

MemVerge، ارائهدهنده نرمافزاری که برای تسریع و بهینهسازی برنامههای فشرده داده طراحی شده است، با Micron همکاری کرده است تا عملکرد LLM را با استفاده از فناوری Compute Express Link (CXL) افزایش دهد.
نرم افزار Memory Machine این شرکت از CXL برای کاهش زمان بیکاری در پردازنده های گرافیکی ناشی از بارگذاری حافظه استفاده می کند.
این فناوری در غرفه Micron در Nvidia GTC 2024 به نمایش گذاشته شد و چارلز فن، مدیرعامل و یکی از بنیانگذاران MemVerge گفت: «مقیاسسازی عملکرد LLM مقرونبهصرفه به معنای تغذیه پردازندههای گرافیکی با داده است. نسخه ی نمایشی ما در GTC نشان می دهد که استخرهای حافظه سطحی نه تنها عملکرد را بالاتر می برد، بلکه استفاده از منابع ارزشمند GPU را نیز به حداکثر می رساند.
نتایج چشمگیر
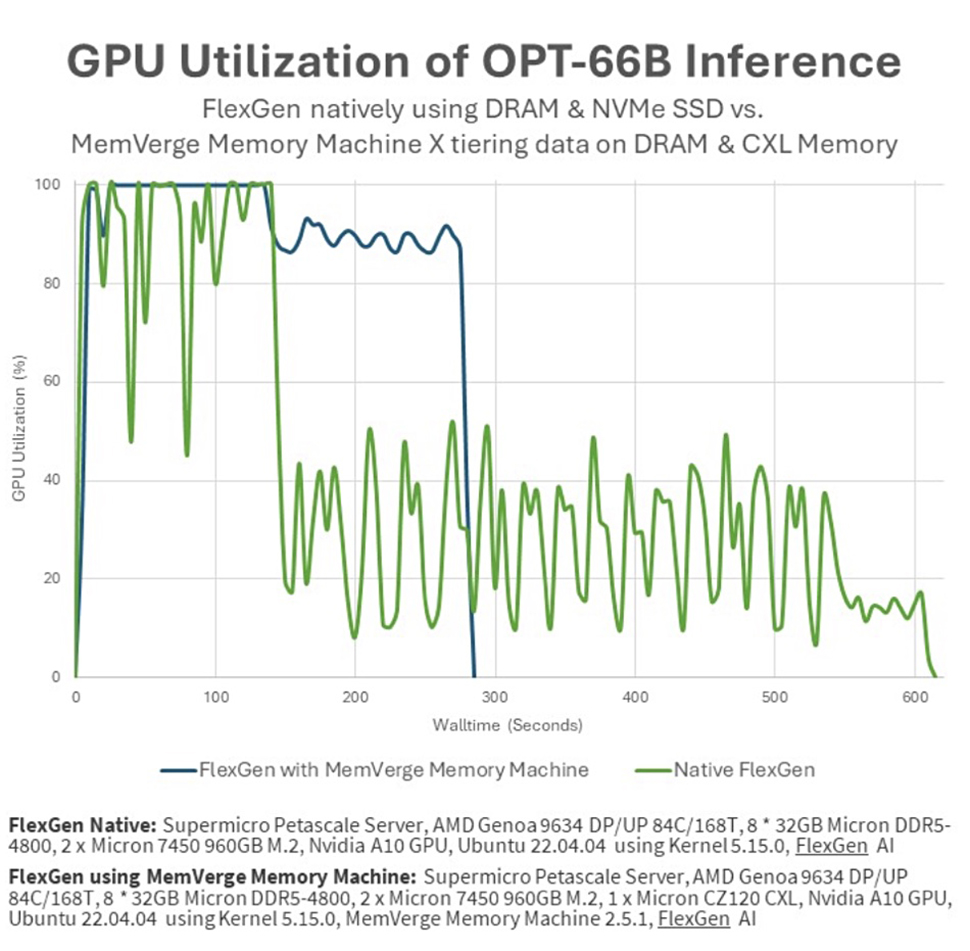
نسخه ی نمایشی از یک موتور نسل FlexGen با توان عملیاتی بالا و یک مدل زبان بزرگ OPT-66B استفاده می کرد. این کار بر روی یک سرور Supermicro Petascale مجهز به CPU AMD Genoa، پردازنده گرافیکی Nvidia A10، Micron DDR5-4800 DIMM، ماژول های حافظه CZ120 CXL و نرم افزار طبقه بندی هوشمند MemVerge Memory Machine X انجام شد.
نسخه ی نمایشی عملکرد کاری را که بر روی یک پردازنده گرافیکی A10 با حافظه 24 گیگابایتی GDDR6 و داده های تغذیه شده از 8×32 گیگابایت Micron DRAM اجرا می شود، در مقابل همان کاری که روی سرور Supermicro مجهز به توسعه دهنده حافظه Micron CZ120 CXL 24 گیگابایتی و نرم افزار MemVerge اجرا می شود، مقایسه کرد.
معیار FlexGen، با استفاده از حافظه لایهای، وظایف را در کمتر از نیمی از زمان روشهای ذخیرهسازی سنتی NVMe انجام داد. علاوه بر این، استفاده از GPU از 51.8٪ به 91.8٪ افزایش یافت که طبق گزارش ها در نتیجه لایه بندی شفاف داده های نرم افزار MemVerge Memory Machine X در حافظه GPU، CPU و CXL بود.
راج نراسیمهان، معاون ارشد و مدیر کل واحد تجاری و محاسباتی و شبکهای Micron، گفت: «از طریق همکاری با MemVerge، Micron میتواند مزایای قابل توجه ماژولهای حافظه CXL را برای بهبود توان عملیاتی GPU موثر برای برنامههای هوش مصنوعی نشان دهد و در نتیجه زمان سریعتری را برای آنها به ارمغان بیاورد. بینش برای مشتریان نوآوری های Micron در سراسر مجموعه حافظه، محاسبات را با ظرفیت حافظه و پهنای باند لازم برای مقیاس بندی موارد استفاده از هوش مصنوعی از ابر تا لبه فراهم می کند.
با این حال، کارشناسان همچنان در مورد این ادعاها تردید دارند. Blocks and Files اشاره کرد که پردازنده گرافیکی Nvidia A10 از حافظه GDDR6 استفاده می کند که HBM نیست. یکی از سخنگویان MemVerge به این نکته و دیگرانی که سایت مطرح کردند، پاسخ دادند و اظهار داشتند: «راه حل ما بر روی سایر GPU های دارای HBM تأثیر مشابهی دارد. راه حل بین قابلیتهای بارگیری حافظه Flexgen و قابلیتهای ردیفبندی حافظه Memory Machine X، مدیریت کل سلسله مراتب حافظه است که شامل ماژولهای حافظه GPU، CPU و CXL است.






ارسال نظر