راهنمای توسعهدهنده مجوز ربات چت با هوش مصنوعی

این مقاله به تشریح تکنیکهای ضروری برای ایمنسازی رباتهای چت هوش مصنوعی از طریق روشهای مجوز قوی میپردازد. با استفاده از ابزارهایی مانند Pinecone، Supabase و Microsoft Copilot، تکنیکهایی مانند فیلتر ابرداده، امنیت در سطح ردیف، و کنترل دسترسی مبتنی بر هویت را معرفی میکند و هدف آن حفاظت از دادههای حساس در عین بهینهسازی گردشهای کاری مبتنی بر هوش مصنوعی است.
چت رباتهای هوش مصنوعی نحوه تعامل سازمانها با دادهها را متحول میکنند، مزایایی مانند پشتیبانی شخصیشده مشتری، بهبود مدیریت دانش داخلی و اتوماسیون کارآمد گردشهای کاری کسبوکار را به ارمغان میآورند. با این حال، با این قابلیت افزایش یافته، نیاز به مکانیسم های مجوز قوی برای جلوگیری از دسترسی غیرمجاز به داده های حساس وجود دارد. همانطور که چت بات ها هوشمندتر و قدرتمندتر می شوند، مجوز قوی برای محافظت از کاربران و سازمان ها ضروری می شود.
این یک راهنمای 101 است تا توسعه دهندگان را از طریق تکنیک ها و ارائه دهندگان مختلف موجود برای گفت ن مجوز قوی و دقیق به چت ربات های هوش مصنوعی ببرد. با استفاده از Pinecone، Supabase و Microsoft Copilot به عنوان مرجع، به تکنیکهای دنیای واقعی مانند فیلتر کردن ابرداده، امنیت در سطح ردیف (RLS) و کنترل دسترسی مبتنی بر هویت میپردازیم . ما نیز خواهیم کرد چگونه OAuth/OIDC، ادعاهای JWT و مجوز مبتنی بر توکن تعاملات مبتنی بر هوش مصنوعی را ایمن می کند.
در نهایت، در مورد اینکه چگونه ترکیب این روش ها به ایجاد چت ربات های هوش مصنوعی ایمن و مقیاس پذیر متناسب با نیازهای سازمان شما کمک می کند، بحث خواهیم کرد.
Pinecone ، یک پایگاه داده برداری که برای برنامه های کاربردی هوش مصنوعی طراحی شده است، مجوز را از طریق فیلتر ابرداده ساده می کند. این روش به بردارها اجازه می دهد تا با ابرداده (به عنوان مثال، نقش های کاربر یا بخش ها) برچسب گذاری شوند و در طول عملیات جستجو فیلتر شوند. این به ویژه در سناریوهای ربات چت هوش مصنوعی مؤثر است، جایی که میخواهید اطمینان حاصل کنید که فقط کاربران مجاز میتوانند به دادههای خاصی بر اساس قوانین فراداده از پیش تعریف شده دسترسی داشته باشند.
درک جستجوی شباهت برداری
در جستجوی شباهت برداری ، نمایش های برداری از داده ها (مانند تصاویر، متن یا دستور العمل ها) را می سازیم، آنها را در یک فهرست (پایگاه داده تخصصی برای بردارها) ذخیره می کنیم و سپس آن فهرست را با بردار پرس و جو دیگری جستجو می کنیم.
این همان اصلی است که موتور جستجوی Google را تقویت می کند، که مشخص می کند چگونه پرس و جو جستجوی شما با نمایش برداری صفحه همسو می شود. به طور مشابه، پلتفرمهایی مانند نتفلیکس، آمازون و اسپاتیفای برای توصیه نمایشها، محصولات یا موسیقی با مقایسه ترجیحات کاربران و شناسایی رفتارهای مشابه در گروهها، بر جستجوی شباهت برداری تکیه میکنند.
با این حال، وقتی نوبت به ایمن کردن این دادهها میرسد، اجرای فیلترهای مجوز بسیار مهم است تا نتایج جستجو بر اساس نقشها، بخشها یا سایر ابردادههای مربوط به زمینه خاص کاربر محدود شود.
