چگونه پرانتزها را در جاوا اسکریپت بدون استفاده از Regex مطابقت دهیم
در حین نوشتن مترجم Lisp خود (به طور دقیق برای گویش Scheme)، تصمیم گرفتم پشتیبانی از براکتهای مربع را در نظر بگیرم. من این کار را انجام دادم زیرا برخی از کتاب های Scheme آنها را به جای پرانتز استفاده می کنند. اما من نمی خواستم تجزیه کننده را خیلی پیچیده کنم، پس تحلیل نکردم که آیا جفت براکت ها مطابقت دارند یا خیر.
در مترجم Lisp من، براکت ها را می توان به این صورت مخلوط کرد:
( let [( x 10 ]) [+ xx)]
کد بالا نمونهای از S-Expression است که در آن نشانهها، دنبالهای از کاراکترها با معنی (مانند نام let یا عدد 10 ) و براکت/پرانتز داریم. با این حال، این کد معتبر نیست زیرا جفت پرانتز و براکت را مخلوط می کند.
( let [( x 10 )] [+ xx])
این نحو Lisp مناسب است (اگر براکت ها پشتیبانی شوند)، که در آن پرانتزهای باز همیشه با پرانتز بسته شدن مطابقت دارند و براکت های باز همیشه با براکت های بسته مطابقت دارند.
در این مقاله، من به شما نشان خواهم داد که چگونه می توانید تشخیص دهید که آیا ورودی دومین S-Expression معتبر است و نه اولین S-Expression نامعتبر.
ما همچنین به مواردی مانند این رسیدگی خواهیم کرد:
( define foo 10 ))))
در کد بالا، نحو نامعتبر با بسته شدن بیشتر از باز کردن پرانتز را مشاهده می کنید.
پس به زبان ساده، تشخیص خواهیم داد که آیا جفت کاراکترهای باز و بسته مانند () ، [] و {} در داخل رشته مانند "[foo () {bar}]" مطابقت دارند یا خیر.
راهحل این مشکل میتواند هنگام پیادهسازی تجزیهکننده Lisp مفید باشد، اما میتوانید از آن برای اهداف مختلف نیز استفاده کنید (مانند نوعی اعتبارسنجی یا بخشی از یک ارزیابیکننده عبارت ریاضی). همچنین تمرین خوبی است.
بیشتر بخوانید
دانشجو هفته ها قبل از حمله سایبری نگرانی های امنیتی را در Mobile Guardian MDM مطرح کرد
توجه : برای درک این مقاله و کد، لازم نیست چیزی در مورد Lisp بدانید. اما اگر زمینه بیشتری می خواهید، می توانید این مقاله را بخوانید: Lisp and Scheme چیست ؟
جفت شدن با ساختار داده پشته
ممکن است فکر کنید که ساده ترین راه برای حل این مشکل استفاده از عبارات منظم (RegExp) است. شاید بتوان از Regex برای موارد ساده استفاده کرد، اما به زودی بیش از حد پیچیده می شود و مشکلات بیشتری نسبت به حل آن دارد.
در واقع، ساده ترین راه برای جفت کردن کاراکترهای باز و بسته، استفاده از پشته است. پشته ساده ترین ساختار داده است. ما دو عملیات اساسی داریم: فشار، برای گفت ن یک آیتم به پشته، و پاپ، برای حذف یک آیتم.
این کار به طور مشابه با مجموعه ای از کتاب ها عمل می کند. آخرین موردی که روی پشته قرار می دهید اولین موردی است که بیرون می آورید.
می توانید اطلاعات بیشتری در مورد این ساختار داده از این مقاله بخوانید:ساختارهای داده 101: پشته ها .
با یک پشته، پردازش (تجزیه) کاراکترهایی که شروع و پایان دارند، مانند تگ های XML یا پرانتزهای ساده، آسان تر است.
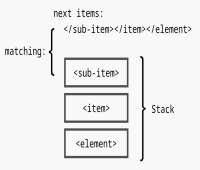
به عنوان مثال، بگویید که ما این کد XML را داریم:
< element > < item > < sub-item > text </ sub-item > </ item > </ element >
وقتی از پشته استفاده می کنیم، آخرین برچسبی که باز می کنیم (به عنوان مثال <sub-item> داخلی) همیشه اولین برچسبی است که باید ببندیم (اگر XML معتبر باشد).
پس اگر از پشته استفاده میکنیم، میتوانیم آیتم <sub-item> را هنگام باز کردن آن فشار دهیم و زمانی که نیاز به بستن آن داریم میتوانیم آن را از پشته خارج کنیم. ما فقط باید مطمئن شویم که آخرین مورد روی پشته (که همیشه تگ آغازین است) با مورد بسته شدن مطابقت دارد.
دقیقا همان منطق را با پرانتز خواهیم داشت.
