاً غیرقابل پیش بینی هستند. مولدهای اعداد تصادفی کوانتومی (QRNG) از این ویژگی برای تولید اعداد تصادفی واقعی مستقیماً از پدیدههای کوانتومی، مانند برهم نهی حالتهای کوانتومی یا اندازهگیری ذرات درهمتنیده استفاده میکنند.
پیش بینی می شود این دستگاه ها منبع تصادفی ایمن تر و اساساً غیرقابل پیش بینی تر از آنچه در حال حاضر ممکن است ارائه کنند.

محاسبات کوانتومی پتانسیل ایجاد انقلابی در رمزنگاری را دارد. سیستمهای رمزنگاری کنونی بر دشواری محاسباتی مشکلات خاصی (مانند فاکتورگیری اعداد بزرگ) تکیه میکنند که رایانههای کوانتومی میتوانند بدون زحمت آنها را حل کنند . اما رمزنگاری کوانتومی، با استفاده از تصادفی کوانتومی برای توزیع کلید، وعده می دهد که به دلیل قوانین مکانیک کوانتومی عملاً شکست ناپذیر خواهد بود.
وضعیت فعلی محاسبات کوانتومی
در حال حاضر، محاسبات کوانتومی در مرحله آزمایشی است. محققان و شرکتهایی مانند گوگل، آیبیام و دیویو بهطور فعال در حال توسعه رایانههای کوانتومی هستند و در سالهای اخیر پیشرفتهای چشمگیری داشتهاند.
به عنوان مثال ، گوگل در سال 2019 "برتری کوانتومی" را اعلام کرد ، و ادعا کرد که رایانه کوانتومی آنها مشکلی را حل کرده است که برای یک کامپیوتر کلاسیک در هر زمان معقول برای یک کامپیوتر کلاسیک غیرممکن است.
بیت های کوانتومی ، یا Qubits ، که واحدهای اصلی اطلاعات در محاسبات کوانتومی هستند ، بسیار مستعد دخالت در محیط خود هستند. این منجر به نرخ خطای بالا در محاسبات کوانتومی می شود. تهیه کدهای اصلاح خطا و یافتن راه هایی برای پایدارتر کردن Qubits ، تمرکز قابل توجهی در تحقیقات فعلی است.
در حال حاضر ، رایانه های کوانتومی تعداد محدودی از Qubits دارند. برای عملی بودن برای استفاده گسترده ، رایانه های کوانتومی باید بدون افزایش مربوط به نرخ خطا ، تعداد Qubits را به میزان قابل توجهی افزایش دهند.
همچنین این رایانه ها برای حفظ وضعیت کوانتومی Qubits باید در دماهای بسیار پایین ، نزدیک به صفر مطلق کار کنند. حفظ چنین شرایطی از نظر فنی چالش برانگیز و گران است.
اجماع بین کارشناسان با احتیاط خوش بین است ، اما از آنجایی که محاسبات کوانتومی برای استفاده گسترده عملی می شود ، بسیار متفاوت است.
برخی از کارشناسان معتقدند که طی یک دهه آینده ، ما شاهد هستیم که رایانه های کوانتومی مشکلات عملی تر و واقعی تر را حل می کنند ، به طور بالقوه در زمینه هایی مانند رمزنگاری ، علم مواد و شبیه سازی پیچیده سیستم متحول می شوند. برخی دیگر فکر می کنند که این برنامه ها ممکن است برای چندین دهه دیگر از دسترس خارج شوند.
بسته بندی
آینده تصادفی در مهندسی نرم افزار پتانسیل زیادی برای هدایت نوآوری در چندین حوزه دارد.
از آنجا که ما به محاسبات کوانتومی عمیق تر می پردازیم و فن آوری های فعلی خود را تقویت می کنیم ، تصادفی نقش مهمی در شکل دادن به نسل بعدی راه حل های نرم افزاری بازی می کند و آنها را ایمن تر ، کارآمدتر و بازتابی از دنیای پیچیده ای که مدل می کنند ، ایجاد می کند.

برچسبها
|
|



ارسال نظر