مقدمه ای بر فیلترینگ ابرداده ها
فیلتر ابرداده با برچسب گذاری هر بردار با زمینه اضافی، مانند نقش های کاربر، بخش ها یا مُهرهای زمانی، لایه ای از مجوز را به فرآیند جستجو اضافه می کند. به عنوان مثال، بردارهایی که اسناد را نشان می دهند ممکن است شامل ابرداده هایی مانند:
نقش های کاربر (به عنوان مثال، فقط «مدیران» می توانند به اسناد خاصی دسترسی داشته باشند)
دپارتمان ها (به عنوان مثال، داده هایی که فقط برای بخش "مهندسی" قابل دسترسی است)
تاریخ ها (به عنوان مثال، محدود کردن داده ها به اسناد سال گذشته)
این فیلتر کردن تضمین می کند که کاربران فقط نتایجی را که مجاز به مشاهده هستند بازیابی می کنند.
چالشهای فیلتر ابرداده: پیش فیلتر در مقابل پس فیلترینگ
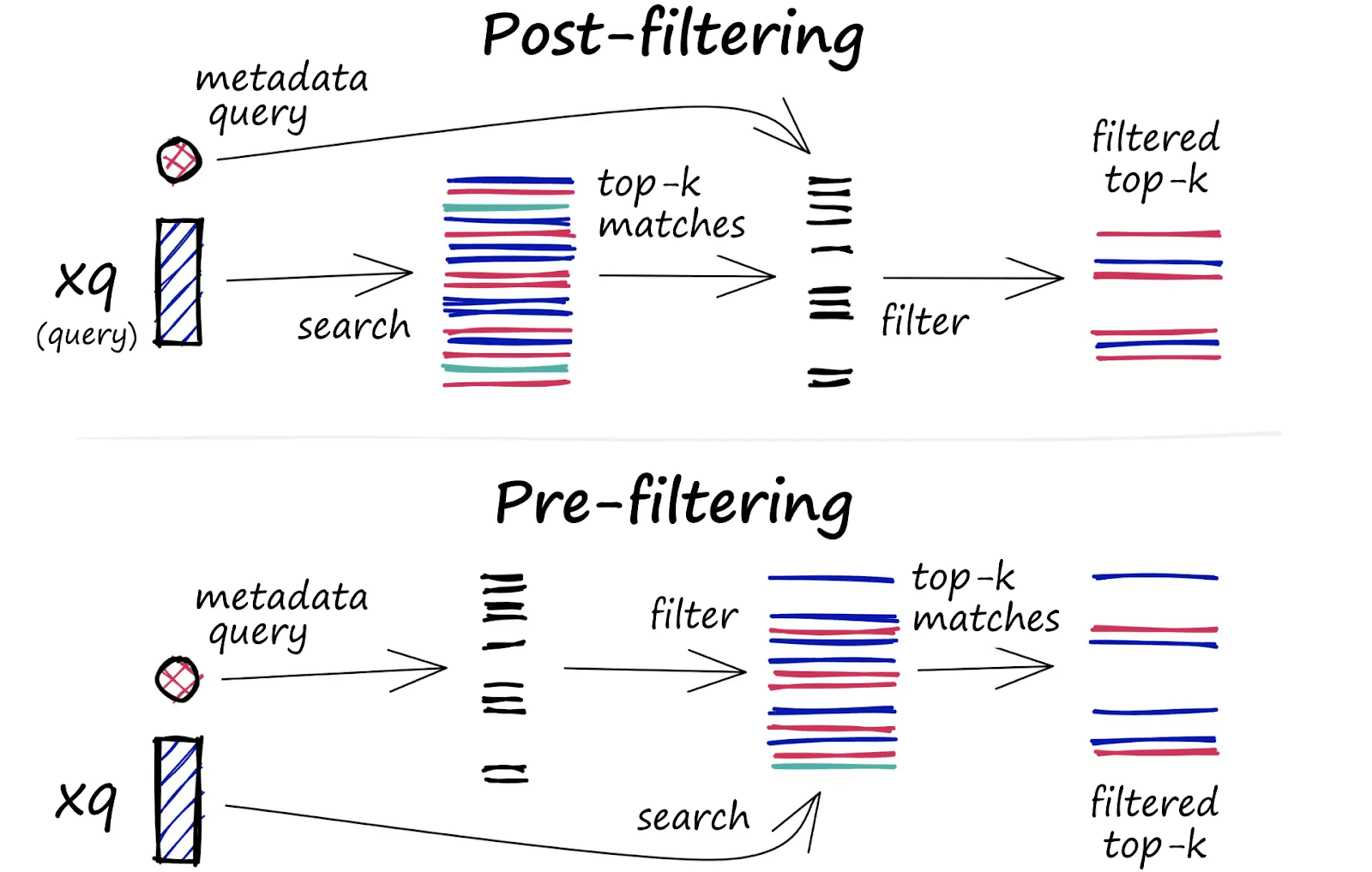
هنگام اعمال فیلتر ابرداده، معمولاً از دو روش سنتی استفاده می شود: پیش فیلتر و پس فیلتر.