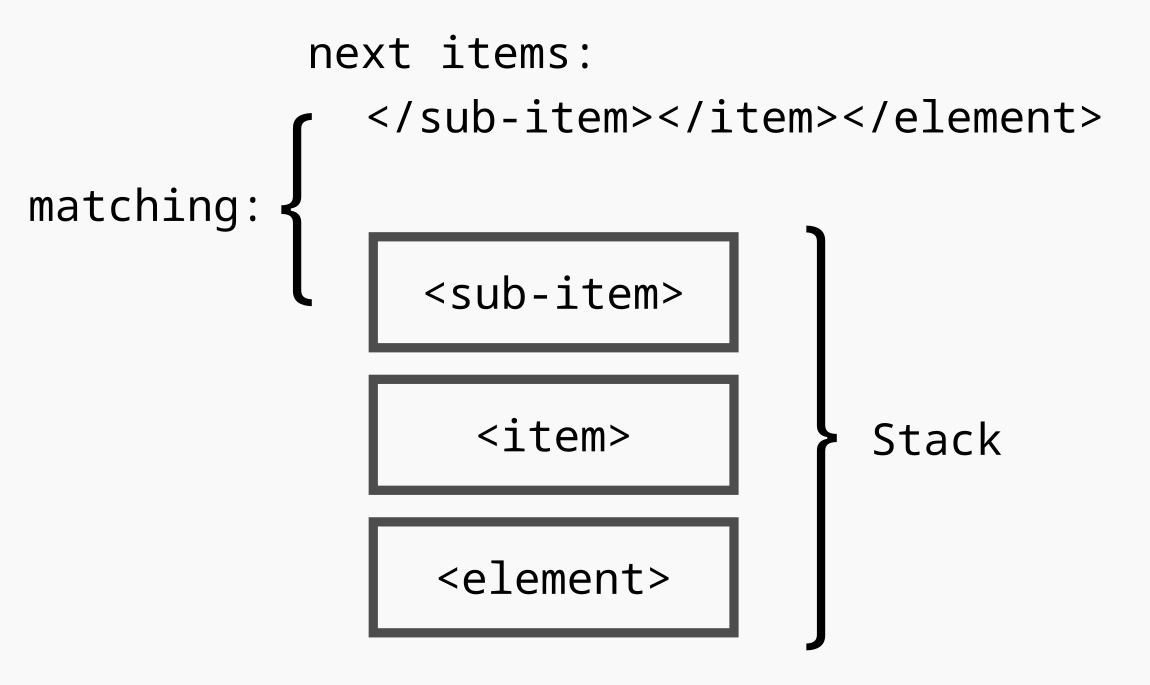 از پردازش دنباله ای از تگ های xml با یک پشته” class=”image–center mx-auto” width=”1150″ height=”685″ loading=”lazy”>
از پردازش دنباله ای از تگ های xml با یک پشته” class=”image–center mx-auto” width=”1150″ height=”685″ loading=”lazy”>
توجه داشته باشید که اگر تگ های خودبسته XML داشته باشیم، می توانیم از آنها صرف نظر کنیم زیرا باز و به طور خودکار بسته می شوند.
آرایه ها در جاوا اسکریپت دارای هر دو روش (فشار و پاپ) هستند، پس می توان از آنها به عنوان پشته استفاده کرد. اما ایجاد انتزاع در قالب یک کلاس راحتتر است، پس میتوانیم متدهای اضافی مانند top() و is_empty() را اضافه کنیم که خواندن آنها آسانتر است.
اما حتی اگر روشهای جدیدی اضافه نکردهایم، همیشه بهتر است انتزاعیهایی مانند این ایجاد کنیم، زیرا کد را سادهتر و خواناتر میکند.
اکثر توسعه دهندگان ساختارهای داده رایج را می شناسند و بلافاصله آنها را تشخیص می دهند و نیازی به فکر کردن در مورد آنها ندارند. مهمترین چیز در برنامه نویسی فراموش کردن موارد غیر مرتبط است که در هر لحظه مورد نیاز است. حافظه انسان محدود است و تنها می تواند حدود 1±4 مورد را به طور همزمان در خود نگه دارد. اطلاعات بیشتر در مورد حافظه کوتاه مدت را می توانید در ویکی پدیا بخوانید.
class Stack { #data; constructor () { // creating new empty array as hiden property this .#data = []; } push(item) { // push method just use native Array::push() // and add the item at the end of the array this .#data.push(item); } len() { // size of the Stack return this .#data.length; } top() { // sice the items are added at the end // the top of the stack is the last item return this .#data[ this .len() - 1 ]; } pop() { // pop is similar to push and use native Array::pop() // it removes and returns the last item in array return this .#data.pop(); } is_empty() { // this comment shortcut !0 is true // since 0 can is coerced to false return ! this .len(); } }
کد بالا از کلاس ES6 (ES2015) و خصوصی ES2022 استفاده می کند
خواص .
الگوریتم تطبیق پرانتز
اکنون الگوریتم (مراحل) مورد نیاز برای تجزیه پرانتزها را شرح خواهم داد.
ما به حلقهای نیاز داریم که از هر توکن عبور کند – و بهتر است تمام نشانههای دیگر قبل از پردازش حذف شوند.
هنگامی که یک پرانتز باز داریم، باید آن عنصر را به پشته فشار دهیم. هنگامی که یک پرانتز بسته داریم، باید تحلیل کنیم که آیا آخرین عنصر روی پشته با عنصری که پردازش می کنیم مطابقت دارد یا خیر.
