
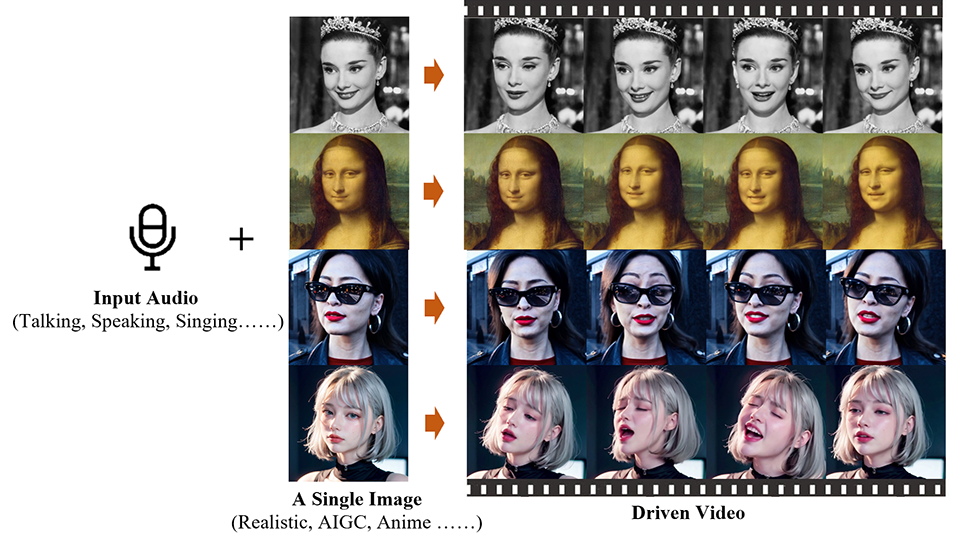
مهندسان چینی در موسسه محاسبات هوشمند، گروه علی بابا، یک اپلیکیشن هوش مصنوعی به نام Emote Portrait Live ایجاد کردهاند که میتواند یک عکس ثابت از یک چهره را متحرک کند و آن را با یک آهنگ صوتی همگامسازی کند.
فناوری پشت این متکی به قابلیتهای تولیدی مدلهای انتشار (مدلهای ریاضی که برای توصیف نحوه پخش یا انتشار اشیا در طول زمان استفاده میشود)، که میتواند مستقیماً ویدیوهای سر شخصیت را از یک تصویر ارائهشده و هر کلیپ صوتی ترکیب کند. این فرآیند نیاز به پیش پردازش پیچیده یا نمایش های میانی را دور می زند، پس ایجاد ویدیوهای سر صحبت را ساده می کند.
چالش در گرفتن تفاوت های ظریف و تنوع حرکات صورت انسان در طول سنتز ویدیو نهفته است. روشهای سنتی این کار را با اعمال محدودیتهایی بر خروجی ویدیوی نهایی، مانند استفاده از مدلهای سهبعدی برای محدود کردن نقاط کلیدی صورت یا استخراج دنبالههای حرکت سر از ویدیوهای پایه برای هدایت حرکت کلی، ساده میکنند. با این حال، این محدودیت ها ممکن است طبیعی بودن و غنای حالات صورت حاصل را محدود کند.
بدون چالش نیست
هدف تیم تحقیقاتی ایجاد یک چارچوب سر صحبت کننده است که بتواند طیف وسیعی از حالات چهره واقع گرایانه، از جمله ریز عبارات ظریف را به تصویر بکشد و امکان حرکات طبیعی سر را فراهم کند.
با این حال، ادغام صدا با مدلهای انتشار به دلیل رابطه مبهم بین صدا و حالات چهره، چالشهای خاص خود را دارد. این می تواند منجر به بی ثباتی در فیلم های تولید شده توسط مدل شود، از جمله اعوجاج صورت یا لرزش بین فریم های ویدیو. برای غلبه بر این، محققان مکانیسمهای کنترل پایدار را در مدل خود، بهویژه یک کنترلکننده سرعت و یک کنترلکننده ناحیه چهره، برای بهبود پایداری در طول فرآیند تولید، در مدل خود قرار دادند.
با وجود پتانسیل این فناوری، معایب خاصی وجود دارد. این فرآیند نسبت به روشهایی که از مدلهای انتشار استفاده نمیکنند زمانبرتر است. علاوه بر این، از آنجایی که هیچ سیگنال کنترلی صریحی برای هدایت حرکت شخصیت وجود ندارد، این مدل ممکن است ناخواسته سایر قسمتهای بدن مانند دستها را تولید کند و در نتیجه آثاری در ویدیو ایجاد شود.
این گروه مقاله ای در مورد کار خود بر روی سرور preprint arXiv منتشر کرده است، و این وب سایت میزبان تعدادی ویدیو دیگر است که امکانات Emote Portrait Live را نشان می دهد، از جمله کلیپ های خواکین فینیکس (در نقش جوکر)، لئوناردو دی کاپریو، و آدری. هپبورن
میتوانید مونولوگ مونالیزا را از شکسپیر همانطور که دوست دارید ، پرده 3، صحنه 2، در زیر میخواند، تماشا کنید.





ارسال نظر