پیش فیلتر کردن، فیلتر فراداده را قبل از جستجو اعمال می کند و مجموعه داده را به بردارهای مربوطه محدود می کند. در حالی که این تضمین میکند که فقط بردارهای مجاز در نظر گرفته میشوند، کارایی الگوریتمهای جستجوی تقریبی نزدیکترین همسایه (ANN) را مختل میکند و منجر به جستجوهای آهستهتر و با نیروی brute-force میشود.
در مقابل، پس فیلترینگ ، ابتدا جستجو را انجام می دهد و سپس فیلتر را اعمال می کند. این کار از کند شدن سرعت پیش فیلتر کردن جلوگیری می کند، اما در صورتی که هیچ یک از موارد برتر مطابق با شرایط فیلتر نباشند، نتایج نامربوط را برمی گرداند. به عنوان مثال، اگر هیچ یک از بردارهای بالا از فیلتر ابرداده عبور نکند، ممکن است نتایج کمتری دریافت کنید یا هیچ نتیجه ای نداشته باشید.
برای حل این مشکلات، Pinecone فیلتر تک مرحله ای را معرفی می کند. این روش شاخصهای بردار و فراداده را با هم ادغام میکند و امکان سرعت و دقت را فراهم میکند. با اعمال کنترل های دسترسی در یک فرآیند فیلتر کردن تک مرحله ای، Pinecone هم عملکرد و هم امنیت را در جستجوهای بلادرنگ بهینه می کند.
استفاده از فیلتر ابرداده برای مجوز: نمونه کد
اکنون، بیایید نحوه اجرای فیلتر ابرداده در Pinecone را برای یک مورد استفاده از ربات چت هوش مصنوعی در دنیای واقعی تحلیل کنیم. این مثال نشان میدهد که چگونه میتوان بردارها را با ابرداده درج کرد و سپس با استفاده از فیلترهای ابرداده از فهرست جستجو کرد تا از دسترسی مجاز اطمینان حاصل شود.
منو را باز کنید
import pinecone # Initialize Pinecone pinecone.init(api_key="your_api_key", environment="us-west1-gcp") # Create an index index_name = "example-index" if index_name not already created: pinecone.create_index(index_name, dimension=128, metric="cosine") # Connect to the index index = pinecone.Index(index_name) # Insert a vector with metadata vector = [0.1, 0.2, 0.3, ..., 0.128] # Example vector metadata = { "user_id": "user123", "role": "admin", "department": "finance" } # Upsert the vector with metadata index.upsert(vectors=[("vector_id_1", vector, metadata)]) در این مثال، ما یک بردار با ابرداده مرتبط، مانند user_id ، role ، و department وارد کردهایم که بعداً میتواند برای اعمال کنترل دسترسی استفاده شود. مرحله بعدی شامل پرس و جو از نمایه در حین اعمال فیلتر فراداده برای محدود کردن نتایج بر اساس نمایه مجوز کاربر است.
منو را باز کنید
# Querying the index, restricting results based on metadata query_vector = [0.15, 0.25, 0.35, ..., 0.128] filter = { "user_id": "user123", # Only retrieve vectors belonging to this user "role": {"$eq": "admin"} # Optional: match role } # Perform the query with metadata filter results = index.query(queries=[query_vector], filter=filter, top_k=5) # Display results for result in results["matches"]: print(result)با اعمال فیلتر ابرداده در طول پرس و جو، اطمینان حاصل می کنیم که فقط بردارهایی که با فراداده کاربر مطابقت دارند (مثلاً شناسه کاربر و نقش) برگردانده می شوند و به طور مؤثر مجوز را در زمان واقعی اعمال می کنند.