اگر عنصر مطابقت داشته باشد، آن را از پشته حذف می کنیم. اگر نه، به این معنی است که ما پرانتزها را به هم ریخته ایم و باید یک استثنا بیندازیم.
هنگامی که یک براکت بسته داریم، اما چیزی در پشته وجود ندارد، باید یک استثنا نیز بیاندازیم، زیرا هیچ پرانتز بازکننده ای وجود ندارد که با پرانتز بسته شدن ما مطابقت داشته باشد.
پس از تحلیل همه کاراکترها (توکن ها)، اگر چیزی از پشته باقی بماند، به این معنی است که همه پرانتزها را نبستیم. اما این مورد مشکلی ندارد، زیرا ممکن است کاربر در حال نوشتن باشد. پس در این مورد، ما false برمی گردانیم، نه یک استثنا.
اگر پشته خالی باشد، true برمی گردانیم. یعنی ما یک بیان کامل داریم. اگر این یک S-Expression بود، میتوانیم از تجزیهکننده برای پردازش آن استفاده کنیم و نیازی نیست نگران نتایج نامعتبر باشیم (البته اگر تجزیهکننده درست بود).
کد منبع
function balanced ( str ) { // pairs of matching characters const maching_pairs = { '[' : ']' , '(' : ')' , '{' : '}' }; const open_tokens = Object .keys(maching_pairs); const brackets = Object .values(maching_pairs).concat(open_tokens); // we filter out what is not our matching characters const tokens = tokenize(str).filter( token => { return brackets.includes(token); }); const stack = new Stack(); for ( const token of tokens) { if (open_tokens.includes(token)) { stack.push(token); } else if (!stack.is_empty()) { // there are matching characters on the stack const last = stack.top(); // the last opening character needs to match // the closing bracket we have const closing_token = maching_pairs[last]; if (token === closing_token) { stack.pop(); } else { // the character don't match throw new Error ( `Syntax error: missing closing ${closing_token} ` ); } } else { // this case when we have closing token but no opening one, // becauase the stack is empty throw new Error ( `Syntax error: not matched closing ${token} ` ); } } return stack.is_empty(); }
کد بالا بهعنوان بخشی از تجزیهکننده S-Expression من پیادهسازی شد، اما تنها چیزی که از آن مقاله استفاده کردهام یک تابع tokenize() است که رشته را به توکنها تقسیم میکند (که در آن یک نشانه یک شی منفرد مانند شماره 123 یا یک رشته "hello" ). اگر میخواهید فقط کاراکترها را پردازش کنید، میتوانید از str.split('') استفاده کنید، پس توکنها آرایهای از کاراکترها خواهند بود.
کد بسیار ساده تر از تجزیه کننده S-Expression است زیرا ما نیازی به پردازش همه نشانه ها نداریم. اما هنگامی که از تابع tokenize() در مقاله بالا استفاده می کنیم، می توانیم ورودی را مانند این آزمایش کنیم:
( this "))))" )
کد منبع کامل (شامل تابع tokenize() ) را می توان در GitHub یافت.
خلاصه
شما حتی نباید شروع به پردازش عباراتی کنید که دارای کاراکترهای باز و بسته شونده با عبارات منظم هستند. در StackOverflow این پاسخ معروف به این سوال وجود دارد:
دیگر اخبار
یک افشای جدید ادعا می کند که پوشیدنی بعدی سامسونگ گلکسی واچ ایکس نام خواهد داشت
RegEx تگ های باز را به جز تگ های خود شامل XHTML مطابقت می دهد
تطبیق پرانتزها دقیقاً همان مشکلی را ایجاد می کند که تجزیه HTML است. همانطور که از کد بالا می بینید، اگر از پشته استفاده کنیم، حل این مشکل ساده تر است.
این امکان وجود دارد که بتوانیم یک عبارت منظم بنویسیم که تحلیل کند آیا توالی کاراکترها دارای پرانتز منطبق هستند یا خیر. اما اگر رشتههایی به عنوان نشانه (توالی کاراکترها) مانند S-Expressions داشته باشیم، به زودی پیچیده میشود و پرانتزهای داخل آن نیشها نادیده گرفته میشوند. به نظر می رسد که اگر از ابزار مناسب استفاده کنیم، راه حل نسبتاً ساده است.
من شخصاً عاشق عبارات منظم هستم، اما همیشه باید تصمیم بگیرید که آیا آنها ابزار مناسبی برای کار هستند یا خیر.
توجه : این مقاله بر اساس مقاله ای در وبلاگ لهستانی Głównie JavaScript (ang. عمدتا جاوا اسکریپت) با عنوان: Jak parować nawiasy lub inne znaki w است.
جاوا اسکریپت؟
اگر این مقاله را دوست دارید، ممکن است بخواهید من را در رسانه های اجتماعی دنبال کنید: ( Twitter/X و/یا LinkedIn ). شما همچنین می توانید وب سایت شخصی و وبلاگ جدید من را تحلیل کنید.
برچسبها
|
|






ارسال نظر