پیاده سازی فیلترهای پیچیده برای مجوز
همچنین میتوان فیلتر ابرداده را برای رسیدگی به سناریوهای پیچیدهتر و چند بعدی مجوز گسترش داد. به عنوان مثال، ما می توانیم نتایج را بر اساس شرایط متعدد فیلتر کنیم، مانند محدود کردن نتایج جستجو به اسناد در یک بخش خاص و محدوده تاریخ.
منو را باز کنید
# Query with multiple metadata conditions filter = { "department": {"$eq": "finance"}, "date": {"$gte": "2023-01-01", "$lt": "2023-12-31"} } results = index.query(queries=[query_vector], filter=filter, top_k=5) # Display results for result in results["matches"]: print(result)این ترکیب جستجوی شباهت برداری و فیلتر ابرداده، چارچوبی قوی برای مجوزهای دقیق ایجاد میکند. این تضمین می کند که چت ربات های هوش مصنوعی می توانند با محدود کردن نتایج جستجو به کاربران مجاز بر اساس ابعاد مختلف مانند نقش، بخش و چارچوب زمانی، هم عملکرد بالا و هم پاسخ های ایمن و مبتنی بر زمینه را ارائه دهند.
آیا میخواهید درباره فیلتر ابرداده اطلاعات بیشتری کسب کنید و نمونهای کاملاً ساختهشده با Descope و Pinecone را ببینید؟ وبلاگ ما را در زیر تحلیل کنید:
Auth و کنترل دسترسی را به برنامه Pinecone RAG اضافه کنید
Supabase: امنیت در سطح ردیف برای داده های برداری

فیلتر ابرداده برای کنترل دسترسی گسترده بر اساس دستهها یا برچسبها (به عنوان مثال، محدود کردن نتایج جستجو بر اساس بخش یا نقش) ایدهآل است. با این حال، زمانی که کنترل دقیقی بر روی افرادی که میتوانند رکوردهای خاص را مشاهده، اصلاح یا بازیابی کنند، مورد نیاز است، کوتاهی میکند.
در سیستمهای سازمانی که بر پایگاههای اطلاعاتی رابطهای مانند پلتفرمهای مالی متکی هستند، دسترسی اغلب باید به سوابق تراکنشهای فردی یا ردیفهای دادههای مشتری اعمال شود. امنیت در سطح ردیف (RLS) سوابیس این امکان را با تعریف خطمشیهایی که مجوزهای دقیق را در سطح ردیف بر اساس آپشن های کاربر یا سیستمهای مجوز خارجی با استفاده از بستههای داده خارجی (FDW) اعمال میکنند، ممکن میسازد.
در حالی که فیلتر ابرداده در مدیریت دسترسی به دادههای غیرمرتبط و مبتنی بر بردار - عالی برای جستجوهای مبتنی بر هوش مصنوعی یا سیستمهای پیشنهادی عالی است - Supabase RLS کنترل دقیق و در سطح رکورد را ارائه میدهد و آن را برای محیطهایی که نیاز به مجوزهای دقیق و انطباق دارند مناسبتر میکند. .
برای مطالعه بیشتر در مورد Supabase و قابلیت های RLS آن، وبلاگ ما را در زیر تحلیل کنید که نشان می دهد چگونه SSO را با Descope به Supabase اضافه کنید.
گفت ن SSO به Supabase با Descope
پیاده سازی RLS برای تولید گفت ه بازیابی (RAG)
در سیستمهای نسل گفت ه بازیابی (RAG)، مانند جستجوهای شباهت برداری در Pinecone، اسناد برای جستجو و بازیابی دقیقتر به بخشهای کوچکتر تقسیم میشوند.
در اینجا نحوه پیاده سازی RLS در این مورد استفاده آمده است:
منو را باز کنید
-- Track documents/pages/files/etc create table documents ( id bigint primary key generated always as identity, name text not null, owner_id uuid not null references auth.users (id) default auth.uid(), created_at timestamp with time zone not null default now() ); -- Store content and embedding vector for each section create table document_sections ( id bigint primary key generated always as identity, document_id bigint not null references documents (id), content text not null, embedding vector(384) );در این تنظیمات، هر سند به یک مالک_id مرتبط است که دسترسی را تعیین می کند. با فعال کردن RLS، میتوانیم دسترسی را فقط به صاحب سند محدود کنیم:
منو را باز کنید
-- Enable row level security alter table document_sections enable row level security; -- Setup RLS for select operations create policy "Users can query their own document sections" on document_sections for select to authenticated using ( document_id in ( select id from documents where (owner_id = (select auth.uid())) ) );هنگامی که RLS فعال می شود، هر پرس و جو در document_sections تنها ردیف هایی را برمی گرداند که کاربر تأیید شده فعلی مالک سند مرتبط است. این کنترل دسترسی حتی در طول جستجوهای شباهت برداری اعمال می شود:
منو را باز کنید
-- Perform inner product similarity based on a match threshold select * from document_sections where document_sections.embedding <#> embedding < -match_threshold order by document_sections.embedding <#> embedding;این تضمین میکند که جستجوی معنایی به خطمشیهای RLS احترام میگذارد، پس کاربران فقط میتوانند بخشهای سندی را که مجاز به دسترسی به آن هستند بازیابی کنند.
مدیریت اطلاعات کاربر و اسناد خارجی با بستهبندیهای داده خارجی
اگر دادههای کاربر و سند شما در یک پایگاه داده خارجی قرار دارند، پشتیبانی Supabase از خارجی دادههای Wrappers (FDW) به شما امکان میدهد در حالی که RLS را اعمال میکنید به پایگاه داده خارجی Postgres متصل شوید. این به ویژه زمانی مفید است که سیستم موجود شما مجوزهای کاربر را به صورت خارجی مدیریت کند.
در اینجا نحوه پیاده سازی RLS هنگام برخورد با منابع داده خارجی آورده شده است:
منو را باز کنید
-- Create foreign tables for external users and documents create schema external; create extension postgres_fdw with schema external; create server foreign_server foreign data wrapper postgres_fdw options (host '<db-host>', port '<db-port>', dbname '<db-name>'); create user mapping for authenticated server foreign_server options (user 'postgres', password '<user-password>'); import foreign schema public limit to (users, documents) from server foreign_server into external;هنگامی که دادههای خارجی را پیوند دادید، میتوانید خطمشیهای RLS را برای فیلتر کردن بخشهای سند بر اساس دادههای خارجی اعمال کنید:
منو را باز کنید
create table document_sections ( id bigint primary key generated always as identity, document_id bigint not null, content text not null, embedding vector(384) ); -- RLS for external data sources create policy "Users can query their own document sections" on document_sections for select to authenticated using ( document_id in ( select id from external.documents where owner_id = current_setting('app.current_user_id')::bigint ) );در این مثال، متغیر جلسه app.current_user_id در ابتدای هر درخواست تنظیم شده است. این تضمین می کند که Postgres کنترل دسترسی دقیق را بر اساس مجوزهای سیستم خارجی اعمال می کند.
چه در حال مدیریت یک رابطه کاربر-سند ساده یا یک سیستم پیچیدهتر با دادههای خارجی باشید، ترکیب RLS و FDW از Supabase راهحلی مقیاسپذیر و انعطافپذیر برای اعمال مجوز در جستجوهای مشابه برداری شما ارائه میدهد.
این کنترل دسترسی قوی را برای کاربران تضمین می کند و در عین حال عملکرد بالا را در سیستم های RAG یا سایر برنامه های مبتنی بر هوش مصنوعی حفظ می کند.
هم فیلترینگ ابرداده Pinecone و هم Supabase RLS مکانیسمهای مجوز قدرتمندی را ارائه میکنند، اما برای انواع مختلف دادهها و برنامهها مناسب هستند:
Supabase RLS : ایده آل برای داده های ساختاری و رابطه ای که در آن دسترسی باید در سطح ردیف کنترل شود، به ویژه در برنامه هایی که به مجوزهای دقیق برای رکوردهای فردی نیاز دارند (به عنوان مثال، در تنظیمات RAG). Supabase RLS با انعطاف پذیری یکپارچه سازی سیستم های خارجی از طریق بسته های اطلاعات خارجی (FDW) کنترل دقیقی را ارائه می دهد.
فیلتر فراداده Pinecone : برای داده های غیر رابطه ای و مبتنی بر برداری در سیستم های جستجو یا توصیه مناسب است. این فیلتر پویا و مبتنی بر زمینه را با استفاده از ابرداده ارائه میکند که به برنامههای مبتنی بر هوش مصنوعی اجازه میدهد تا دسترسی را به صورت انعطافپذیر و کارآمد در طول بازیابی مدیریت کنند.
چه زمانی انتخاب شود
اگر برنامه شما بر جستجوی مبتنی بر هوش مصنوعی یا سیستمهای توصیهای متمرکز است که به جستجوهای سریع و مقیاسپذیر دادههای برداری با کنترل دسترسی مبتنی بر فراداده متکی هستند، Pinecone را انتخاب کنید .
اگر نیاز به کنترل دسترسی روی ردیف های پایگاه داده جداگانه برای داده های ساختاریافته دارید، به خصوص در مواردی که مجوزهای پیچیده مورد نیاز است، Supabase را انتخاب کنید .
| ویژگی | کاج | سوپا بیس |
| مدل مجوز | فیلتر کردن متادیتا بر روی بردارها | امنیت در سطح ردیف (RLS) در ردیف های پایگاه داده |
| دامنه | فیلتر مبتنی بر برداری برای سیستم های جستجو و توصیه | کنترل دسترسی در سطح پایگاه داده برای ردیف ها و اسناد جداگانه |
| کارایی | فیلتر تک مرحله ای برای جستجوهای سریع و در مقیاس بزرگ | RLS اعمال شده توسط Postgres برای دسترسی دقیق به داده ها |
| پیچیدگی | پیاده سازی با تگ های ابرداده ساده است | به پیکربندی خط مشی ها و قوانین در Postgres نیاز دارد |
| عملکرد | برای مجموعه داده های بزرگ با زمان جستجوی سریع بهینه شده است | در صورت اعمال سیاست های پیچیده RLS، می تواند برای مجموعه داده های بزرگ کندتر باشد |
| ادغام با سیستم های خارجی | N/A | پشتیبانی از بسته های اطلاعات خارجی (FDW) برای ادغام پایگاه داده های خارجی |
| موارد استفاده ایده آل | سیستمهای جستجو و توصیه، پشتیبانی مشتری مبتنی بر هوش مصنوعی، برنامههای SaaS که دادههای غیرمرتبط یا مبتنی بر برداری را مدیریت میکنند | پلتفرم های SaaS با داده های ساختاری و رابطه ای؛ برنامه های کاربردی سازمانی که نیاز به کنترل دقیق در سطح ردیف دارند (به عنوان مثال، امور مالی، مراقبت های بهداشتی، محیط های سنگین انطباق) |
در حالی که هر دو روش نقاط قوت خود را دارند، هیچ یک به طور کامل نیازهای دسترسی به داده های پیچیده و گسترده سازمان را پوشش نمی دهد. مایکروسافت Purview برای یک راهحل گستردهتر و چند لایه، نمونهای از یکپارچهسازی عناصر هر دو رویکرد را برای مدیریت دسترسی به دادهها به طور جامع در سیستمها و انواع دادههای متعدد ارائه میکند.
Microsoft 365 Copilot and Purview: نمونه ای واقعی از مجوز ربات چت هوش مصنوعی
به داده های کاربر (منبع: Microsoft)" src="https://lh7-rt.googleusercontent.com/docsz/AD_4nXd9secLyIuizETjdw71fQZmE8ylJZmTkgyCoQQja1UrE_QKtPB0pXfGZwkC-jHH2wDwCfoEB1nANP3rAkkJYeRJU0TFj4HLeNl0omJa6OYiDS3bIDZxBo0jHB3twd1hPva4X0iuog?key=7UsKmc7gK4lrW4YzYInk4iFK" width="624" height="399"> شکل: Microsoft 365 Copilot در حال دسترسی به داده های کاربر (منبع: Microsoft)
Microsoft 365 Copilot و Purview یک سیستم چند لایه برای مدیریت دسترسی به داده ارائه میدهند که ترکیبی از فیلتر ابرداده ، کنترل دسترسی مبتنی بر هویت ، و اجرای حقوق استفاده است. این رویکرد بهطور یکپارچه با Microsoft Entra ID (Azure AD سابق) یکپارچه میشود و قوانین مجوز یکسانی را که قبلاً برای کاربران داخلی و خارجی در سراسر سرویسهای مایکروسافت پیکربندی شدهاند، اعمال میکند.
محصولات داده در Microsoft Purview: گفت ن زمینه کسب و کار به دسترسی به داده ها
یکی از آپشن های کلیدی مایکروسافت Purview استفاده از محصولات داده است که مجموعهای از داراییهای داده مرتبط (مانند جداول، فایلها و گزارشها) هستند که پیرامون موارد استفاده تجاری سازماندهی شدهاند. این محصولات داده، کشف و دسترسی به داده ها را ساده می کند، و تضمین می کند که سیاست های حاکمیتی به طور مداوم اعمال می شوند.
نقشه های داده یک نمای جامع از نحوه جریان داده ها در سازمان شما ارائه می دهند. آنها اطمینان حاصل می کنند که داده های حساس با ردیابی سازمان، مالکیت و مدیریت محصولات داده به درستی برچسب گذاری و مدیریت می شوند. برای مثال، گزارشهای مالی که با برچسب «محرمانه» مشخص شدهاند را میتوان به کارمندان مالی محدود کرد، در حالی که حسابرسان خارجی ممکن است بر اساس قوانین از پیش تنظیمشده دسترسی محدودی داشته باشند.
ادغام با Entra ID: مجوز بدون درز
Microsoft Entra ID خطمشیهای مجوز موجود را در همه سرویسهای مایکروسافت اعمال میکند. این ادغام تضمین میکند که نقشها، مجوزها و عضویتهای گروهی بهطور خودکار در سرویسهایی مانند SharePoint، Power BI و Microsoft 365 Copilot رعایت میشوند.
مجوز یکپارچه : نقشهای کارمند و مجوزهای پیکربندی شده در Entra ID تعیین میکنند که کاربر میتواند با کدام دادهها تعامل داشته باشد، و تضمین میکند که Copilot به همان قوانین پایبند است.
دسترسی کاربر خارجی : Entra ID کنترل دسترسی را برای شرکا یا فروشندگان خارجی ساده میکند و امکان همکاری ایمن را فراهم میکند و در عین حال به برچسبهای حساسیت و مجوزهای اعمال شده برای کاربران داخلی احترام میگذارد.
برچسبهای حساسیت خودکار : با استفاده از برچسبهای حساسیت، Purview بهطور خودکار حقوق رمزگذاری و استفاده را در همه محصولات داده اعمال میکند و از مدیریت امن دادهها، خواه مشاهده، استخراج یا خلاصهشده توسط Copilot اطمینان حاصل کند.
سازگاری در اکوسیستم مایکروسافت : سیاستهای حاکمیت و مجوز در تمام سرویسهای مایکروسافت ثابت میماند و از ابزارهایی مانند SharePoint، Power BI و Exchange Online محافظت یکپارچه را ارائه میدهد.
مزایای Purview و Copilot
ادغام Copilot، Purview و Entra ID، اجرای مقیاس پذیر، ایمن و خودکار سیاست های دسترسی به داده ها را در سراسر سازمان شما ارائه می دهد. چه برای کاربران داخلی و چه برای کاربران خارجی، این راهاندازی نیاز به پیکربندی دستی کنترلهای دسترسی را در هنگام استقرار سرویسهای جدید مانند رباتهای چت هوش مصنوعی حذف میکند و راهحلی کارآمد و در سطح سازمانی برای مدیریت داده ارائه میدهد.
انتخاب استراتژی مجوز مناسب برای چت ربات هوش مصنوعی
انتخاب روش مجوز مناسب برای ایجاد تعادل بین امنیت، عملکرد و قابلیت استفاده در چت رباتهای هوش مصنوعی ضروری است:
فیلتر ابرداده Pinecone : بهترین گزینه برای دادههای مبتنی بر برداری و جستجوی مبتنی بر هوش مصنوعی یا تحویل محتوای شخصیشده است. این کنترل مبتنی بر زمینه را فراهم می کند که برای داده های غیر رابطه ای ایده آل است.
امنیت در سطح ردیف (RLS) Supabase : کنترل دقیقی را بر روی رکوردهای پایگاه داده فردی ارائه می دهد و برای برنامه های SaaS که در آن کاربران به دسترسی سطح ردیف خاصی در پایگاه های داده رابطه ای نیاز دارند، عالی است.
Microsoft Enterprise Copilot : ایدهآل برای برنامههای سطح سازمانی که به دسترسی مبتنی بر هویت در انواع دادهها و سیستمهای متعدد نیاز دارند. این یک رویکرد ساختاریافته و مبتنی بر کسب و کار برای حاکمیت داده ارائه می دهد.
ترکیب راه حل های احراز هویت و مجوز
انتخاب استراتژی مجوز درست تنها نیمی از راه حل است. یکپارچه سازی یک سیستم احراز هویت قوی برای یک چت ربات هوش مصنوعی ایمن و بدون درز به همان اندازه مهم است.
استفاده از یک ارائهدهنده احراز هویت مطابق با OIDC مانند Descope، ادغام با خدمات شخص ثالث را در حین مدیریت کاربران، نقشها و کنترل دسترسی از طریق توکنهای مبتنی بر JWT ساده میکند. این تضمین میکند که توکنها میتوانند سیاستهای مجوز دقیق ذکر شده در بالا را اجرا کنند.
در اینجا مزایای ترکیب مجوز هوش مصنوعی با یک سیستم احراز هویت مدرن وجود دارد:
یکپارچه سازی بدون درز : انطباق OIDC اتصالات به سیستم های خارجی را با استفاده از پروتکل های احراز هویت استاندارد ساده می کند.
کنترل دسترسی پویا : توکنهای JWT، از سرویسهایی مانند Descope یا Supabase Auth، امکان مدیریت بلادرنگ نقشها و مجوزها را فراهم میکنند که کنترل دسترسی انعطافپذیر و ایمن را تضمین میکند.
مقیاسپذیری : ترکیبی از مدلهای مجوز انعطافپذیر (RLS یا فیلترینگ ابرداده) با یک سرویس احراز هویت قوی، ربات چت شما را قادر میسازد تا مقیاسپذیری ایمن داشته باشد و تعداد زیادی از کاربران را بدون به خطر انداختن امنیت مدیریت کند.
برای کسب اطلاعات بیشتر در مورد قابلیتهای Descope برای برنامههای هوش مصنوعی، از این صفحه دیدن کنید یا وبلاگ ما را در زیر در مورد گفت ن اعتبار به برنامه چت هوش مصنوعی Next.js با Descope تحلیل کنید.
DocsGPT: با استفاده از Next.js و OpenAI چت هوش مصنوعی با Auth بسازید
نتیجه گیری
چت ربات های هوش مصنوعی و عوامل هوش مصنوعی صنایع را متحول می کنند، اما ایمن سازی داده ها با مجوز قوی بسیار مهم است. خواه از فیلتر ابرداده، امنیت در سطح ردیف، کنترل دسترسی مبتنی بر هویت، یا ترکیبی از هر یک از آنها استفاده کنید، هر رویکرد مزایای متمایزی را برای امنیت چت بات ارائه می دهد.
با ادغام یک راه حل احراز هویت سازگار با OIDC که کاربران و نقش ها را با توکن های مبتنی بر JWT مدیریت می کند، می توانید یک سیستم چت بات مقیاس پذیر و ایمن بسازید. انتخاب ترکیبی مناسب از ابزارها، کارایی و امنیت داده ها را تضمین می کند و ربات چت شما را برای نیازهای مختلف تجاری مناسب می کند.
آیا می خواهید در مورد اعتبار و هوش مصنوعی با توسعه دهندگان همفکر چت کنید؟ به انجمن توسعه دهندگان AuthTown Descope بپیوندید تا سؤال بپرسید و در جریان باشید.
برچسبها
|
|






ارسال نظر